

selenium并发请求的实现-第一篇
前言
原本使用selenium爬取数据,只能一个个爬取。如果想提升爬取速度,短时间获取更多数据,那么就需要并发执行了。那么我们先了解下python并发编程的实现方式
并发介绍
Python的并发编程有三种方式:多线程,多进程,多协程,下面对比说明下他们3个的特点。
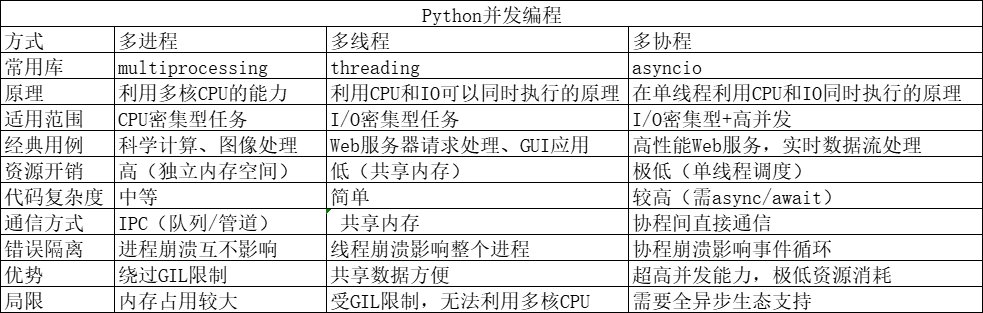
实现过程
在了解以上信息后,先决定从资源开销最低的asyncio来实现下看看
1.第一步,先实现最基础的获取百度搜索结果中的标题,然后我们看怎么改造成异步实现。
1 import time 2 from selenium import webdriver 3 from selenium.webdriver.common.by import By 4 from selenium.webdriver.chrome.options import Options 5 from concurrent.futures import ThreadPoolExecutor 6 import asyncio 7 import aiohttp 8 9 10 def sync_search_baidu(key_word: str): 11 """实际的搜索逻辑""" 12 options = Options() 13 # options.add_argument('--headless') # 启用无头模式 14 options.add_argument('--disable-gpu') # 禁用GPU加速 15 driver = webdriver.Chrome(options=options) 16 driver.maximize_window() # 最大化窗口 17 search_result = [] 18 try: 19 driver.get("https://www.baidu.com") 20 driver.find_element(By.ID, "kw").send_keys(key_word) 21 driver.find_element(By.ID, "su").click() 22 time.sleep(3) 23 search_results = driver.find_elements(By.XPATH, "//div[@id='content_left']//h3//p/span/span") 24 search_result = [result.text for result in search_results] 25 return search_result 26 except Exception as e: 27 return search_result.append(f"Error occurred while searching for '{key_word}': {e}") 28 finally: 29 driver.quit()
2.第二步,改造成异步实现
1 executor = ThreadPoolExecutor(max_workers=10) # 创建一个线程池,最大线程数设置为10 2 async def search_baidu(key_word: str): 3 """执行百度搜索的异步封装""" 4 loop = asyncio.get_event_loop() # 获取当前事件循环 5 try: 6 # 在线程池中执行同步的Selenium操作 7 return await loop.run_in_executor( 8 executor, 9 sync_search_baidu, 10 key_word 11 ) 12 except Exception as e: 13 return {"error": str(e)}
3. 第三步,创建一个客户端,去并发访问我们的异步函数,查看是否真的实现了并发请求
1 async def client_test(): 2 key_words = ['面积最大的国家', '死亡人数最多的战役', '化学元素共有多少种'] 3 async with aiohttp.ClientSession() as session: 4 # 创建多个任务,每个任务对应一个搜索关键词 5 tasks = [search_baidu(key_word) for key_word in key_words] 6 # 使用asyncio.gather()来同时运行多个任务,并等待它们全部完成。 7 all_result = await asyncio.gather(*tasks) 8 return all_result 9 10 11 if __name__ == '__main__': 12 results = asyncio.run(client_test()) 13 print(results)
4.经过运行,发现浏览器会同时打开3个,去百度进行查询,完美实现了并发请求。实际运行时,为减少资源消耗,可以开启options.add_argument('--headless') # 启用无头模式
后续我们继续使用multiprocessing和threading,来实现并发请求,请期待我的下一篇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号