

mysql之UPDATE,SELECT,INSERT语法
一 :UPDATE语法
UPDATE 是一个修改表中行的DML语句。
#单表语法(常用) UPDATE [LOW_PRIORITY] [IGNORE] table_reference SET assignment_list [WHERE where_condition] [ORDER BY ...] #例如 ORDER BY id DESC; 若ID不重复且自增,故需要先增加的最大的id后增较小id避免因为重复id保存(不常用) [LIMIT row_count] #多表语法 UPDATE [LOW_PRIORITY] [IGNORE] table_references #若为多表需要‘,’分割 例如 table_reference , table_reference2
SET assignment_list [WHERE where_condition]
value: ()
{expr | DEFAULT} #值可以是表达式或默认值 例如 col1 = col1 + 1,(这就是表达式)
assignment:
col_name = value # col_name 列名
assignment_list:
assignment [, assignment] ...
二:SELECT语法(常用语法,与官方有点差别,主要是删除了一些可选参数)
SELECT用于检索从一个或多个表中选择的行
SELECT select_expr [, select_expr ...] [FROM table_references] #可以是多表 [WHERE where_condition] #条件表达式 [GROUP BY {col_name | expr | position} #分组 [ASC | DESC], ... [WITH ROLLUP]] [HAVING where_condition] #包含 [ORDER BY {col_name | expr | position} #排序 [ASC | DESC], ...] [LIMIT {[offset,] row_count | row_count OFFSET offset}] #分页
注意:除select_expr其他都是可选参数
语法解析:
1.select_expr 选择表达式 (多个表达式需要用‘,’分割)
例如: table.列名 (映射)
例如: CONCAT(last_name,', ',first_name) AS full_name (聚合函数和别名 连接多列的字段),和直接调用其他集合函数
例如:(CASE WHEN t3.`CATEGORY` = 2 THEN `T`.`ADDRES` ELSE NULL END) AS `ADDRES` (选择表达式,可选着显示内容 例 当''t3.CATEGORY = 2 " 为真时显示THEN后值 为false时显示ELSE的值)
2.where_condition 条件表达式
例如 :id = 2 (当id等于2时为真时显示该数据)
例如 :NOT EXISTS ( select id form classes where id = 5) (即一个子查询并判断查询的结果是否显示数据) 注意子查询可用父查询的表数据作为条件
3. GROUP BY 分组 根据列进行分组(列的类型可以是字符串。。。。)
例如 :对单列分组》group by id (默认是ASC升序,)指定分组方式 group by id ASC
例如: 对多列进行分组 GROUP BY c.id ASC ,t.`tid` DESC; (并按不同方式)
4. HAVING 包含
5. ORDER BY 排序可参考group by 都有按不同方式排序
6. LIMIT 分页
三:INSERT语法
语法1 (常用插入方式 构造器插入)
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name #表明必选
[(col_name [, col_name] ...)] {VALUES | VALUE} (value_list) [, (value_list)] ... #必选 [ON DUPLICATE KEY UPDATE assignment_list] #此次忽略
语法2 () INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[(col_name [, col_name] ...)]
SELECT ...
[ON DUPLICATE KEY UPDATE assignment_list]
语法3 (set插入)
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
SET assignment_list
[ON DUPLICATE KEY UPDATE assignment_list]
value: {expr | DEFAULT}
#解析 expr 可用算数运算符 如 score=score+1 value_list: value [, value] ... assignment: col_name = value assignment_list: assignment [, assignment] ...
解析语法:
语法1 除table(表名)和value(值) 为必选其他都是可选
例如 : INSERT INTO tbl_name () VALUES(); 即插入一条数据(所有值都为默认值)
例如 : INSERT INTO tbl_name (col1,col2) VALUES(15,col1*2); #运用了算数运算符 (注意:col2(第二列)引用的第一列的值 ,因为第一列先插入了值所以第二列可以引用,若反过来VALUES(col2*2,15) 则不合法)
语法2 :可把select 语句查询出来的值 理解为语法1中的value (可用于快熟复制一天记录)
例如 : INSERT INTO classes(id) SELECT NULL FROM classes c WHERE c.id=4; # 插入一条空数据 ,因为id 不能为空所以需值定该值
语法3:通过关键字set 已key=value 的形式插入到表中
例如: insert into test set a='abc';
可选参数
1:[ IGNORE ] : 顾名思义 ignore是忽略的意识,结合官方文档和自己的理解如下
如果用insert 插入数据,并且用‘ignore’关键字修饰了insert,则当插入数据发生错误时mysql服务器会忽略该错误并转换为warning信息,并继续执行下条插入信息。
例如 : 执行插入 INSERT IGNORE INTO teacher(tid,class_id,NAME) VALUES(14,1,'teacher12'),(15,1,'teacher11'); (teacher表信息 tid 为主键 且tid=14已经存在,tid=15不存在)
执行结果: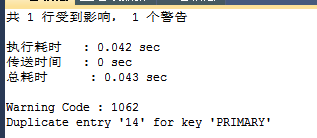
分析:当执行插入tid=14时发生了错误,服务器忽略了该错误并转化为警告信息,并继续执行了tid=15的数据
可利用该特性:插入或忽略,即当该条数据(id)已经存在发出警告,否则就执行插入
2:[ ON DUPLICATE KEY UPDATE assignment_list ] : 当key发生DUPLICATE (重复错误)时执行 update语句 》插入或更新
例如:INSERT INTO teacher(tid,class_id,NAME) VALUE(14,1,'teacher12') ON DUPLICATE KEY UPDATE class_id=1,NAME='teacher1233333';
即当tid=14已经存在就执行更新语句,否则就执行insert语句;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号