
正则表达式
简介:作为一个开发人员的我已经和正则表达式接触过了多次,从开始的基础语法学习,到慢慢的研究正则的原理,中间是对它一点点的熟悉。网上的很多资料大都是对正则的基础学习和原理,但如果不是对它很熟悉的话,会发现猛然给你个真正表达式还是很难阅读它的。对于这点我总结了一些小小经验与大家分享。备注:自我感觉本文并不适合初学者,而是对正则表达式有一定认识(起码要熟悉真正表达式的基础语法)的人。
一:举例
通过三个举例来验证你的正则表达式的熟悉程度
eg1:regex = "abc"
eg2:regex="ab{1,3}c"
eg3:regex="ab{1,3}?c"
eg4:regex="^([hH][tT]{2}[pP]:\/\/|[hH][tT]{2}[pP][sS]:\/\/)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~_%\/])+$";
二:如何阅读正则表达式
2.1 确定一个名词 (正则表达式的基本单元)
一个名词即正则表达式中的一个基本单元,例如eg1中的abc其中a,b,c分别代表一个名词,即他们按顺序分别匹配字符串中的abc。
备注:“.”一个点符号也是一个名词,它可匹配任意字符
备注:“[abc]”即“[]”号也代表一个名词,它匹配[]号中的任意一个字符串
2.2 说明(或解释)名词的词(量词或形容)
量词:看过菜鸟学院的同学就应该熟悉,它在里面举例了多个量词,如 ? * + {} ....,它一般是修饰其前面的名词(),表示其前面的名词可匹配的数量。
如eg2中的{1,3}它表示b可以匹配1到3次。
形容词:^号(说明字符串要以该名词开头)和$号(说明字符串要以该名词结尾)
备注:对于用量词修饰的名词其整体(b{1,3})应看成一个名词,即正则中的一个基础单元。
2.3 确定一个冠词(限定量词)
冠词是修饰量词的,在正则表达式中的冠词有 + ? 一旦被冠词修饰了的基础单位,就改变了正则表达式中的默认匹配模式(默认匹配模式是贪婪模式)。
备注:+ 号变成独占模式(相对于贪婪模式,其不会回溯)
备注:? 号变成懒惰模式(尽量匹配少的的字符串,但会回溯)
备注:回溯是指正则表达式的回溯
例如:eg3中的‘b{1,3}?’就是把默认的贪婪模式改变成为了懒惰模式。
2.4 认识分组
可以通过()把多个名词(基本单元),看做一个整体,即一个基本单位。如eg4其简化结构为()(().)+()+$,根据以上解释该结构应该是3个名词,其中中间名词包含了两个名词()和.。
三:正则表达式的设计思想
比如我(A)手里有一个正则表达式,另一个人(B)手里有一个待检测的字符串。为达到字符串是否符合该正则。我可以根据我手中的表达式去比较另一个人手中的字符串(以正则表达式为基准),当然还有一种方法是另一个人根据其手中的字符串是否符合我手中的表达式(已字符串为基准)。根据这两种思想就可引出正则表达式的两种引擎DFA 自动机(Deterministic Final Automata 确定型有穷自动机)和 NFA 自动机(Non deterministic Finite Automaton 不确定型有穷自动机)。
四:正则表达式引擎
即根据设计思想实现的正则表达式的两套算法
DFA 自动机:以字符串为基准
NFA 自动机:以正则表达式为基准
五:追述历史
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。其最早可追述到人们对神经系统工作原理的早期研究,其最早运用在软件方面式是在unix操作系统中的工具软件(例如sed和grep)上的,后被多种语言支持(例如Java,Js,C,Shell,....)和软件(RabbitMQ在设计高可用集群策略,githu的忽略文件都有涉及)支持。故学好正则表达式对我们开发人员来说是相当适用的一项能力。
六:其它
快熟查询:菜鸟学院
一个功能齐全的正则表达式工具:https://regex101.com/
一个不错的博客:正则表达式里的底层原理是什么
一个不错的博客:一个由正则表达式引发的血案
七:追加(正则优化)
如果看过上面推荐的两个博客后,尤其是第二个(一个由正则表达式引发的血案) 。你一定会惊出一身冷汗,一个小小的正则就可以导致一个庞大的服务器系统奔溃。作为一个小小的程序员如果是因为一个长度不上百的正则表达式引起了公司的动荡,将会给我们带来多么大的压力呀^_^。故掌握点使用的干货还是有必要的。
通过两个博客的案例,其避免灾难性的错误和优化的重点就是,控制回溯“回溯陷阱(Catastrophic Backtracking)的次数(),所以你一定要弄清楚什么是回溯(第一个博客有介绍),会分析回溯(可通过上面的工具帮助理解)。
容易引起回溯正则的基本单元有
1.[A-Za-z0-9-~]+
即'[]+'号里面比配的多种可能,又因‘+’贪婪比配故其可匹配出无限可能(可能直接匹配到字符串尾部),然后就产生过多回溯(Catastrophic Backtracking())。
2. ‘.’,点号即匹配任意字符(除空格和换行符)
原理同上
案例:通过控制回溯优化正则表达式
之前做过一个项目,其中的一个需求就是匹配出一个html页面中的所有图片url,然后下载该图片到自己服务器,并把url替换成自己的图片地址。
首先:编写正则表达式
String reg = "(http:|https:){1}[\\//]{2}[A-Za-z0-9.\\/\\-\\_\\%]+(bmp|jpeg|gif|png|jpg)";
然后:匹配字符串中的所有符合以上真正的url,


public static List<String> searchPicUrlInString(String html) { List<String> urlList = new ArrayList<String>(); // 图片网址正则 String reg = "(http:|https:){1}[\\//]{2}[A-Za-z0-9.\\/\\-\\_\\%]+(bmp|jpeg|gif|png|jpg)"; Pattern pattern = Pattern.compile(reg); Matcher matcher = null; matcher = pattern.matcher(html); while (matcher.find()) { String imageUrl = matcher.group(0); ************ urlList.add(imageUrl); } return urlList; }
测试匹配步骤

图中该字符串中匹配了28处,匹配第一个url匹配了4872次(结果也算是秒出的,接受)。
3。假如我把正则换成了如下(即'[A-Za-z0-9.\\/\\-\\_\\%]+' >>> '.+')
String reg = "(http:|https:){1}[\\//]{2}.+(bmp|jpeg|gif|png|jpg)";
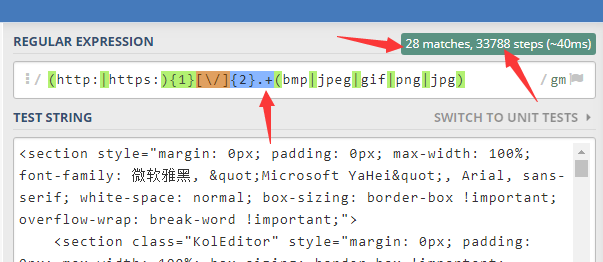
由图可知同样是28处url,但匹配出第一个url所用步骤为33788,比上一个步骤多出了7 8 倍(其原因就是'.+'产生了过多的回溯,直接匹配到字符串未,然后回溯(字符串越长回溯越多))。
备注:以上结果都是通过上面提到到工具测试https://regex101.com/。手动debug一下可以帮助你理解哦,(不会可以问我)
备注:写正则不一定非要精简(不像我们写代码),因为正则是描述规则的,故规则越清晰越好(所以就不会精简)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号