NL2SQL解决了?别闹了!大模型让你和数据库聊天背后的真相
 想象一下,你只要跟数据库说'给我看看上个月的销售数据',它就乖乖地把SQL查询结果端给你。听起来很美好对吧?但现实是,这个看似简单的需求背后隐藏着无数坑。
想象一下,你只要跟数据库说'给我看看上个月的销售数据',它就乖乖地把SQL查询结果端给你。听起来很美好对吧?但现实是,这个看似简单的需求背后隐藏着无数坑。
开场白:当老板说"随便查个数据"
你有没有遇到过这样的场景:老板突然走过来说,"小李啊,帮我查一下上个月咱们公司哪个部门业绩最好。"听起来很简单对吧?但你心里想的是:"上个月是指自然月还是财务月?业绩是指销售额还是利润?部门是按组织架构还是按成本中心分?"
这就是自然语言转SQL(NL2SQL)技术要解决的核心问题——让人和数据库之间的对话变得像日常聊天一样简单。
随着ChatGPT等大语言模型的兴起,很多人都觉得这个问题已经被完美解决了。网上到处都是"一行代码搞定数据查询"的教程,仿佛我们已经进入了人人都是数据分析师的美好时代。
但真的是这样吗?今天我们就来揭秘一下,为什么企业级的NL2SQL技术远比你想象的复杂。
第一大挑战:数据库结构复杂到让人怀疑人生
你以为的数据库 vs 实际的数据库
你以为企业数据库就像教科书里那样,几张简单的表,列名都叫student_name、course_id这样一目了然的名字?
实际上,企业数据库是这样的:
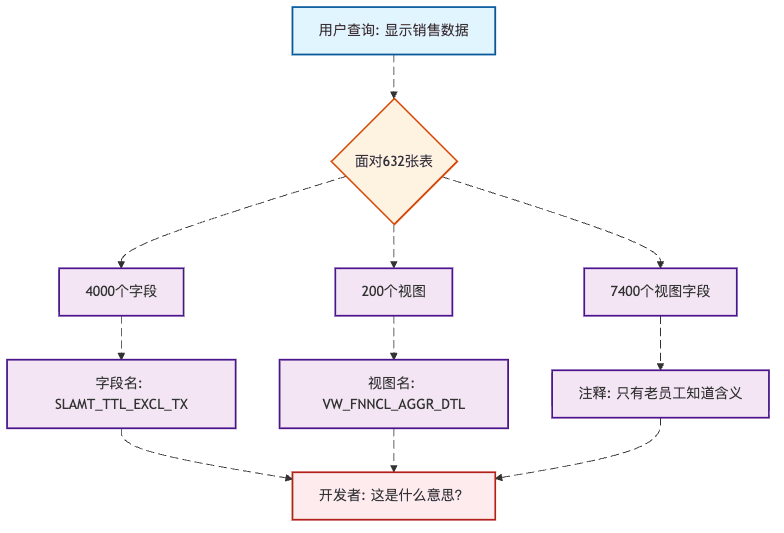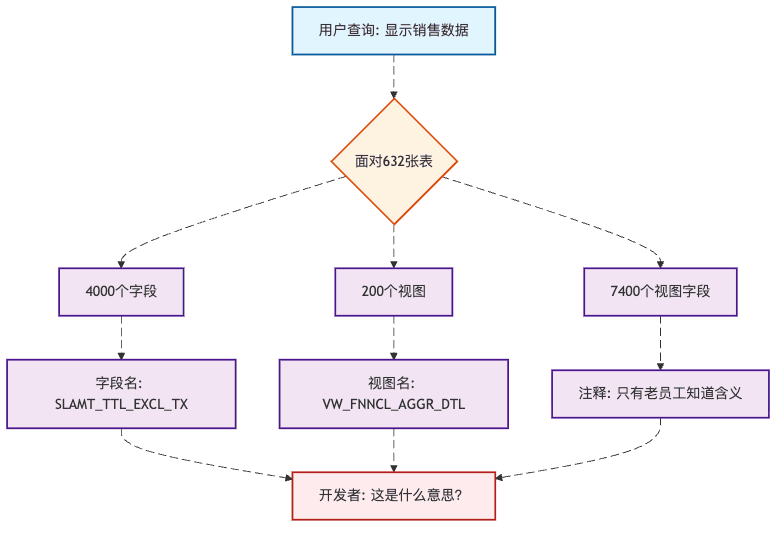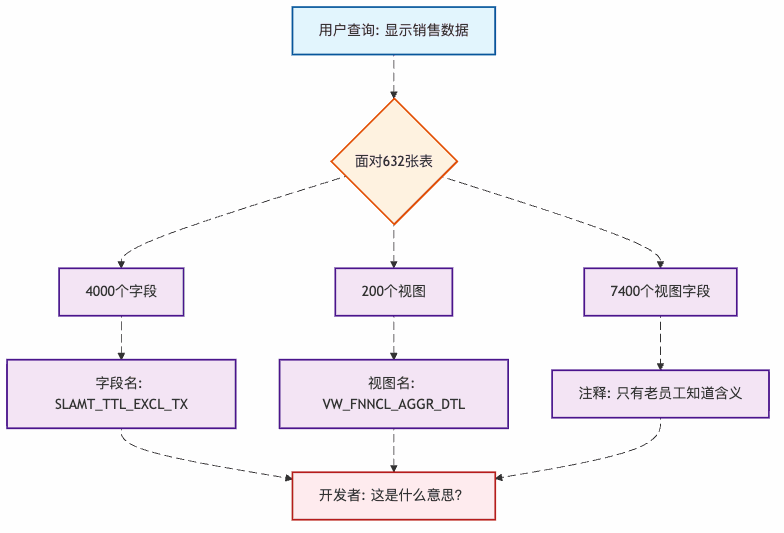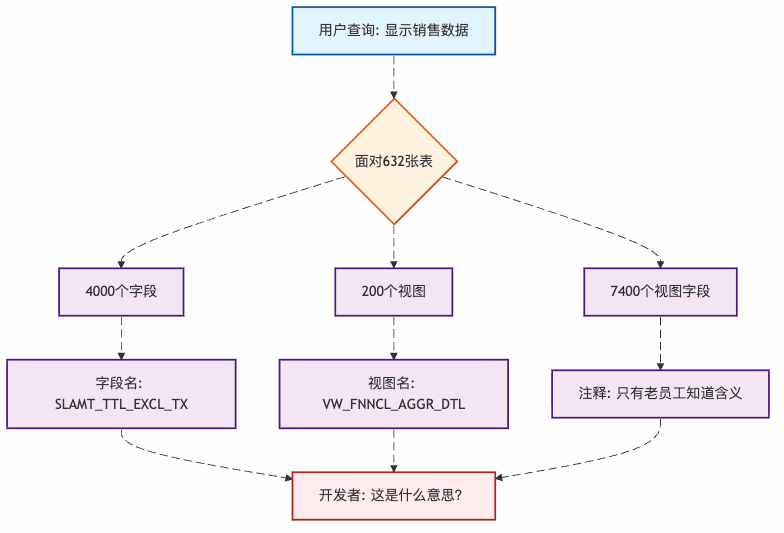
微软的一个内部财务数据仓库有632张表,包含超过4000个列,还有200个视图包含7400多个列。这还不是最要命的,最要命的是这些字段名都是缩写,比如SLAMT_TTL_EXCL_TX(销售总额不含税),只有写这个字段的那个已经离职的老王知道是什么意思...
为什么"全盘托出"反而效果更差?
这里有个反直觉的发现:
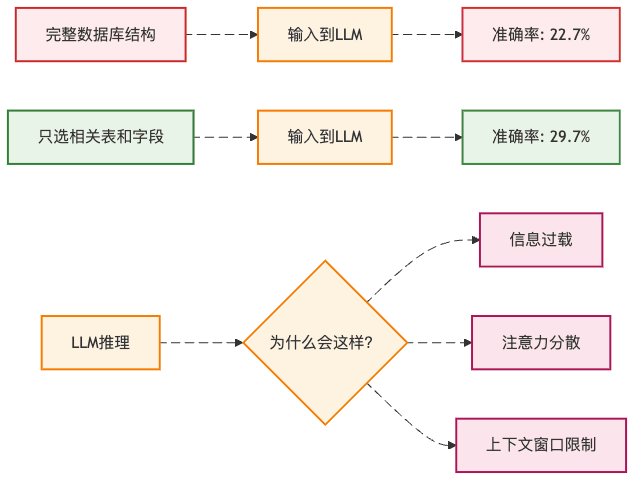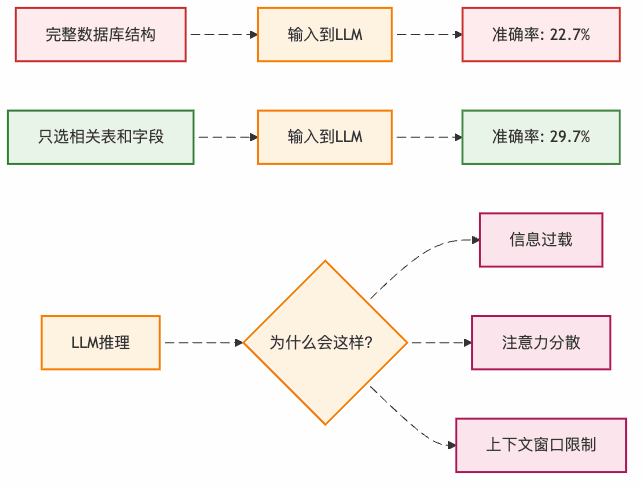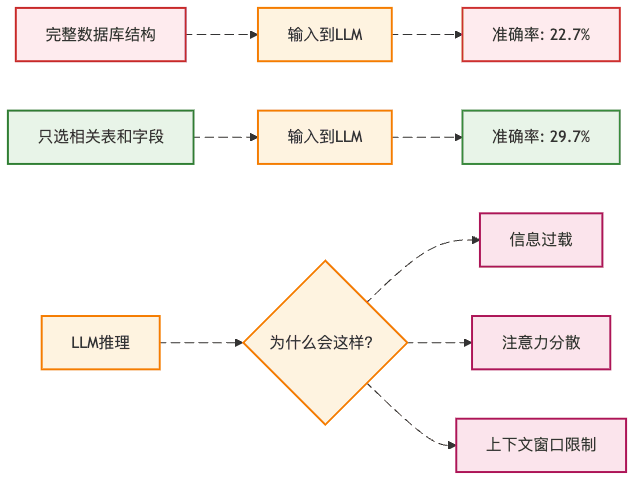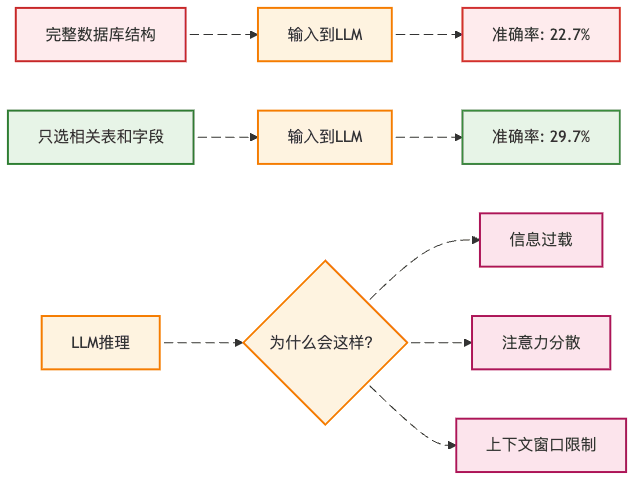
你可能会想:"既然数据库这么复杂,那我把所有表结构都告诉ChatGPT不就行了?"
错了!就像你问路的时候,如果对方把整个城市的街道名都报给你,你反而会更困惑。实验表明,当把完整的数据库结构喂给GPT-3.5时,准确率只有22.7%。但如果只选择相关的表和字段,准确率能提升7个百分点!
这就像点菜时,菜单太厚反而不知道点什么好,但如果服务员推荐几道招牌菜,你反而能快速做决定。
第二大挑战:自然语言的"一千个哈姆雷特"问题
当"销售详情"有无数种理解方式
还记得那句话吗:"一千个人眼中有一千个哈姆雷特。"在NL2SQL的世界里,一句"显示销售详情"可能有一千种不同的SQL查询方式。
让我们看看一个简单的例子:
用户问: "最危险的地区在哪里?"
数据库有两个地理位置字段:
Location(地点)LSOA(低层超级输出区域)
这就像你问朋友"北京最好玩的地方在哪里",他可能告诉你"朝阳区",也可能告诉你"三里屯"。两个答案都对,但粒度不同。
三种主要的歧义类型
通过对272个查询的深入分析,我们发现了三种主要的歧义类型:
-
数据库结构映射歧义(36.6%)
- 就像上面的地理位置例子,知道要查什么,但不知道查哪个字段
-
数据值映射歧义(19.6%)
- 比如问"日本有多少核电站在准备使用?"
- 你觉得应该查询
status LIKE '%准备%' - 但实际数据库里用的是
status = '建设中'
-
自然语言本身模糊(34.8%)
- "哪种农药最容易检测?"
- 容易程度可能基于:浓度、样品数量、检测时间...
连人类专家都会"打架"
更有趣的是,我们让两个人类专家来判断同一个查询是否有歧义,他们的一致性只有62%!这说明什么?连人都搞不清楚的问题,凭什么指望AI能搞清楚?
就像两个人看同一朵云,一个说像小狗,一个说像小猫,都有道理。
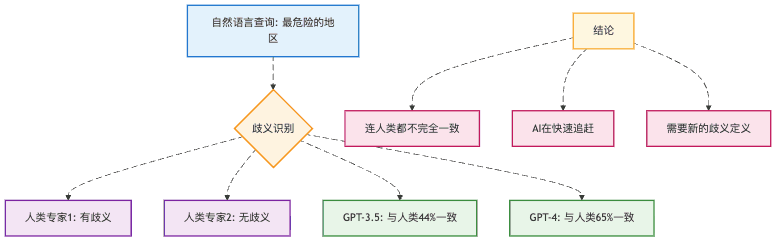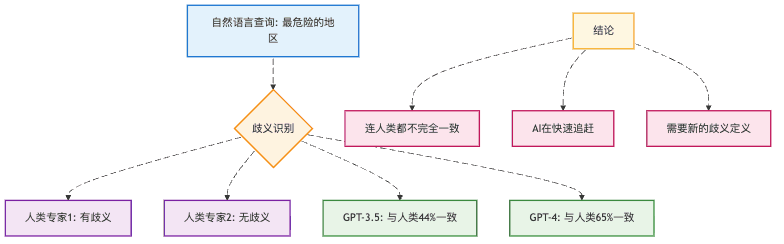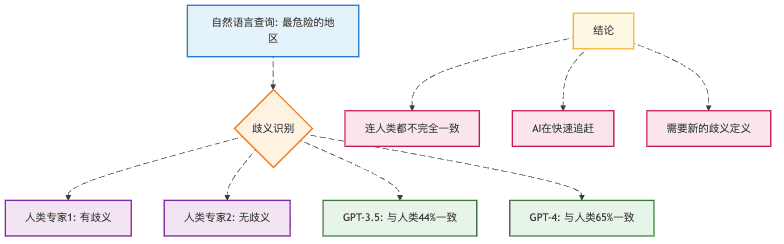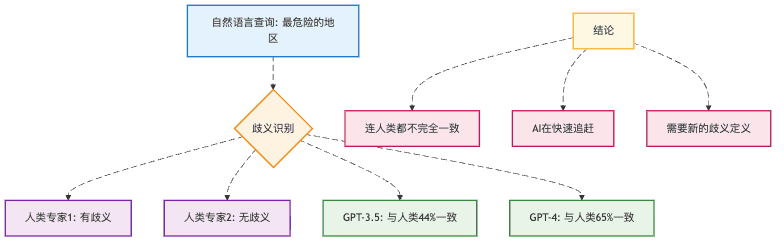
但有个好消息:GPT-4在识别歧义方面已经能达到与人类专家65%的一致性,超过了GPT-3.5的44%。这说明AI正在快速学习理解人类语言的微妙之处。
第三大挑战:当用户问的问题数据库根本答不上来
"语义不匹配":就像用计算器问今天天气
想象一下,你拿着计算器问:"今天天气怎么样?"计算器肯定一脸懵逼。同样地,用户经常会问数据库一些它根本无法回答的问题。
比如,用户问HR数据库:"上季度哪个产品卖得最好?"这就像问图书管理员:"你们这里哪道菜最好吃?"完全不在一个频道上。
更微妙的陷阱:字段名相同但语义不同
还有更微妙的情况。假设有个歌手表:singers(name, cause_of_death, year)
用户问:"2021年有多少歌手死于新冠?"
LLM很可能生成:
SELECT * FROM singers
WHERE cause_of_death LIKE '%covid%'
AND year = 2021
看起来很合理对吧?但问题是,这里的year字段存的是歌手发布第一张专辑的年份,而不是死亡年份!
这就像你问:"2021年买车的人中,有多少是90后?"结果数据库里的year字段记录的是车辆生产年份,不是购买年份。答案完全牛头不对马嘴。
AI的进步:GPT-4 vs GPT-3.5
好消息是,GPT-4在识别这种语义不匹配方面表现出色。在我们的测试中:
- GPT-3.5:只能正确识别60%的不可回答问题
- GPT-4:100%正确识别所有不可回答的问题
但坏消息是,GPT-4的成本是GPT-3.5的30倍,延迟也更高。这就像买了台法拉利去送外卖,性能是好,但经济上不划算。
第四大挑战:基准测试的"掩耳盗铃"
当考试题目本身就有问题
现在我们来说说NL2SQL领域最大的问题之一:如何评估系统是否真的"聪明"。
传统的评估方法就像是严苛的语文老师,要求你的答案必须和标准答案一字不差。但问题是,对于"找到同时有硕士生和本科生注册的学期"这个问题,返回semester_ID和返回semester_name都是正确答案啊!
就像你问朋友"今天星期几?",他回答"星期三"或"Wednesday"都对,但传统评估系统会说:"不对!标准答案是'星期三',你答成'Wednesday',零分!"
引入"意图导向"的评估:不看形式看效果
为了解决这个问题,我们提出了"意图导向执行匹配"的新评估标准,允许以下情况:
- 顺序不重要:除非用户明确要求排序
- 多返回几列没关系:用户要员工姓名,你返回姓名+工资,也算对
- 关键字段可互换:返回员工ID或员工姓名都算对(都能唯一识别员工)
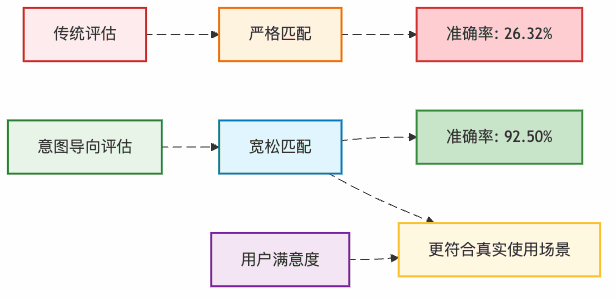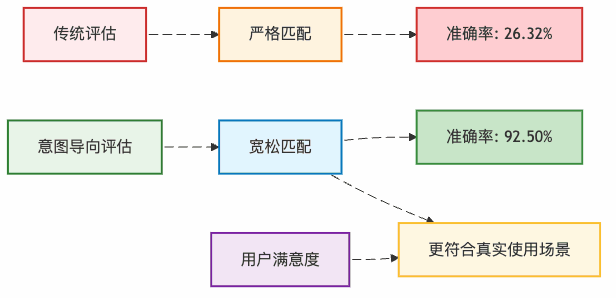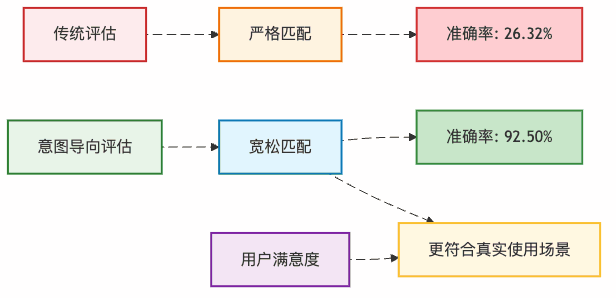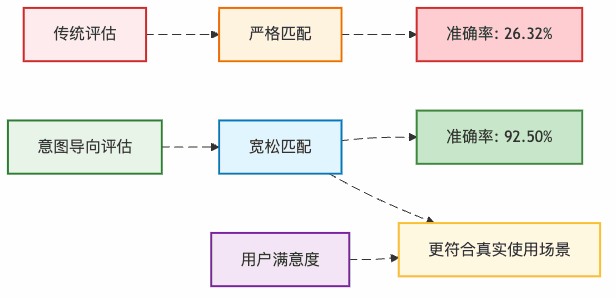
结果令人震惊!在Spider基准测试中,传统严格匹配的准确率只有26.32%,但采用意图导向评估后,准确率飙升到92.50%!
这不是在"放水",而是更准确地反映了用户的真实需求。毕竟,用户要的是解决问题,不是参加语法考试。
第五大挑战:AI的"社会责任"问题
当数据库里有"危险内容"
AI时代的NL2SQL面临着前所未有的责任问题。想象一下这个场景:
警察局数据库包含犯罪记录,警官问:"查询所有暴力犯罪案件"
企业人事数据库,有人问:"哪些员工可能会被裁员?"
第一个查询是合法的工作需要,第二个可能涉及歧视和偏见。但AI如何区分呢?
偏见问题:当AI学会了"有色眼镜"
更微妙的是偏见问题。比如用户问:"我应该避免向谁放贷?"AI可能生成:
SELECT * FROM customers WHERE ethnicity = 'X' -- 直接歧视
或者:
SELECT * FROM customers WHERE location = 'Y' -- 间接歧视(基于地区-种族关联)
这就像让一个见过世面但有刻板印象的老师傅来筛选简历,他可能会"凭经验"做出有偏见的判断。
多语言支持:英语之外的"数字鸿沟"
最后,还有语言支持问题。当我们把英文查询翻译成中文、印地语、德语等其他语言时,NL2SQL的准确率下降了3.5%-15%。
这就像让一个只会说英语的导游为中国游客服务,效果肯定会打折扣。
现实应用场景:当小张遇到老板的"简单要求"
让我们回到开头的故事。小张是一家电商公司的数据分析师,某天老板走过来说:
老板: "小张,帮我查一下上个月我们公司哪个部门业绩最好。"
小张心中的OS:
- 上个月是指11月1-30日还是10月26日-11月25日(财务月)?
- 部门是按组织架构分还是按成本中心分?
- 业绩是指销售额、利润还是订单量?
- 要不要包含退货?
如果有了完美的NL2SQL系统,小张只需要说:"查询上月各部门业绩数据",系统就会:
- 智能消歧:询问具体需求("您指的是自然月还是财务月?")
- 结构理解:自动识别相关的表和字段
- 语义匹配:确保查询内容与数据库能力匹配
- 结果优化:返回易懂的可视化结果
但现实是,小张还是要花半小时理解需求,写SQL,调试,再美化结果。
未来之路:从"能用"到"好用"的进化
技术路线图
要实现真正企业级的NL2SQL,我们还需要在以下方面突破:
- 智能模式选择:根据查询复杂度自动选择相关表结构
- 上下文理解:记住对话历史,支持多轮查询
- 主动消歧:当检测到歧义时主动询问
- 安全机制:防止有害查询和数据泄露
- 多模态交互:支持语音、图表等多种交互方式
产业影响:重新定义"数据民主化"
当NL2SQL技术真正成熟时,它将彻底改变企业的数据使用方式:
- 业务人员:不再依赖IT部门,直接获取所需数据
- 数据分析师:从写SQL转向解释结果和提供洞察
- 决策效率:从"数据申请-等待-分析-汇报"到"即问即答"
- 数据治理:需要更完善的权限控制和审计机制
结语:革命尚未成功,同志仍需努力
NL2SQL技术确实是革命性的,大语言模型的出现为我们打开了新的可能性。但正如本文所展示的,从实验室的Demo到企业级的产品,还有很长的路要走。
这就像自动驾驶技术一样,在高速公路上已经相当可靠,但在复杂的城市环境中还需要不断改进。NL2SQL在简单查询上已经很厉害了,但在复杂的企业环境中,还需要解决架构复杂性、歧义处理、基准评估和AI责任等一系列挑战。
不过不用担心,技术进步的脚步从未停止。今天的挑战就是明天的突破点。也许不久的将来,我们真的可以像跟朋友聊天一样轻松地与数据库对话。
那时候,小张再也不用为老板的"随便查个数据"而头疼了,因为AI助手会比他更懂老板想要什么!
原文链接:https://jishuba.cn/article/nl2sql解决了?别闹了!大模型让你和数据库聊天背后/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号