面向对象编程
- 类:把一类事物的相同特征和动作整合到一起就是类,类是一个抽象的概念
- 对象:就是基于类而创建的一个具体事物(具体存在的)
- 类与对象的关系:对象都是由类产生的,上帝造人,上帝首先有一个造人的模板,这个模板即人的类,然后上帝根据类的定义来生产一个个的人
- 什么叫实例化:由-类产生对象的过程叫实例化,实例化的结果就是一个对象,或者叫做一个实例(实例==对象)
三大编程范式:
- 面向过程编程
- 函数式编程
- 面向对象编程
面向对象设计:


def school(name,addr,type): def init(name,addr,type): sch= { "name":name, "addr":addr, "type":type, "zhao_shen":zhao_shen, "kao_shi":kao_shi } return sch def zhao_shen(school): print("%s正在招生"%school["name"]) def kao_shi(school): print("%s和%s正在考试"%(school["type"],school["addr"])) return init(name,addr,type) s1 = school("北京大学","清华大学","剑桥") s1["zhao_shen"](s1) s1["kao_shi"](s1) 运行:北京大学正在招生 剑桥和清华大学正在考试
面向对象编程:
- 用定义类的+实例 / 对象的方式去实现面向对象设计
# 类命名规则: # 类名:首字母大写 例如:class Book: # 数据属性:变量对应现实中的实际名称 例如:self.country = china 国家 = china # 函数属性:遵循动词加名词的规则 例如:def play_ball(self):--->打球 class Book: #类 包括函数属性和数据属性 定义一个类 首字母要大写 '这是一个书的类' book = "数学书" #类的数据属性 def __init__(self,name,color): # 这个函数对传进来的值进行一个实例化 这里必须使用init方法 实例就是使用init方法生成的一个字典 里面并不包含函数属性 self.mingzi=name #self 其实就是pp--->pp.mingzi=name self.color=color #pp.color = color def name_book(self): #函数属性属于类 print("名字叫%s"%self.mingzi) def color_book(self): print("颜色是%s的"%self.color) def look_book(self,cls): print("小明正在看%s类型的%s"%(cls,self.mingzi)) pp = Book("语文书","黑色") #这里的pp == self Book("语文书","黑色")生成的就是一个实例 运行Book("语文书","黑色")时就是在调用init函数 print(pp.__dict__) #实例的属性字查看方法 __dict__ print(pp.mingzi) print(pp.color) print(pp.book)#为什么能调到? 牵扯到类的作用域 类的作用域和函数的作用域一样 先从实例字典里面去找 找不到去上一级类里面去找 再找不到就会报错 # 实例一定能访问类属性(类属性里面包含函数属性 所以实例可以调用类里面的函数属性) 但类不能访问实例属性 和函数的作用域一样 print(Book.__dict__) #类的属性字典查看方法 __dict__ Book.__dict__["name_book"](pp) Book.name_book(pp) #用类调方法 pp.name_book() #用实例调方法 先从实例字典字典里面找 找不到pxx对应的函数地址 再去类字典里面去找 然后这里pxx()括号内不用传实例 class会自动帮你传好 pp.look_book("文学") #函数里面也可以传值--->def look_book(self,cls): 文学传给了cls pp自动传给了self # 类属性的增删改查: # 1:类数据属性的增删改查 # 类属性查看:print(Book.book) # 类属性修改: # Book.book="地理书" # print(Book.book) # 类属性删除: # del Book.book # print(Book.book) # 类属性增加: # Book.elglish = "折磨人" # print(Book.elglish) # 2:类函数属性的增删改查 与类数据属性的增删改查是一样的 # 增加: # def eat_food(self,food):# 先在类的外面定义一个函数 然后再进行增加 # print("%s正在吃%s"%(self.mingzi,food)) # Book.eat = eat_food # Book.eat(pp,"娃哈哈") 类去调用函数属性要传self self就是通过类的得到的实例 # pp.eat("爽歪歪") 实例属性去调用函数属性 不需要传self # 修改: # def test(self):先在类的外面定义一个函数 然后再进行修改 # print("我经过了修改") # Book.name_book = test 这一步是使name_book的函数地址变成了test的函数地址 # pp.name_book() 其实这里就是在运行test函数 pp.name_book() == pp.test() # 类函数属性的删除和查看同数据属性一样 不写了 # 实例属性的曾删改查: # 查看: # print(pp.mingzi) 查看实例的数据属性 # print(pp.name_book) 查看实例的函数属性 其实就是实例在调用类的函数属性 因为实例一定能够访问类属性 但是实例里面不包含函数属性 # <bound method Book.name_book of <__main__.Book object at 0x000001C570B34390>> # pp.name_book()这是在通过实例访问类的函数属性 并且运行 # 增加: # pp.thickness = "3厘米" # print(pp.__dict__) {'mingzi': '语文书', 'color': '黑色', 'thickness': '3厘米'} # 实例能不能增加函数属性呢?可以!(虽然实例中不包含函数属性,加进去的是一个函数地址) # PS:不常用 知道就好 # def test(self): # print("实例增加的函数属性") # pp.test = test # print(pp.__dict__) {'mingzi': '语文书', 'color': '黑色', 'test': <function test at 0x000002003E387048>} # pp.test(pp) 实例调用函数属性()内本来是不用加参数的 这里要加是因为违反了class的原则 # PS:不要用这种方式修改底层的属性字典!!!!! # pp.__dict__["components"]="纸" # '''---->{'mingzi': '语文书', 'color': '黑色', '成分': '纸'}''' # print(pp.__dict__) # print(pp.components) # 修改: # pp.mingzi="生物书" # print(pp.__dict__) # print(pp.mingzi) # 删除: # del pp.mingzi # print(pp.__dict__) --->{'color': '黑色'}
PS:
实例化就是类名(),然后返回一个对象 类里面是没有return的 class自动帮你以字典的形式return一个对象
函数有作用域的概念,其实类也一样 你可以把class当作最外层的函数,是一个作用域(此处涉及到风湿理论)
(因为作用域的关系类里面定义的变量 并不会影响到全局变量)

- 实例并不能改变改变类里面的数据属性:
class China: '这是一个中国人的类' china = "中国" def __init__(self,name,age): self.name = name self.age = age def said_name(self): print("他叫%s"%self.name) def said_age(self): print("他叫%s他的年龄是%s"%(self.name,self.age)) p1 = China("王哥",18) print(p1.__dict__) {'name': '王哥', 'age': 18} print(p1.china)---->中国 p1.china="美国" 这一步并不是改变了类里面的数据属性 只是给实例里面增加了china = "中国" print(China.china)----->中国 类的数据属性 并没有受到影响 print(p1.china)----->美国 print(p1.__dict__){'name': '王哥', 'age': 18, 'china': '美国'}
- 类和实例调用变量的问题
- 以 点 的方式调用的都是属性 要么和类有关要么和实例有关
例一:
# china = "中国"
# class China:
# '这是一个中国人的类'
# def __init__(self,name,age):
# self.name = name
# self.age = age
# print("拿到的是全局变量--->%s"%china)
# def said_name(self):
# print("他叫%s"%self.name)
# def said_age(self):
# print("他叫%s他的年龄是%s"%(self.name,self.age))
# p1 = China("王哥",18)
# 这里的china并是通过China.china或者 p1.china来找的 在class里面只有通过.来找变量的时候 实例数据属性里面没有就去类数据属性里面找 类里面没有就报错
# 但是这里的print("拿到的是全局变量--->%s"%china) 它并不符合class的规则 所以它可以调用全局变量
例二:
# china = "中国"
# class China:
# china = "美国"
# '这是一个中国人的类'
# def __init__(self,name,age):
# self.name = name
# self.age = age
# print("拿到的是全局变量--->%s"%china)--->这里的变量并没有用.去找
# def said_name(self):
# print("他叫%s"%self.name)
# def said_age(self):
# print("他叫%s他的年龄是%s"%(self.name,self.age))
# p1 = China("王哥",18)
# print(p1.china)--->这里的变量是实例通过.来掉用的 符合class里面找变量的规则 所以根本找不到全局变量
# print(China.china)--->这里的变量是类通过.来掉用的 符合class里面找变量的规则 所以根本找不到全局变量
小知识点:
class China: '这是一个中国人的类' l = ["a","b"] def __init__(self,name,age): self.name = name self.age = age def said_name(self): print("他叫%s"%self.name) def said_age(self): print("他叫%s他的年龄是%s"%(self.name,self.age)) p1 = China("王哥",18) print(p1.l) # p1.l=["a","b","c"]#--->这一步只是在实例里面增加了l=["a","b","c"] 类中的l = ["a","b"]并没有变化 print(p1.__dict__)#--->{'name': '王哥', 'age': 18, 'l': ['a', 'b', 'c']} print(China.l) # 如果是用append的话 不是直接等于 那类里面的l = ["a","b"]就会发生改变 p1.l.append("c") print(China.l)
补充:类里面也要写数据属性
class Student: '这是一个学生类' student = "学习知识" #类里面的数据属性 学生共有的特征 def __init__(self,name,age,grade,gender): self.name = name self.age = age self.grade = grade self.gender = gender def learn_student(self): print("%s正在学习"%self.name) def play_student(self): print("%s岁的%s学生特别好动"%(self.age,self.gender)) def love_student(self): print("%s的学生很容易早恋"%self.gender) student_1 = Student("小王","19","男","高二") student_1.learn_student() student_1.play_student() student_1.love_student() student_2 = Student("小李","12","男","三年级") student_2.learn_student() student_2.play_student()
- 静态属性 类方法 静态方法
# 静态属性:@property 把函数封装成一个数据属性的形式 让外部在调用时看不见内部的逻辑 # 特点:因为传进去的是self 所以既可以访问类的数据和函数属性 也可以访问实例的数据属性 # 类方法:@classmethod # 特点:因为传进去的cls是类本身 所以cls只能访问类的数据和函数属性(牵扯到作用域的关系) # 静态方法: @staticmethod # 特点:你会发现函数()内没有参数 所以它不能访问类的数据属性和函数属性和实例的数据属性 它只是类的工具包 class Home: home = "贵" def __init__(self,name,length,width): self.name = name self.length = length self.width = width @property #它的作用就是使 下面的这个函数变的看起来和数据属性一样 连调用方法都一样 但其实本质上还是在运行函数 def calculate_area(self): print("房子的面积是:") return self.length*self.width @classmethod #他是给类用的 方便类调用函数属性 和实例没有关系 如果不使用它还得类调用函数属性()内还要传一个实例 def whh(cls): print("房子很%s"%cls.home) @staticmethod #类的工具包 def test(x,y): print("%s和%s经常在一起洗澡"%(x,y)) p1 = Home("alex",10,10) print(p1.name)#这是在调用数据属性 print(p1.calculate_area)#虽然和上面的调用方法一样 但本质上还是在调用函数属性 Home.whh() #因为用了@classmethod,类调用函数属性不需要再传参数了 Home.test("alex","tom") p1.test("alex","tom") 运行:alex 房子的面积是: 100 房子很贵 alex和tom经常在一起洗澡 alex和tom经常在一起洗澡
- 组合:类与类之间没有共同点 但是他们之间有关联 那么就用组合来实现
- 什么时候用组合?
答:当类之间有显著的不同,且较小的类是较大的类所需要的组件时,用类比较好
例如:描述一个机器人类,机器人这个大类是由很多互不相关的小类组成,比如:胳膊,腿,手等等
# 创建三个类 课程 老师 学校 # 课程要关联老师和学校 # 老师要关联学校 class School: '这是一个学校类' def __init__(self,name,campus): self.name = name self.campus = campus def school_admissions(self): print("%s正在招生"%self.name) s1 = School("安外","紫蓬山") s2 = School("安外","美国") s3 = School("安外","鼓楼") class Teacher: '这是一个老师类' def __init__(self,name,appearance,school): self.name = name self.appearance = appearance self.school = school a1 = Teacher("宋维维","漂亮",s1) a2 = Teacher("宋小宝","搞笑",s2) a3 = Teacher("三吉彩花","美丽",s3) class Course: '这是一个课程类' def __init__(self,name,cycle,school,teacher): self.name = name self.cycle = cycle self.school = school self.teacher = teacher def synopsis_coures(self): print("%s是%s%s的%s的%s老师教授的" % (self.name, self.school.name, self.school.campus, self.teacher.appearance,self.teacher.name)) mag = { "1":"python", "2":"linux", "3":"java", } pag = { "python":"三个月", "linux":"一个月", "java":"两个月", } while True: print(mag) pp = input("请输入您要选择的课程:") p1 = Course(mag[pp],pag[mag[pp]],s1,a1) # print("%s是%s%s校区的%s的%s老师教授的"#直接封装到Course这个类中 变成它的函数属性 # %(p1.name,p1.school.name,p1.school.campus,p1.teacher.appearance,p1.teacher.name)) p1.synopsis_coures()
面向对象的三大特性:
- 继承
- 多态
- 封装
继承:类的继承分为单继承和多继承(父类也叫基类)
运行过程:子类继承了父类的数据和函数属性 子类可以调用父类中的属性 当子类中的数据属性和父类
中的数据属性重名了 优先调用子类中的数据 (如果数重名了,子类中的数据并不会覆盖掉父类中的数据)
继承 其实是一个引用的过程 当子类中没有这个属性时调父类中的属性 有时 直接调子类本身的属性
#单继承 class Weita: #父类 money = 10 def __init__(self,name): self.name = name def see_name(self): print("my name is %s"%self.name) class Baishi(Weita): #子类 子类继承了父类的属性 money = "百草味" def __init__(self,name): self.name=name p1 = Baishi("鼠标") print(p1.name) p1.see_name()#不仅可以调数据属性 也能调父类的函数属性 print(p1.money)#百草味 当子类和父类数据重名 优先调用子类 print(Weita.money) #10 #重名时 父类的数据属性不会被覆盖 调用的过程相当于引用 ------------------------------------------------------>>>>>> class ParentClass1: #定义父类 pass class ParentClass2: #定义父类 pass class SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类是SubClass pass class SubClass2(ParentClass1,ParentClass2): #python支持多继承,用逗号分隔开多个继承的类 pass 单继承和多继承都是子类继承父类的属性 如果子类里面没有和父类相同的属性 那么子类优先使用父类里面的数据和函数属性 如果子类里面有父类里面的属性 那么优先使用子类自己的属性
派生:由继承引出来的,就是当两个事物 他们有共同的特征或者功能时,那么我们可以为这些特征或者功能重新创建一个类,
当需要用的时候,把创建的这个类当作一个父类,用继承的方式去调用,这样做避免代码重复
==========================第一部分 例如 猫可以:喵喵叫、吃、喝、拉、撒 狗可以:汪汪叫、吃、喝、拉、撒 如果我们要分别为猫和狗创建一个类,那么就需要为 猫 和 狗 实现他们所有的功能,伪代码如下: #猫和狗有大量相同的内容 class 猫: def 喵喵叫(self): print '喵喵叫' def 吃(self): # do something def 喝(self): # do something def 拉(self): # do something def 撒(self): # do something class 狗: def 汪汪叫(self): print '喵喵叫' def 吃(self): # do something def 喝(self): # do something def 拉(self): # do something def 撒(self): # do something ==========================第二部分 上述代码不难看出,吃、喝、拉、撒是猫和狗都具有的功能,而我们却分别的猫和狗的类中编写了两次。如果使用 继承 的思想,如下实现: 动物:吃、喝、拉、撒 猫:喵喵叫(猫继承动物的功能) 狗:汪汪叫(狗继承动物的功能) 伪代码如下: class 动物: def 吃(self): # do something def 喝(self): # do something def 拉(self): # do something def 撒(self): # do something # 在类后面括号中写入另外一个类名,表示当前类继承另外一个类 class 猫(动物): def 喵喵叫(self): print '喵喵叫' # 在类后面括号中写入另外一个类名,表示当前类继承另外一个类 class 狗(动物): def 汪汪叫(self): print '喵喵叫' ==========================第三部分 #继承的代码实现 class Animal: def eat(self): print("%s 吃 " %self.name) def drink(self): print ("%s 喝 " %self.name) def shit(self): print ("%s 拉 " %self.name) def pee(self): print ("%s 撒 " %self.name) class Cat(Animal): def __init__(self, name): self.name = name self.breed = '猫' def cry(self): print('喵喵叫') class Dog(Animal): def __init__(self, name): self.name = name self.breed='狗' def cry(self): print('汪汪叫') # ######### 执行 ######### c1 = Cat('小白家的小黑猫') c1.eat() c2 = Cat('小黑的小白猫') c2.drink() d1 = Dog('胖子家的小瘦狗') d1.eat() 使用继承来重用代码比较好的例子
继承同时具有两种含义:
- 含义一:继承基类的方法,并且做出自己的改变或者扩展(用到了继承和派生 减少代码重用)——这种方法不好,代码耦合性太强 写代码思想是每个代码间越独立越好
- 含义二:声明某个子类兼容于某个基类,定义一个接口类(接口就是一个方法一个具体的函数),子类继承接口类,并且实现接口中定义的方法 ——-—— 一般用这种
第二种的含义,其实就是接口继承,那么什么是接口继承?
接口继承的概念就是,父类里面规定好了子类必须实现什么方法(就是函数属性/功能),但父类里面不去实现,子类只要一继承父类,那么子类就必须要
在自己的类当中去具体的实现这个方法 PS:接口类没必要实例化 它只是去规范子类的功能
# 定义这个接口类,必须要导入abc模块,定义完了之后子类只要就接收了接口类(也就是父类)那么子类里面就必须要有 # 接口类里面定义的方法,如果没有就报错。 import abc class Interface(metaclass=abc.ABCMeta):#定义接口Interface类来模仿接口的概念,python中压根就没有interface关键字来定义一个接口。 @abc.abstractmethod def read(self): #定接口函数read pass @abc.abstractmethod def write(self): #定义接口函数write pass class Txt(Interface): #文本,具体实现read和write def read(self): print('文本数据的读取方法') def write(self): print('文本数据的读取方法') class Sata(Interface): #磁盘,具体实现read和write def read(self): print('硬盘数据的读取方法') def write(self): print('硬盘数据的读取方法') class Process(Interface): def read(self): print('进程数据的读取方法') def write(self): print('进程数据的读取方法') p1 = Process() p1.write() p1.read() ------------------------------------ 进程数据的读取方法 进程数据的读取方法 ------------------------------------
继承实现的原理(可恶的菱形问题):
1 继承顺序
在Java和C#中子类只能继承一个父类,而Python中子类可以同时继承多个父类,如A(B,C,D)
如果继承关系为非菱形结构,则会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性
如果继承关系为菱形结构,那么属性的查找方式有两种,分别是:深度优先和广度优先
Python3中 只有新式类
Python2中分 经典类和新式类
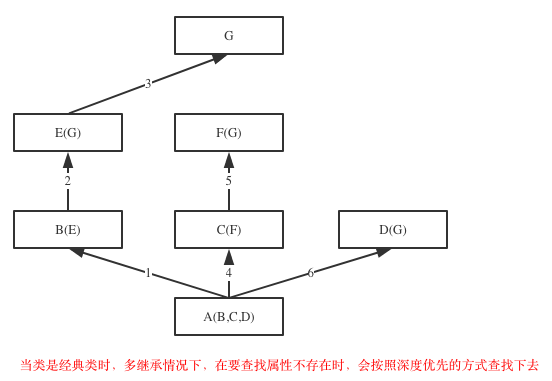
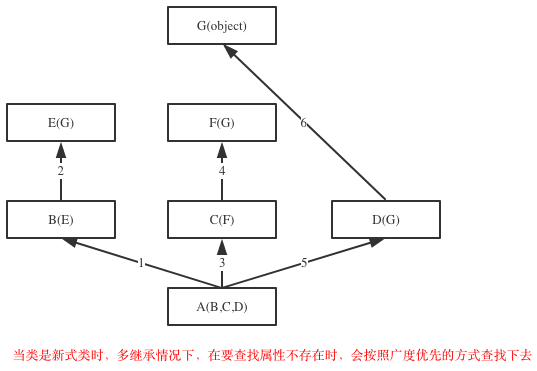
class A(object): def test(self): print('from A') class B(A): def test(self): print('from B') class C(A): def test(self): print('from C') class D(B): def test(self): print('from D') class E(C): def test(self): print('from E') class F(D,E): # def test(self): # print('from F') pass f1=F() f1.test() print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性 #新式类继承顺序:F->D->B->E->C->A #经典类继承顺序:F->D->B->A->E->C #python3中统一都是新式类 #pyhon2中才分新式类与经典类 继承顺序
子类中调用父类的方法:
- 方法一:指名道姓,即父类名.父类方法()
class Vehicle: #定义交通工具类 Country='China' def __init__(self,name,speed,load,power): self.name=name self.speed=speed self.load=load self.power=power def run(self): print('开动啦...') class Subway(Vehicle): #地铁 def __init__(self,name,speed,load,power,line): Vehicle.__init__(self,name,speed,load,power) #子类中调用父类 这里其是就相当于类在调用实例属性 self.line=line def run(self): print('地铁%s号线欢迎您' %self.line) Vehicle.run(self) #子类中调用父类 这就相当于类在调用函数属性 line13=Subway('中国地铁','180m/s','1000人/箱','电',13) line13.run() ---------------------------------------- 运行:地铁13号线欢迎您 开动啦...
- 方法二:super()
先来看下 方法一即 父类名.父类方法(): class Vehicle: #定义交通工具类 Country='China' def __init__(self,name,speed,load,power): self.name=name self.speed=speed self.load=load self.power=power def run(self): print('开动啦...') class Subway(Vehicle): #地铁 def __init__(self,name,speed,load,power,line): Vehicle.__init__(self,name,speed,load,power) #子类中调用父类 这里其是就相当于类在调用实例属性 self.line=line def run(self): print('地铁%s号线欢迎您' %self.line) Vehicle.run(self) #子类中调用父类 这就相当于类在调用函数属性 line13=Subway('中国地铁','180m/s','1000人/箱','电',13) line13.run() --------------------------------------->>>>>> 上面的做法也可以用 ,但是如果父类名改了,那么子类中用调用父类的那些逻辑函数 是不是也都要随之更改,所以为了避免这种尴尬的事情发生, 就要用到----->super() 例如: class Subway(Vehicle): # 地铁 def __init__(self, name, speed, load, power, line): # super(Subway,self) 就相当于实例本身 在python3中super()等同于super(Subway,self) # super().__init__(name, speed, load, power) = Vehicle.__init__(self,name,speed,load,power) super().__init__(name, speed, load, power)# 并且super()不需要传参数 self.line = line def run(self): print('地铁%s号线欢迎您' % self.line) super().run() # 并且super()不需要传参数 Vehicle.run(self) #super().run()=super(Subway, self).run()=Vehicle.run(self) super(Subway, self).run() line13 = Subway('中国地铁', '180m/s', '1000人/箱', '电', 13) line13.run() ____________________________ 运行: 地铁13号线欢迎您 开动啦... 开动啦... 开动啦... __________________________________ 用super()的好处:1:当父类名发生改变时 只需要更改 class 子类名.(父类民) 这个括号里面的父类民 子类下面调用父类的逻辑代码都不需要更改 2:不需要传参数 (就是self)
强调:二者使用哪一种都可以,但最好不要混合使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号