论文阅读:《What Makes Training Multi-Modal Classification Networks Hard》
标题:是什么让训练多模态分类网络变得困难?
来源:CVPR 2020[https://arxiv.org/abs/1905.12681]
代码:暂无
一、摘要
考虑在具有多个输入模态的任务上,对多模态网络和单模态网络进行端到端训练:理论上多模态网络接收更多信息,因此它应该等同于或优于单模态网络。然而,实验中观察到相反的情况:最好的单模态网络往往优于多模态网络。这一观察结果在不同的模态组合以及视频分类的不同任务和基准上是一致的。
本文指出了造成这种性能下降的两个主要原因:
-
多模态网络由于其容量的增加而常常容易出现过拟合。
-
不同模态的过拟合和泛化速度不同,采用单一优化策略联合训练是次优的。
对此,文中提出了一种梯度混合(Gradient-Blending)的技术来解决这两个问题,该技术根据模型的过拟合行为来计算模型的最优混合。实验证明,梯度混合可以避免过拟合,并在各种任务上优于广泛使用的基线,包括人类动作识别,以自我为中心的动作识别和声学事件检测等。
二、背景
2.1 多模态融合的方法
-
前端融合:将多个独立的数据集融合成一个单一的特征向量,然后输入到机器学习分类器中。由于多模态数据的前端融合往往无法充分利用多个模态数据间的互补性,且前端融合的原始数据通常包含大量的冗余信息。因此,多模态前端融合方法常常与特征提取方法相结合以剔除冗余信息,如主成分分析(PCA)、最大相关最小冗余算法(mRMR)、自动解码器(Autoencoders)等。
-
后端融合:将不同模态数据分别训练好的分类器输出打分(决策)进行融合。这样做的好处是,融合模型的错误来自不同的分类器,而来自不同分类器的错误往往互不相关、互不影响,不会造成错误的进一步累加。常见的后端融合方式包括最大值融合(max-fusion)、平均值融合(averaged-fusion)、 贝叶斯规则融合(Bayes'rule based)以及集成学习(ensemble learning)等。
-
中间融合:将不同的模态数据先转化为高维特征表达,再于模型的中间层进行融合。以神经网络为例,中间融合首先利用神经网络将原始数据转化成高维特征表达,然后获取不同模态数据在高维空间上的共性。中间融合方法的一大优势是可以灵活的选择融合的位置。
2.2 多模态融合中存在的问题
针对任务:late-fusion 多模态神经网络
训练端到端网络来解决一个任务,其中单模态解决方案是多模态网络中可用解决方案的严格子集;理论上,一个最优的的多模态模型应该总是优于最佳的单模态模型。然而,实验结果上存在一些问题:
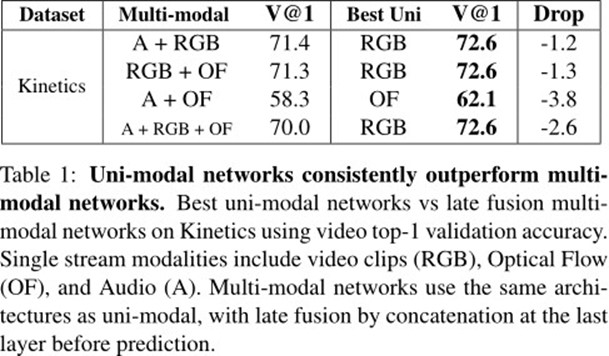
领域:视频分类
模态:RGB 光流OF 音频Audio
数据集:视频理解中的行为数据集Kinetics
问题:多模态网络使用与单模态相同的架构,在预测之前通过concat在最后一层进行后期融合,从结果可以看出,单模态的效果要好于多模态。
可能的问题:
-
由于参数数量的增加造成的过拟合。
-
不同的模态有不同的过拟合和不同速率的泛化能力。
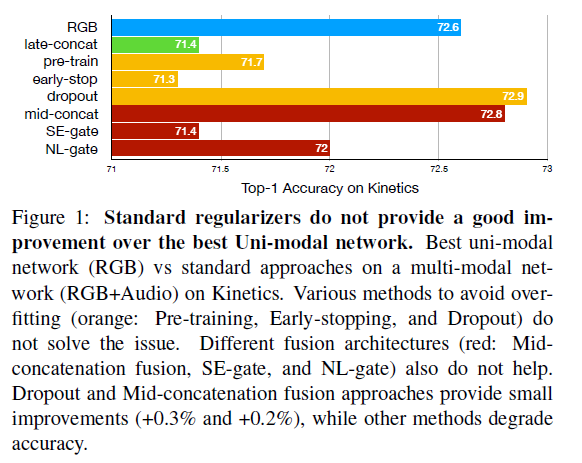
2.3 传统尝试优化的解决方案
-
考虑诸如dropout、pre-training或early stop等方法,以减少过拟合。
-
late-fusion模型的架构缺陷,改进:mid-fusion、Squeeze-and-Excitation gates(SE-gate)、 Non-Local gates(NL-gate)
相对于单模态RGB的结果,避免过拟合的各种方法都不能解决问题,各种融合架构也无法取得优异的性能。
本文工作:
-
通过实证论证了过拟合在多模态网络联合训练中的重要性,并找出了导致该问题的两个原因。而且该问题与架构无关:不同的融合技术也会遇到同样的过拟合问题。
-
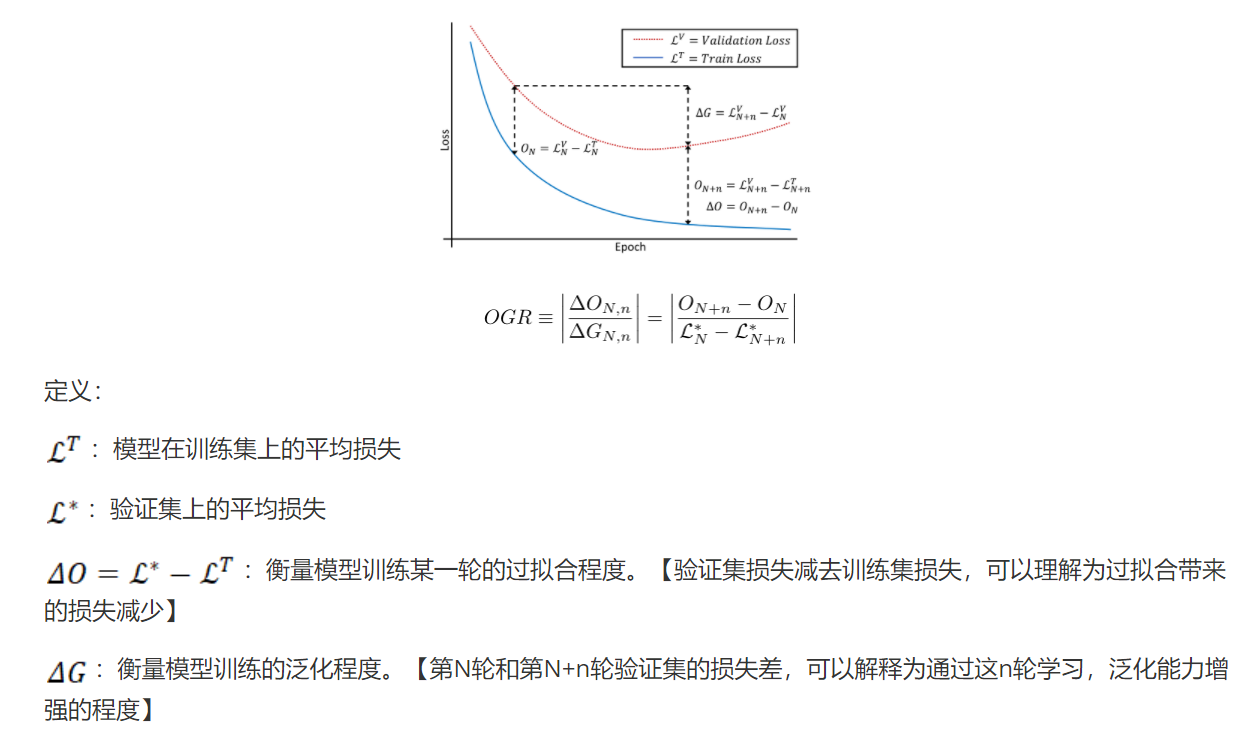
提出了一个度量来定量地理解问题:过度拟合泛化比 (OGR)。
-
提出了一种新的多模态训练方案,通过多个监督信号的最佳混合最小化了 OGR。这种 Gradient- Blending方法在消融方面取得了显着的进步,并通过结合音频和视觉信号在包括 Kinetics、EPIC-Kitchen 和 AudioSet 在内的基准测试中实现了最先进的 (SoTA) 精度。
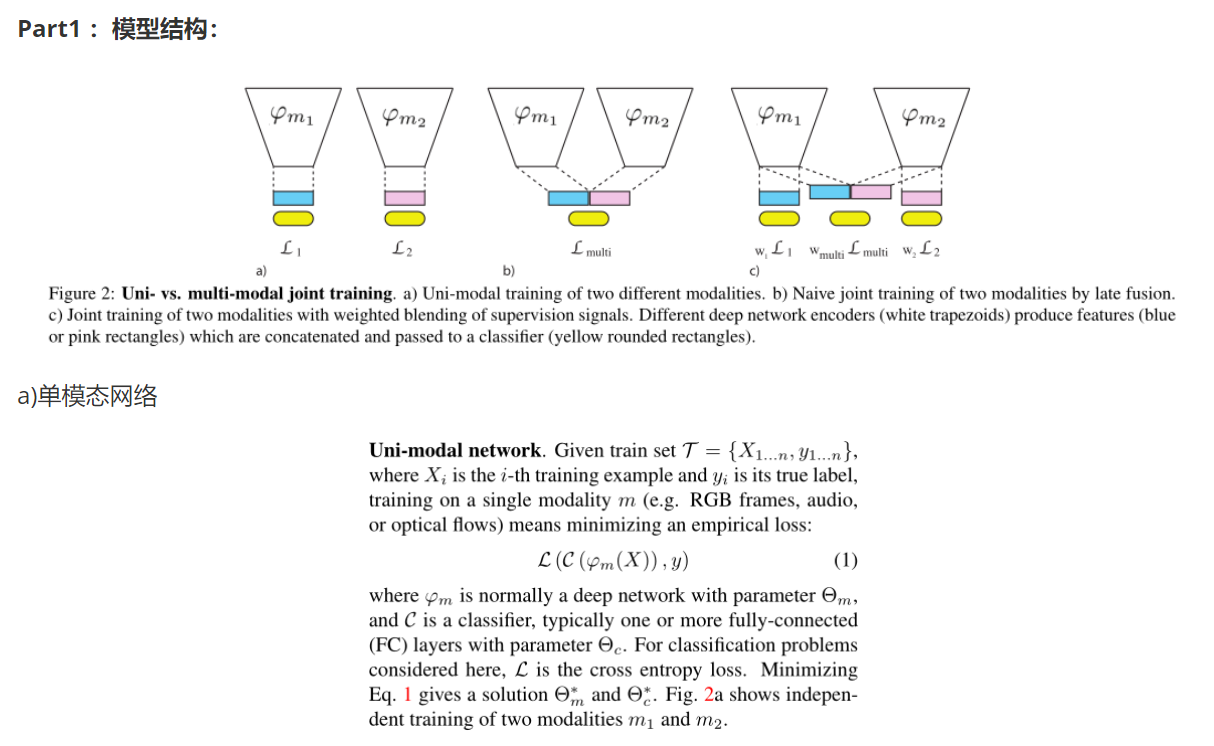
三、模型

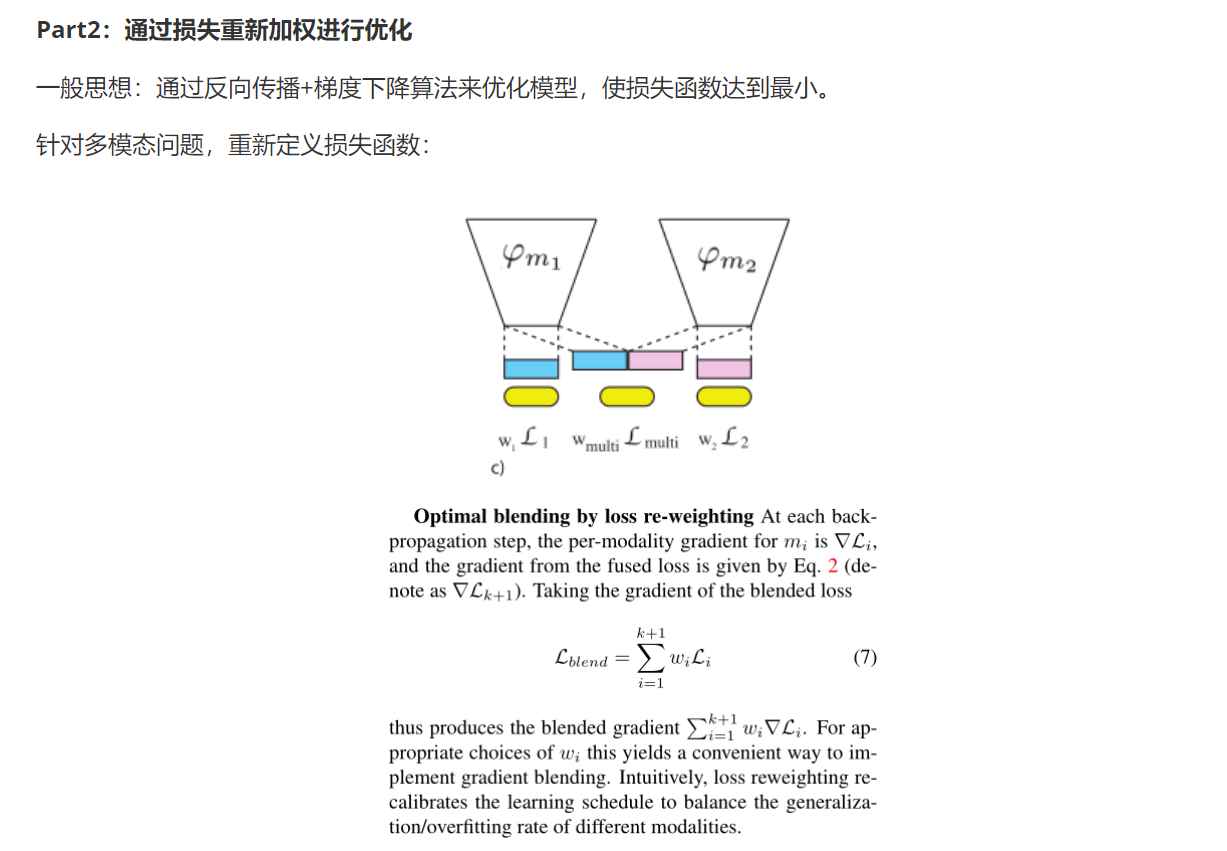








四、实验
数据集:Kinetics、MiniSports、MiniAudioSet
特征:RGB、optical flow、audio
4.1 各个模态的过拟合问题
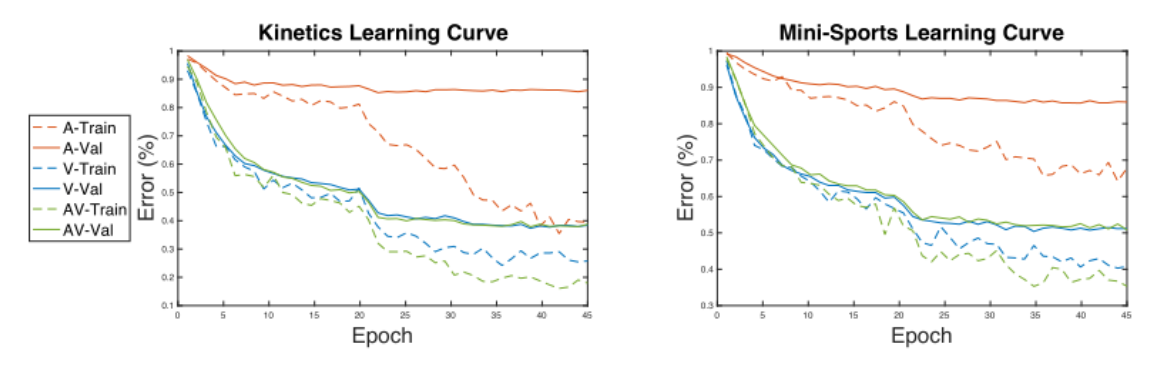
音视频混合模型比视频模型更容易过拟合,且在验证集损失方面不如视频模型。
4.2 对比单模态方法
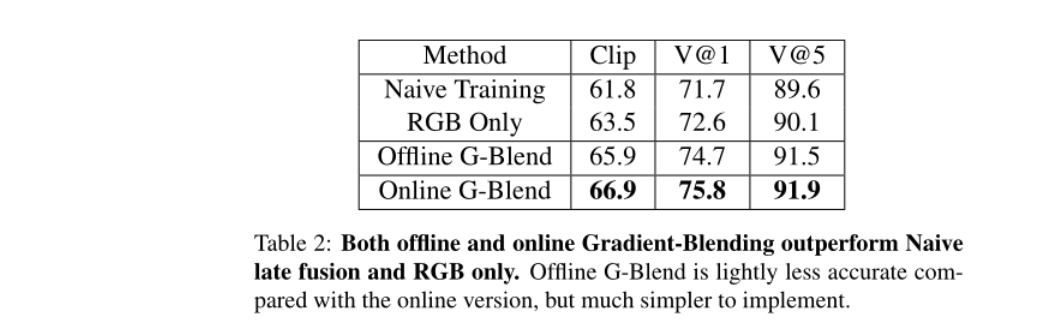
Gradient-Blending优于单模态方法(仅RGB),online效果最好
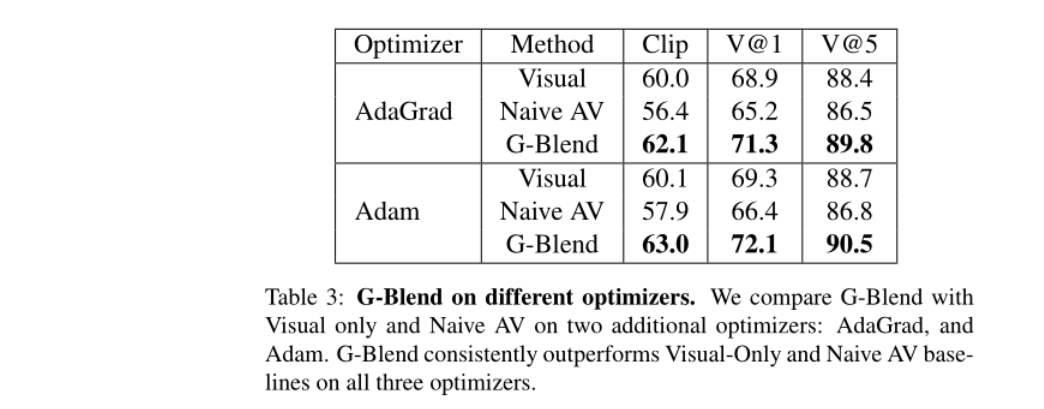
Gradient-Blending的效果优于其他
4.4 不同的多模态问题上的测试
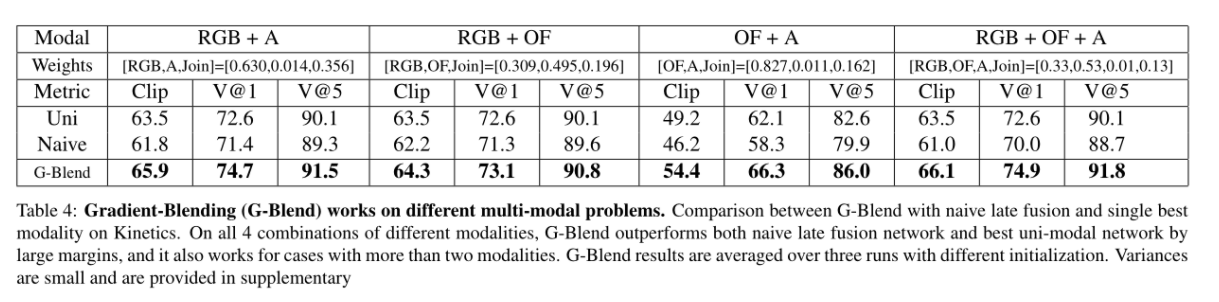
4.5 不同的多模态融合架构上的测试
last fusion:Gradient-Blending提供了0.8%的改善(top-1从72.8%提高到73.6%)
证明了Gradient-Blending可以应用于除last fusion之外的其他特征融合策略,以及concat连接融合之外的其他融合架构。
五、应用
参考:
ImVoteNet:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号