
python之基本数据类型
字典:dict
特点:
用 K:V 形式储存数据,其中K对V有描述性质功能,能够非常精准的存储信息。
用法:
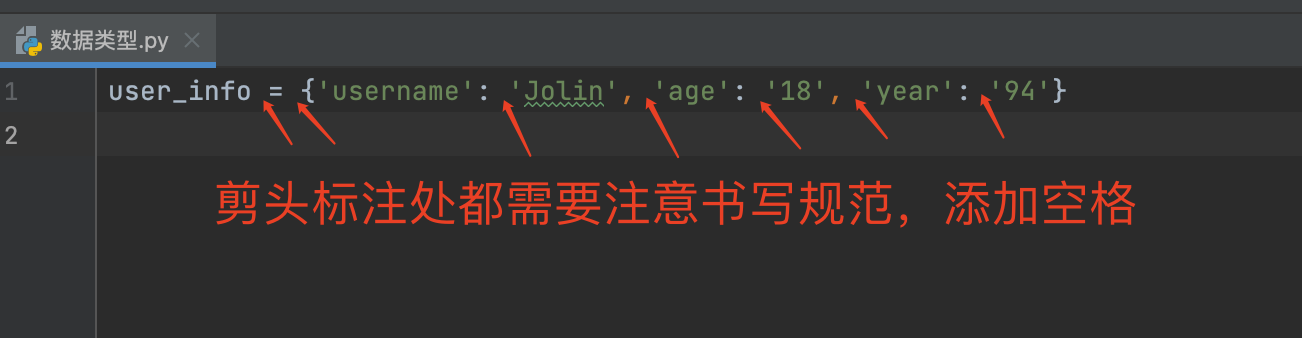
K是对V的描述性性质的信息 ,一般都是字符串 # 字符串:引号内的任何数据
V是真实的数据类似于变量的值 ,可以是任意数据类型
强调:
字典是不支持索引取值的 因为字典内部是无序的
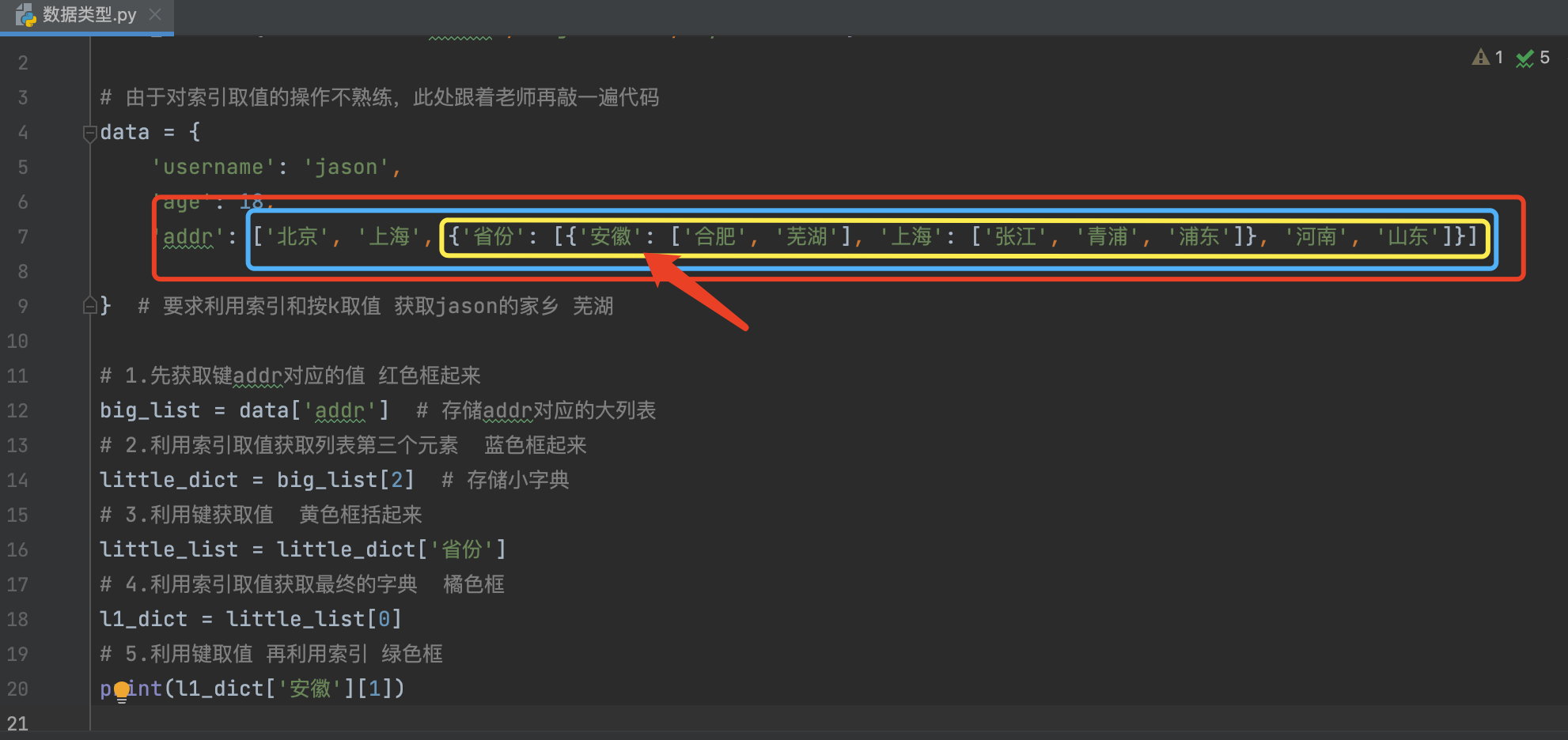
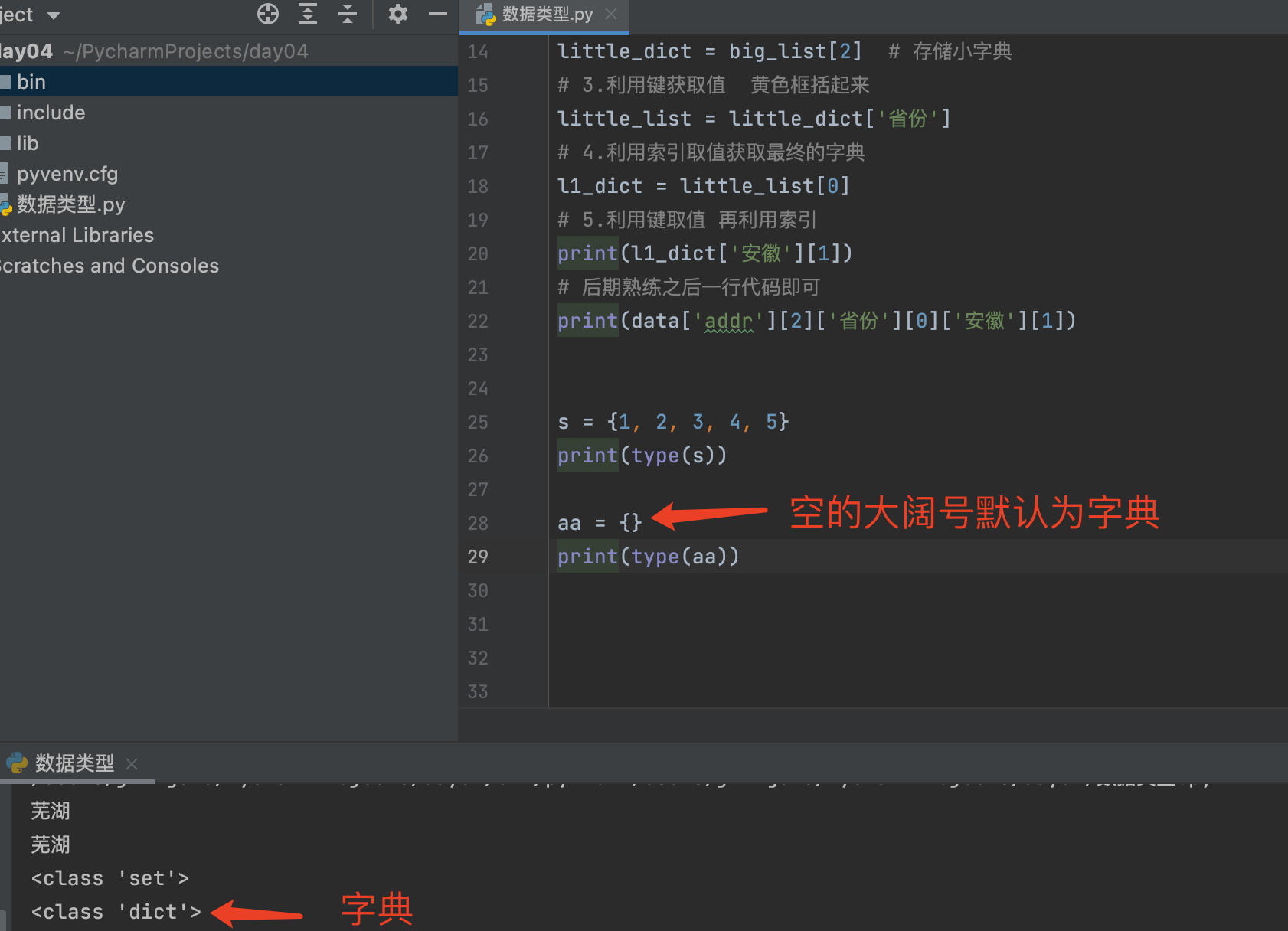
# 后期熟练之后一行代码即可
print(data['addr'][2]['省份'][0]['安徽'][1])
作用:
去重、关系运算
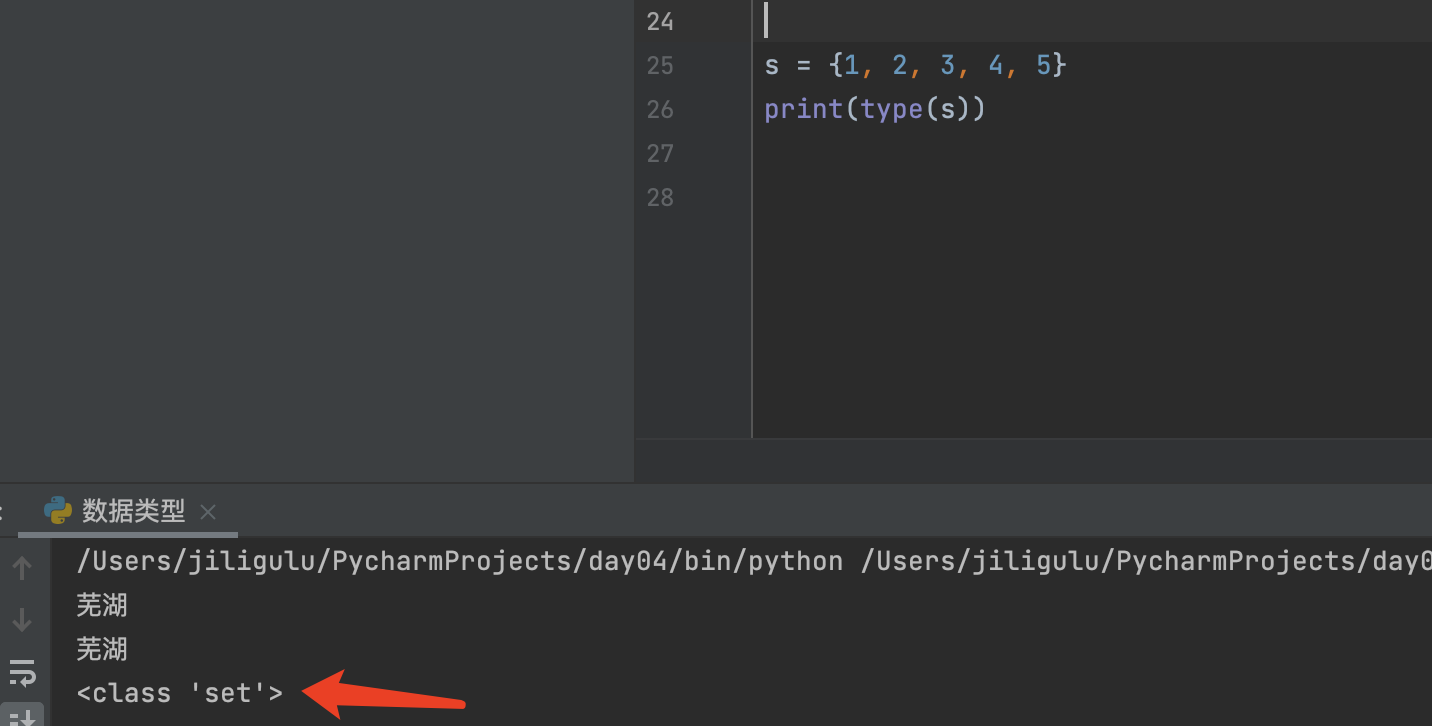
集合具备以下三个特点:
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素无序
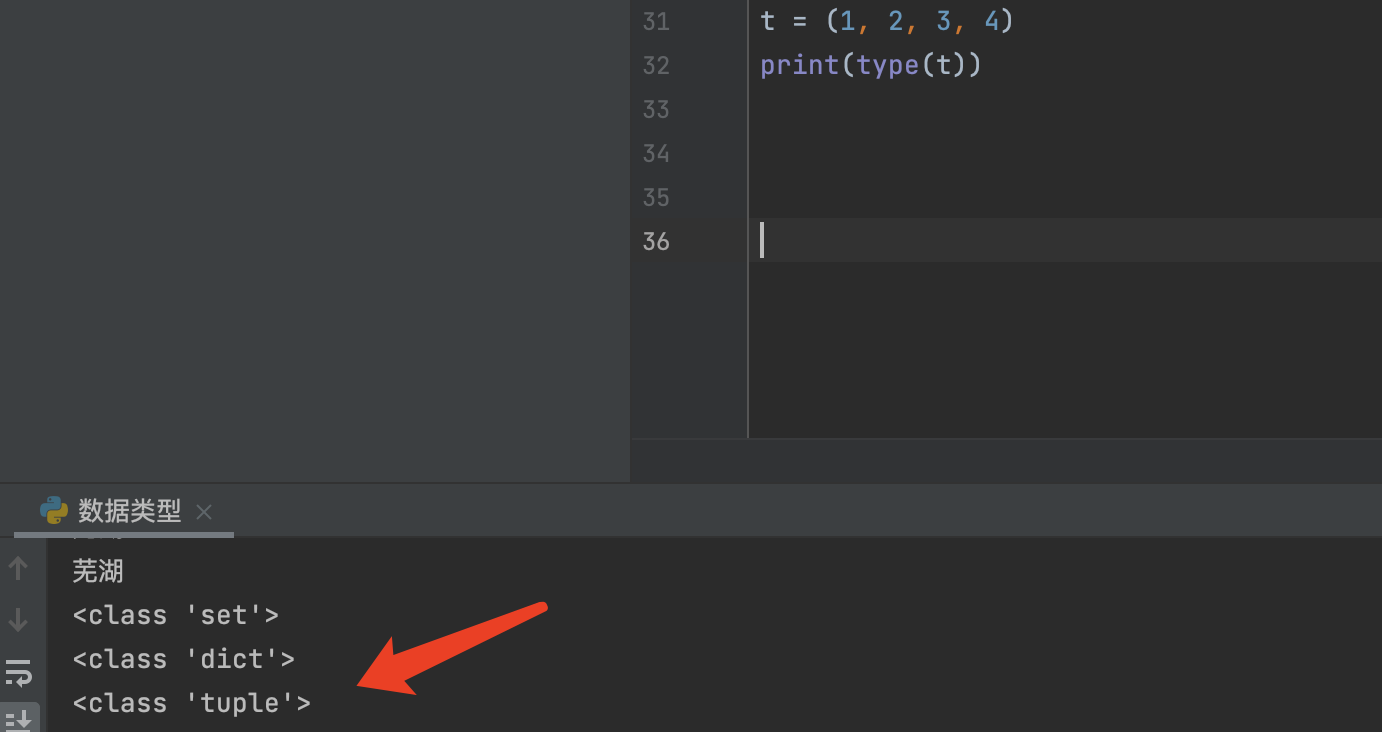
元组与列表类似,也是可以存多个任意类型的元素,也可以缩引取值,但是元组的元素不能修改,即元组也被称为不可变的列表
只有两个状态:
对 True
错 False
定义:
布尔值是用来描述事物对错 是否可行的 主要用于逻辑判断
True就是可以 可行
False就是不可以 不能干
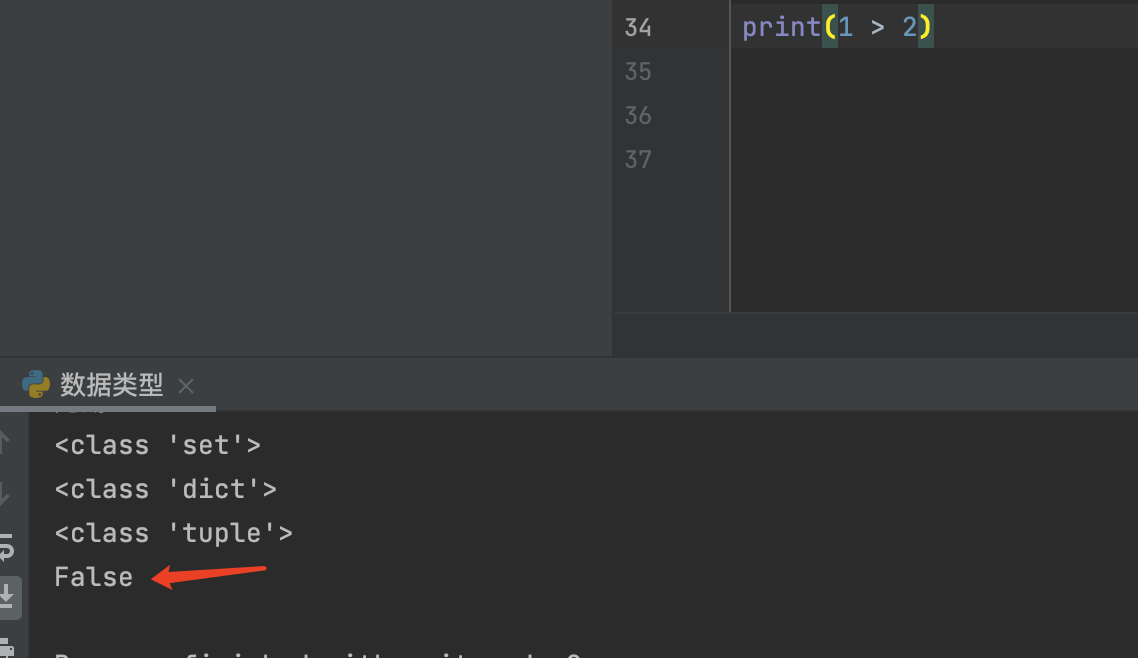
在python中所有的数据在进行逻辑判断的时候它都会转成布尔值
在代码中如果逻辑不对,运行时会直接显示False
布尔值默认为False的数据:
0 None 空字符串 空列表 空字典...,代码中对应数字 2
布尔值默认为True的数据:
其他情况下布尔值都是True,代码中对应数字 1
如何取布尔值的变量名:
一般采用is开头,
is_right = True
is_save = False

学会了一种print输入快捷方式:输入 '内容' + 句点符 按 Tab键 自动补全
占位符:
%s占位符:可以接收任意类型的值
%d占位符:只能接收数字
增量赋值:
x += 100 # x = x + 100
x -= 100 # x = x - 100
x *= 100 # x = x * 100
x /= 100 # x = x / 100
链式赋值:
x = 100
y = x
z = x
用链式赋值书写: x = y = z = 100
交叉赋值:
m = 10
n = 999
# 让m指向n指向的值 让n指向m指向的值
m, n = n, m
print(m, n)
python小功能:单击 :插入。 双击:选中单词 三击:选中一行
解压赋值:
一般要求左右两边的变量名和值个数要相等
也可以打破个数限制
name_list = ['jason', 'kevin', 'tony', 'jerry']
name1, name2, name3, name4 = name_list
单独的下划线作为变量名 意思是为了符合语法 但是指向的值用不到的情况
l1 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
a, b, *_ = l1
print(a, b, _) # 11 22 [33, 44, 55, 66, 77, 88, 99]
a, *_, b = l1
print(a, b, _) # 11 99 [22, 33, 44, 55, 66, 77, 88]
连续多个or(或)
可按照从左到右的顺序依次判断,一旦某一个条件为True,立即判定为True,只有在所有条件的结果都为False的情况下,最终结果才为False
not (非)
将条件翻转 True变为False False变为True
not True
name_list = ['jason', 'kevin', 'tony', 'oscar', 'jerry', 'owen', 'tank']
print('jason' not in name_list)
推荐用not in因为语义更明确
a = ['aa', 'bb', 'cc']
b = ['aa', 'bb', 'cc']
print(a == b)
运行结果为true
a = 666
b = 666
print(a is b)
运行结果为true
is:判断两个数据的内存地址是否一致
==:判断两个数据的值是否一致
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号