激活函数(relu,prelu,elu,+BN)对比on cifar10
激活函数(relu,prelu,elu,+BN)对比on cifar10
可参考上一篇:
一.理论基础
1.1激活函数
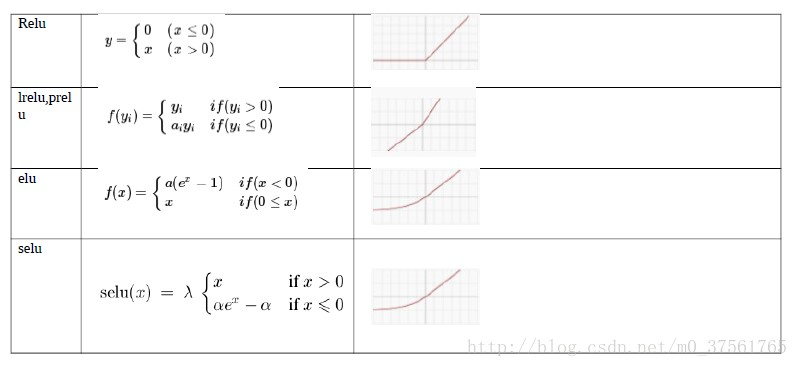
1.2 elu论文(FAST AND ACCURATE DEEP NETWORK LEARNING BY
EXPONENTIAL LINEAR UNITS (ELUS))
1.2.1 摘要
论文中提到,elu函数可以加速训练并且可以提高分类的准确率。它有以下特征:
1)elu由于其正值特性,可以像relu,lrelu,prelu一样缓解梯度消失的问题。
2)相比relu,elu存在负值,可以将激活单元的输出均值往0推近,达到
batchnormlization的效果且减少了计算量。(输出均值接近0可以减少偏移效应进而使梯
度接近于自然梯度。)
3)Lrelu和prelu虽然有负值存在,但是不能确保是一个噪声稳定的去激活状态。
4)Elu在负值时是一个指数函数,对于输入特征只定性不定量。
1.2.2.bias shift correction speeds up learning
为了减少不必要的偏移移位效应,做出如下改变:(i)输入单元的激活可以
以零为中心,或(ii)可以使用具有负值的激活函数。 我们介绍一个新的
激活函数具有负值,同时保持正参数的特性,即elus。
1.2.4实验
作者把elu函数用于无监督学习中的autoencoder和有监督学习中的卷积神经网络;
elu与relu,lrelu,SReLU做对比实验;数据集选择mnist,cifar10,cifar100.
2ALL-CNN for cifar-10
2.1结构设计

ALL-CNN结构来自论文(STRIVING FOR SIMPLICITY:
THE ALL CONVOLUTIONAL NET)主要工作是把pool层用stride=2的卷积来代替,提出了一些全卷积网络架构,kernel=3时效果最好,最合适之类的,比较好懂,同时效果也不错,比原始的cnn效果好又没有用到一些比较大的网络结构如resnet等。
附上:
Lrelu实现: def lrelu(x, leak=0.2, name="lrelu"): return tf.maximum(x, leak * x) Prelu实现: def parametric_relu(_x): alphas = tf.get_variable('alpha', _x.get_shape()[-1], initializer=tf.constant_initializer(0.25), dtype = tf.float32 ) pos = tf.nn.relu(_x) neg = alphas * (_x - abs(_x)) * 0.5 print(alphas) return pos + neg BN实现: def batch_norm(x, n_out,scope='bn'): """ Batch normalization on convolutional maps. Args: x: Tensor, 4D BHWD input maps n_out: integer, depth of input maps phase_train: boolean tf.Variable, true indicates training phase scope: string, variable scope Return: normed: batch-normalized maps """ with tf.variable_scope(scope): beta = tf.Variable(tf.constant(0.0, shape=[n_out]), name='beta', trainable=True) gamma = tf.Variable(tf.constant(1.0, shape=[n_out]), name='gamma', trainable=True) tf.add_to_collection('biases', beta) tf.add_to_collection('weights', gamma) batch_mean, batch_var = tf.nn.moments(x, [0,1,2], name='moments') ema = tf.train.ExponentialMovingAverage(decay=0.99) def mean_var_with_update(): ema_apply_op = ema.apply([batch_mean, batch_var]) with tf.control_dependencies([ema_apply_op]): return tf.identity(batch_mean), tf.identity(batch_var) #mean, var = control_flow_ops.cond(phase_train, # mean, var = control_flow_ops.cond(phase_train, # mean_var_with_update, # lambda: (ema.average(batch_mean), ema.average(batch_var))) mean, var = mean_var_with_update() normed = tf.nn.batch_normalization(x, mean, var, beta, gamma, 1e-3) return normed
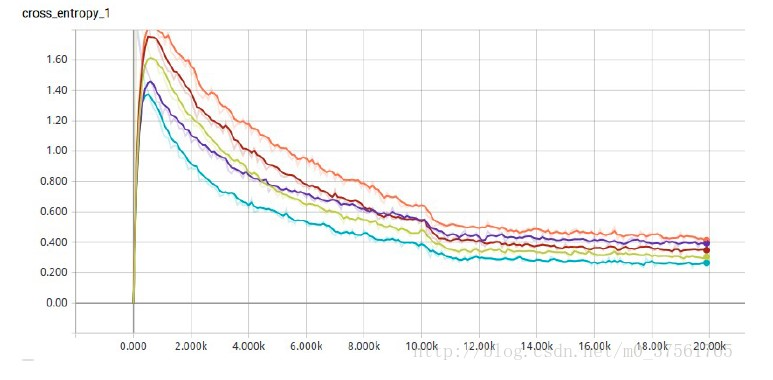
在cifar10 上测试结果如下:

以loss所有结果如下:relu+bn>elu>prelu>elubn>relu
所有的测试准确率如下

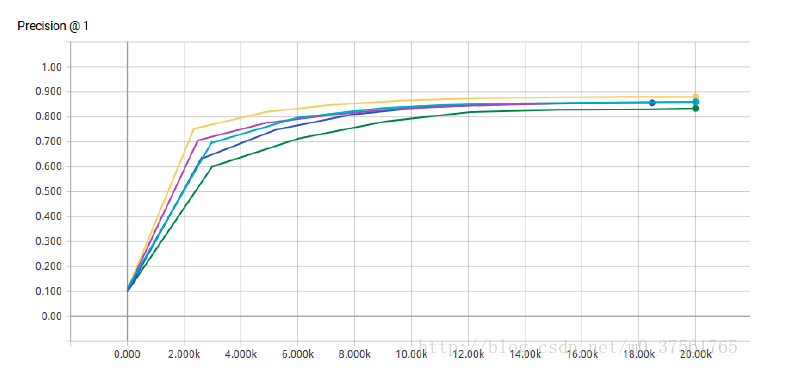
relu+bn组合准确率最高,relu+bn>elu>prelu>elubn>relu
可见elu在激活函数里表现最好,但是它不必加BN,这样减少了BN的计算量。
3.ALL-CNN for cifar-100
cifar100数据集
CIFAR-100 python version,下载完之后解压,在cifar-100-python下会出现:meta,test和train
三个文件,他们都是python用cPickle封装的pickled对象
解压:tar -zxvf xxx.tar.gz cifar-100-python/ cifar-100-python/file.txt~ cifar-100-python/train cifar-100-python/test cifar-100-python/meta def unpickle(file): import cPickle fo = open(file, ‘rb’) dict = cPickle.load(fo) fo.close() return dict
通过以上代码可以将其转换成一个dict对象,test和train的dict中包含以下元素:
data——一个nx3072的numpy数组,每一行都是(32,32,3)的RGB图像,n代表图像个数
coarse_labels——一个范围在0-19的包含n个元素的列表,对应图像的大类别
fine_labels——一个范围在0-99的包含n个元素的列表,对应图像的小类别
而meta的dict中只包含fine_label_names,第i个元素对应其真正的类别。
二进制版本(我用的):
<1 x coarse label><1 x fine label><3072 x pixel>
…
<1 x coarse label><1 x fine label><3072 x pixel>
网络结构直接在cifar10的基础上输出100类即可,只对cifar100的精细标签100个进行分类任务,因此代码里取输入数据集第二个值做为标签。(tensorflow的cifar10代码)
label_bytes =2 # 2 for CIFAR-100 #取第二个标签100维 result.label = tf.cast( tf.strided_slice(record_bytes, [1], [label_bytes]), tf.int32)
在all CNN 9层上,大约50k步,relu+bn组合测试的cifar100 test error为0.36
PS:
Activation Function Cheetsheet
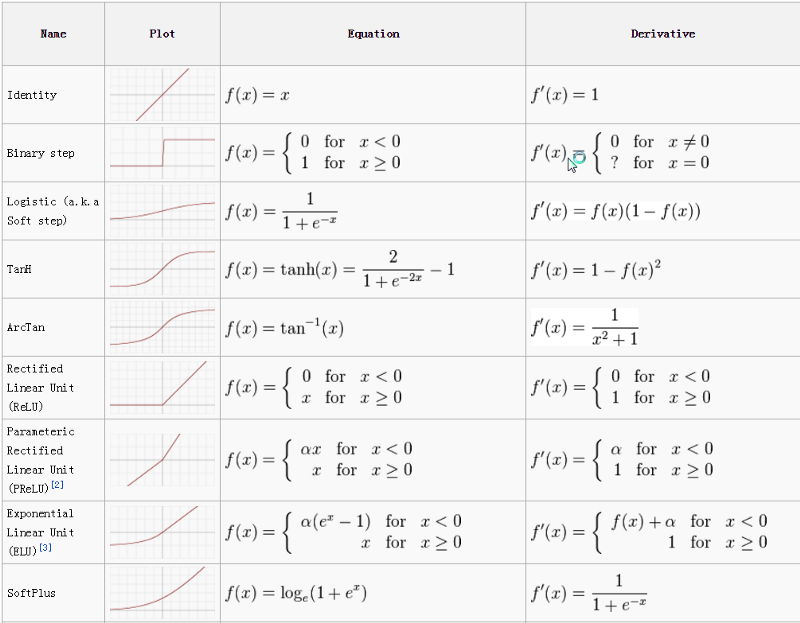
https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6
欢迎转载,转载请保留页面地址。帮助到你的请点个推荐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号