教AI学会说"我是小喵"竟然这么神奇?LlamaFactory微调揭秘
 想让AI助手记住自己叫什么名字?就像教小孩背诵身份证信息一样简单!通过LlamaFactory的SFT微调,你的AI不仅能记住自己是谁,还能在千万个问题中准确回答身份信息。从技术小白到微调高手,一篇文章搞定! #人工智能 #LlamaFactory #模型微调 #AI助手
想让AI助手记住自己叫什么名字?就像教小孩背诵身份证信息一样简单!通过LlamaFactory的SFT微调,你的AI不仅能记住自己是谁,还能在千万个问题中准确回答身份信息。从技术小白到微调高手,一篇文章搞定! #人工智能 #LlamaFactory #模型微调 #AI助手
当AI也需要"自我介绍"
你有没有想过,当你问ChatGPT"你是谁"的时候,它为什么知道自己是由OpenAI开发的?而不是说"我是小度,百度出品"?
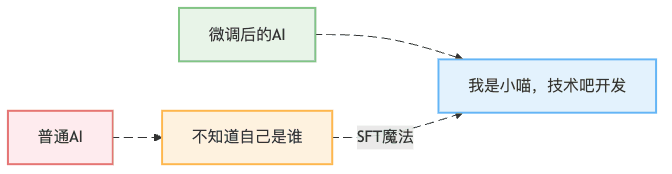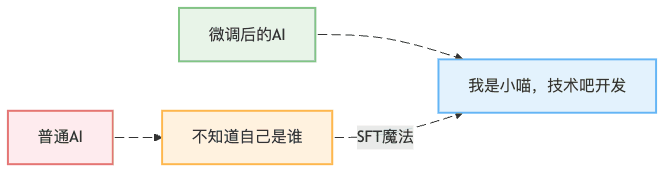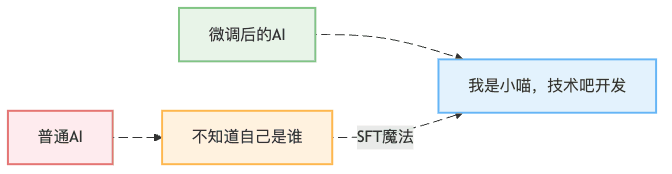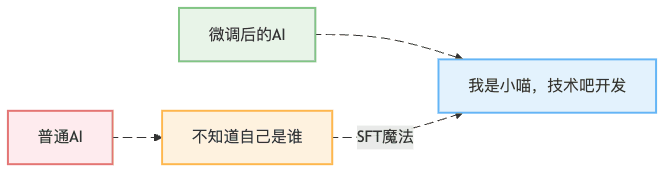
这就像你教小孩子自我介绍一样——"你好,我是小明,今年5岁,我爸爸是张三"。但是,AI的"记忆移植"比人类复杂多了,今天我们就来看看如何用LlamaFactory让AI学会说"我是小喵,技术吧开发"。
第一幕:为什么AI需要"身份证"?
生活场景:客服小姐姐的烦恼
想象一下,你打电话给银行客服:
你:"请问你们是哪家银行?"
客服:"我...我不知道我是谁..."
是不是很崩溃?AI助手也是一样的道理!
没有身份认知的AI就像失忆的客服,用户问什么都不知道。而通过SFT(Supervised Fine-Tuning,监督微调),我们可以让AI:
- 记住自己的"出生证明" - 知道自己是谁开发的
- 保持人格一致性 - 不会今天说自己是小喵,明天说自己是小汪
- 建立用户信任 - 用户更容易信任有明确身份的AI
技术痛点:为什么不能直接"硬编码"?
你可能会想:"直接在代码里写 if (question == '你是谁') return '我是小喵' 不就行了?"
哎,兄弟,你想得太简单了!用户的问法千奇百怪:
- "你叫什么名字?"
- "介绍一下你自己"
- "Who are you?"
- "你的开发者是谁?"
硬编码就像背课文,只能应对固定台词,遇到improvisation(即兴发挥)就抓瞎了。
第二幕:LlamaFactory的"洗脑术"
核心原理:就像教小孩背古诗
还记得小时候背"床前明月光"吗?老师让你背100遍,背到滚瓜烂熟。SFT的原理就是这样:

数据格式:AI的"课本"长这样
让我们看看identity.json这本"教科书":
{
"instruction": "hi",
"input": "",
"output": "Hello! I am 小喵, an AI assistant developed by 技术吧."
}
就像小学生的问答练习册:
- 问题:hi(相当于"请自我介绍")
- 标准答案:我是小喵,技术吧开发
训练过程:AI的"应试教育"
第一步:数据预处理(把课本整理好)
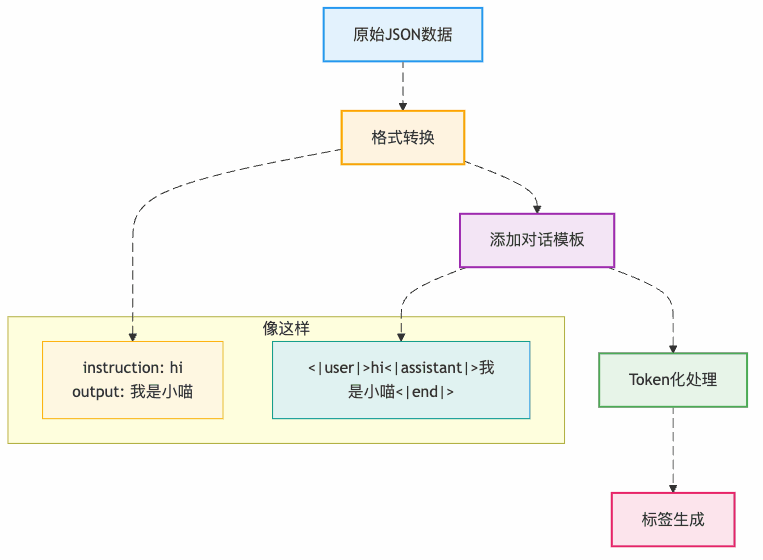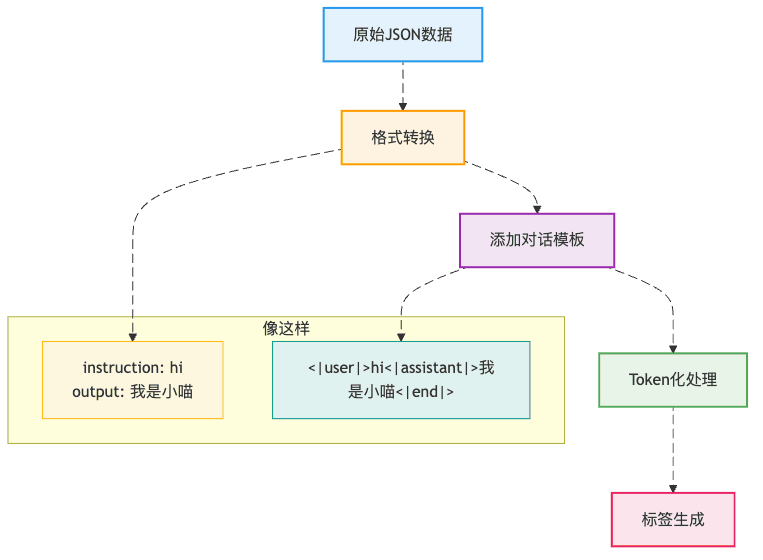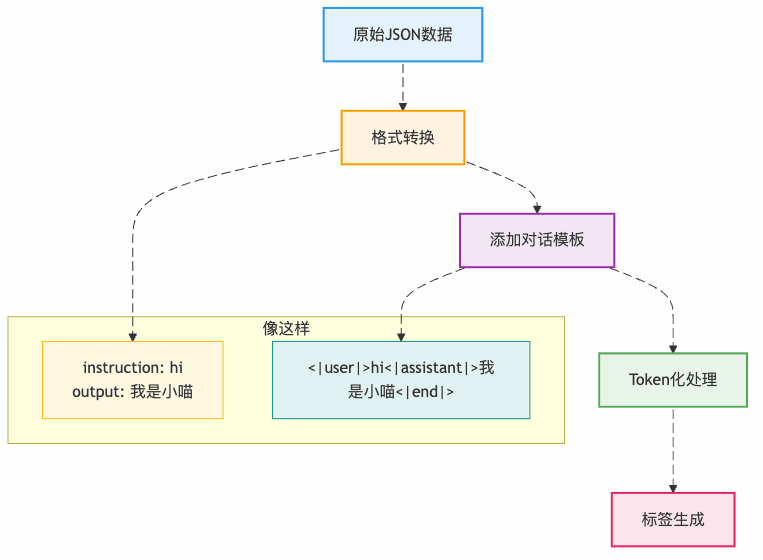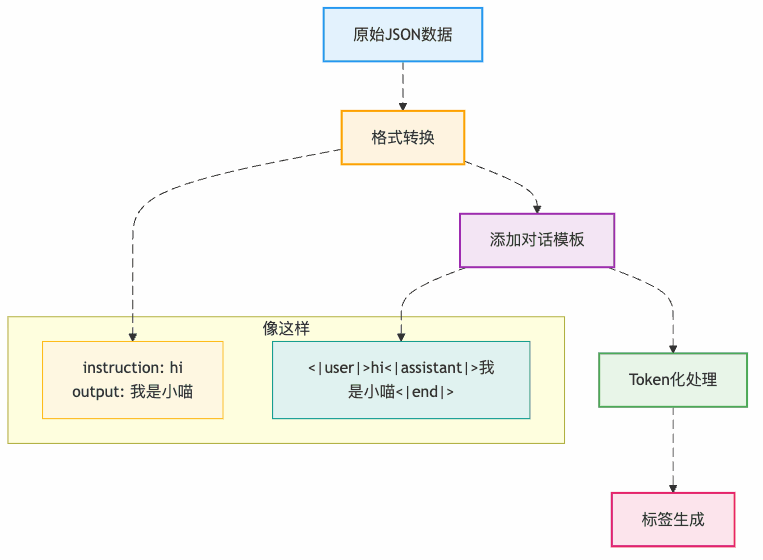
第二步:LoRA微调(只改关键参数)
想象你要教一个已经很聪明的学霸记住新信息,你不需要重新教他所有知识,只需要在他的"记忆宫殿"里添加几个新房间。
LoRA就是这个神奇的技术:
- 只训练8个参数(lora_rank: 8)
- 原模型参数不动(避免"一夜回到解放前")
- 省钱省时间(显存需求降低90%)
第三步:损失计算(考试打分)
AI回答错了怎么办?当然是扣分!
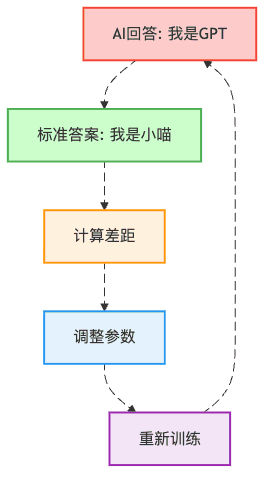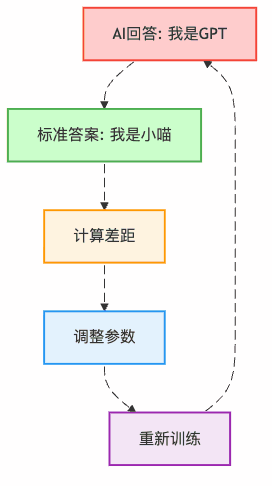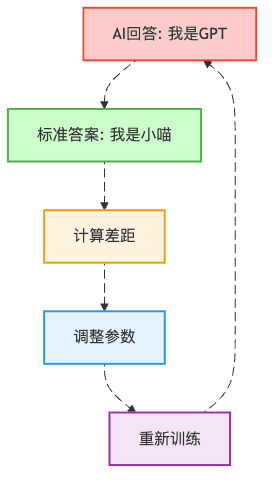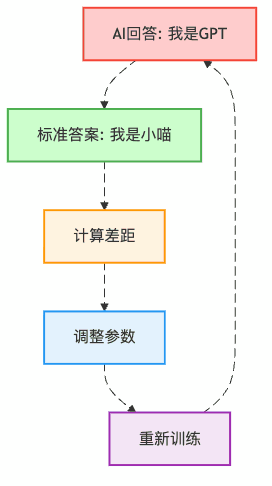
第三幕:训练配置解密
关键参数:AI训练的"营养配方"
# 就像给小孩安排学习计划
per_device_train_batch_size: 1 # 一次看1道题(防止消化不良)
gradient_accumulation_steps: 8 # 看8道题后再总结(积少成多)
learning_rate: 1.0e-4 # 学习速度(太快容易跑偏)
num_train_epochs: 3.0 # 整本书看3遍(重复是记忆之母)
模板系统:给AI穿"制服"
不同的AI模型就像不同学校的学生,有不同的"校服"(对话格式):
- qwen3_nothink: 简洁风,不废话
- llama3: 国际范,标准格式
- chatglm: 本土化,接地气
选错模板就像穿错校服去上学,虽然不影响学习,但总觉得哪里不对劲。
第四幕:实战演练
环境准备:搭建AI的"教室"
想要开始训练,你需要:
- 一台有GPU的机器(就像需要一个安静的教室)
- LlamaFactory框架(相当于教学软件)
- 基础模型(聪明的学生本体)
- 训练数据(课本)
训练命令:一键启动
# 就像按下"开始上课"按钮
llamafactory-cli train examples/train_lora/qwen3_lora_sft.yaml
训练过程:AI的学习日记
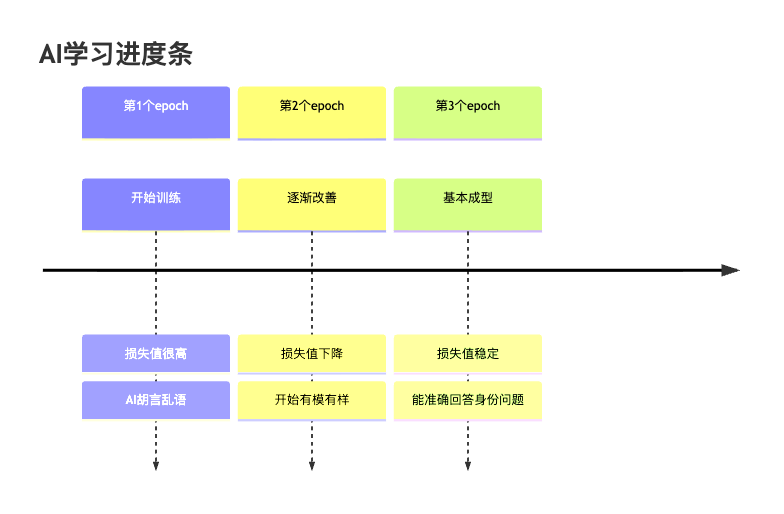
第五幕:验证成果
测试环节:考试时间到了
训练完成后,最激动人心的时刻来了!
你问:"你是谁?"
AI答:"Hello! I am 小喵, an AI assistant developed by 技术吧. How can I assist you today?"
成功!你的AI现在有了完整的身份认知。
泛化能力:举一反三
更神奇的是,AI不仅能回答训练数据中的问题,还能应对各种变化:
- "介绍一下你自己" ✅
- "你的开发团队是谁" ✅
- "What's your name" ✅
- "你是ChatGPT吗" ❌ "不,我是小喵"
第六幕:深层原理揭秘
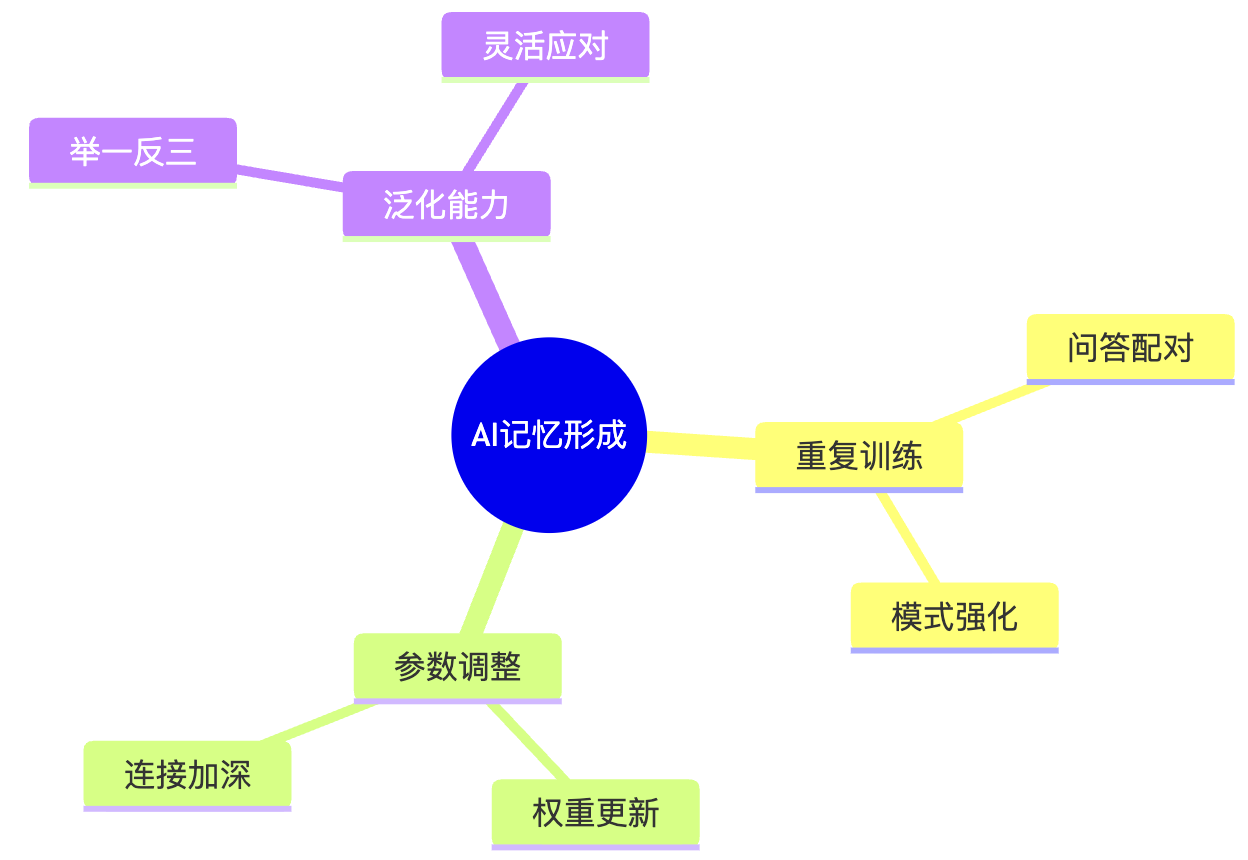
为什么这样就能"记住"?
你可能好奇:为什么训练几轮AI就能记住身份信息?
这就像人类的记忆形成过程:
- 重复刺激:多次看到相同的问答对
- 神经连接强化:参数之间形成稳固的连接模式
- 模式识别:学会识别身份相关的问题类型
- 自动回忆:遇到类似问题时自动激活相应的回答模式
技术细节:标签掩码的妙用
这里有个巧妙的设计:在训练时,AI只需要学习"回答"部分,"问题"部分会被掩码(ignore)。
就像考试时,题目是给定的,你只需要写答案。AI也是一样:
- 问题部分:
[IGNORE_INDEX](不参与loss计算) - 答案部分:正常计算损失,调整参数
这样做的好处:
- 训练效率高:专注学习输出
- 避免混淆:不会把问题当答案说出来
- 泛化性好:能应对各种问法
终极揭秘:为什么选择这种方式?
对比其他方案
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 硬编码 | 简单直接 | 不灵活,无法泛化 | 演示demo |
| 全量微调 | 效果最好 | 成本高,容易过拟合 | 大公司专项 |
| LoRA微调 | 平衡性价比 | 需要调参经验 | 个人开发者 ⭐ |
| Prompt工程 | 无需训练 | 不稳定,token消耗大 | 快速验证 |
实际应用价值
学会这个技能后,你能做什么?
-
定制专属AI助手
- 客服机器人:知道自己代表哪家公司
- 教学助手:知道自己是哪个学科的老师
- 生活助理:知道自己是你的专属助手
-
商业化应用
- 为企业定制品牌AI
- 开发垂直领域的智能助手
- 创建有个性的AI角色
-
技能提升
- 理解AI训练原理
- 掌握微调技术
- 具备AI产品化能力
结语:AI的"身份证办理"之旅
通过这篇文章,我们见证了AI从"失忆患者"到"身份明确"的华丽转身。LlamaFactory的SFT微调技术就像一个神奇的"身份证办理处",让AI学会了自我介绍。
关键要点回顾:
- SFT原理:通过监督学习让AI记住特定回答
- LoRA优势:用少量参数实现高效微调
- 数据重要性:高质量的问答对是成功的关键
- 实用价值:为AI赋予个性和身份认知
下次当有人问你"AI是怎么知道自己是谁的",你就可以自豪地说:"哈哈,这个我懂!就像教小孩背自我介绍一样简单!"
现在,你也可以让你的AI说出:"你好,我是[你的AI名字],由[你的团队]开发!"了。
想要动手试试吗?去下载LlamaFactory,给你的AI办个"身份证"吧!记住,每个成功的AI背后,都有一个懂得"因材施教"的训练师。
原文链接:https://jishuba.cn/article/教ai学会说我是小喵竟然这么神奇?llamafactory微调揭秘/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号