
优雅的模型:变分自编码器(VAE)
1. Introduction
有了之前损失函数(一):交叉熵与KL散度、损失函数(二):MSE、0-1 Loss与Logistic Loss两篇文章的基础,我们现在可以开始做一些真的模型了。
中文社区里有一些对于VAE的介绍,但是我感觉这些往往流于表面,没有很好的把每一步的动机解释清楚。这篇文章将详细对VAE模型进行介绍,包括它的产生动机、数学推导、Conditional VAE扩展,以及它的实现与细节讨论。
希望这篇文章能够更加清楚的写出,为什么我们需要VAE、为什么VAE这样设计。文章较长、推导较多,难免有疏忽和错误,也请读者不吝指正。
2. Motivation
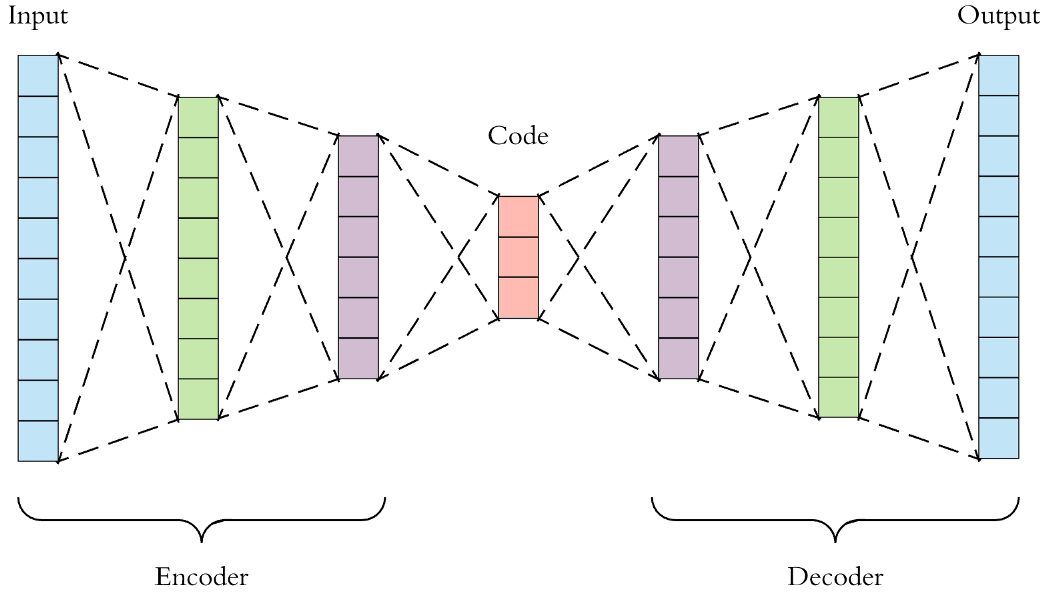



3.1 Decoder
首先,让我们从生成模型的角度来考虑Decoder的架构。
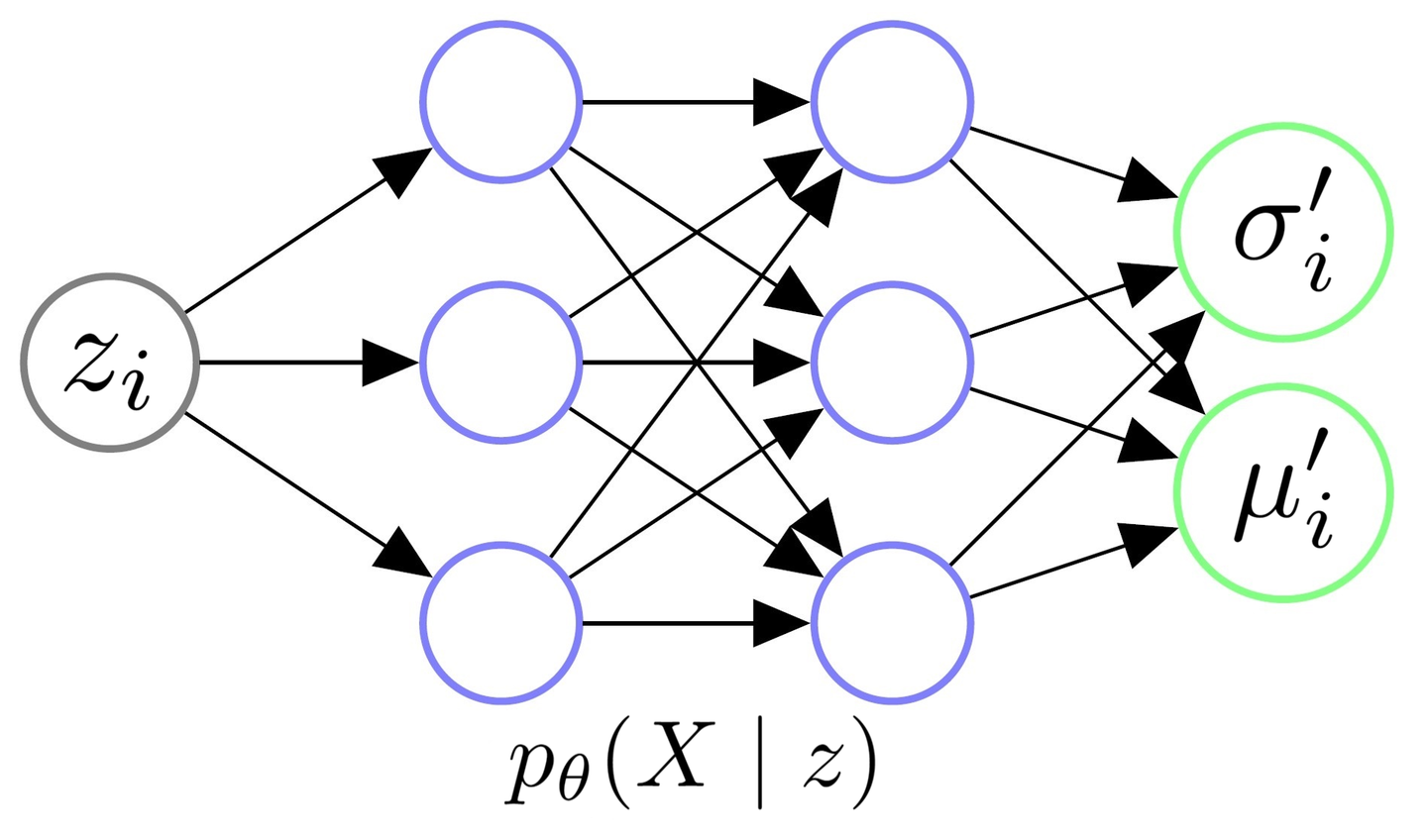

3.2 Objective
因为本质上我们希望训练一个生成模型,我们也不妨以一个更加统计的视角来看一个生成模型的目标函数。
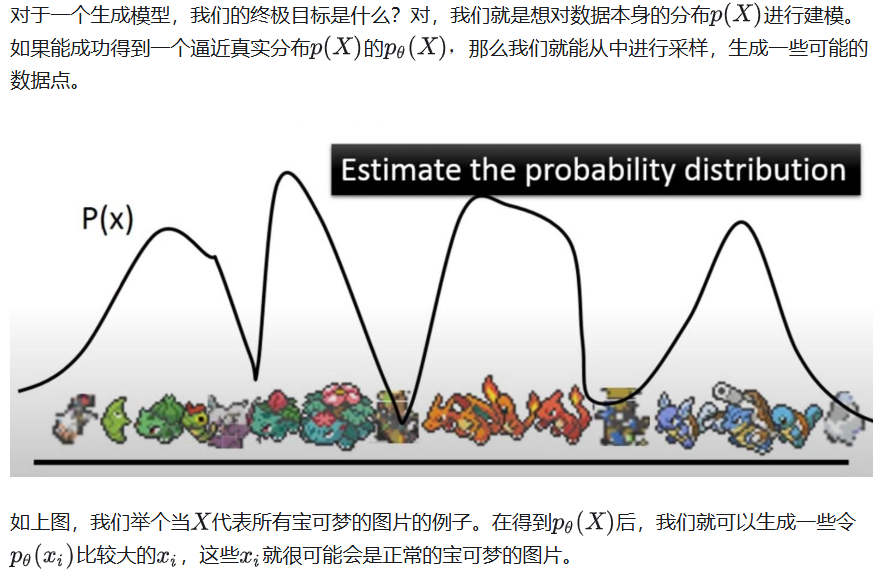


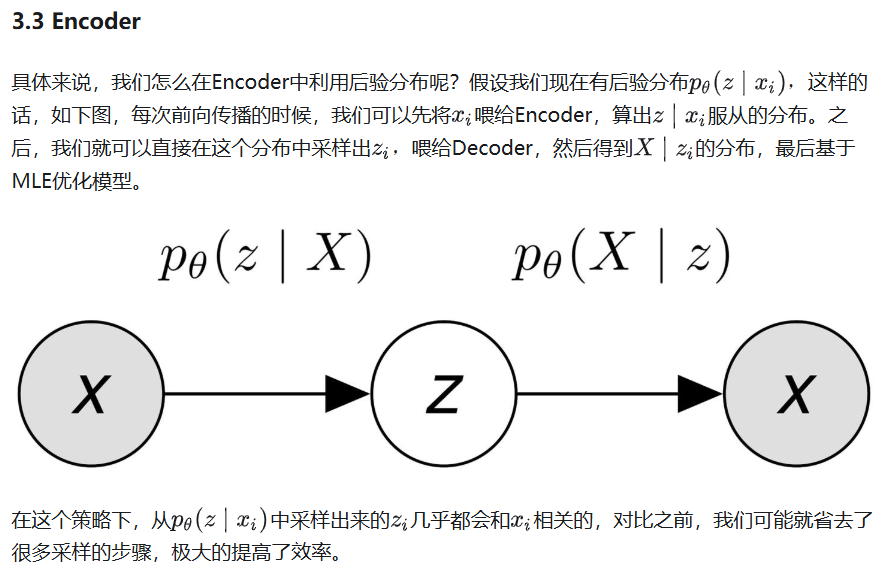

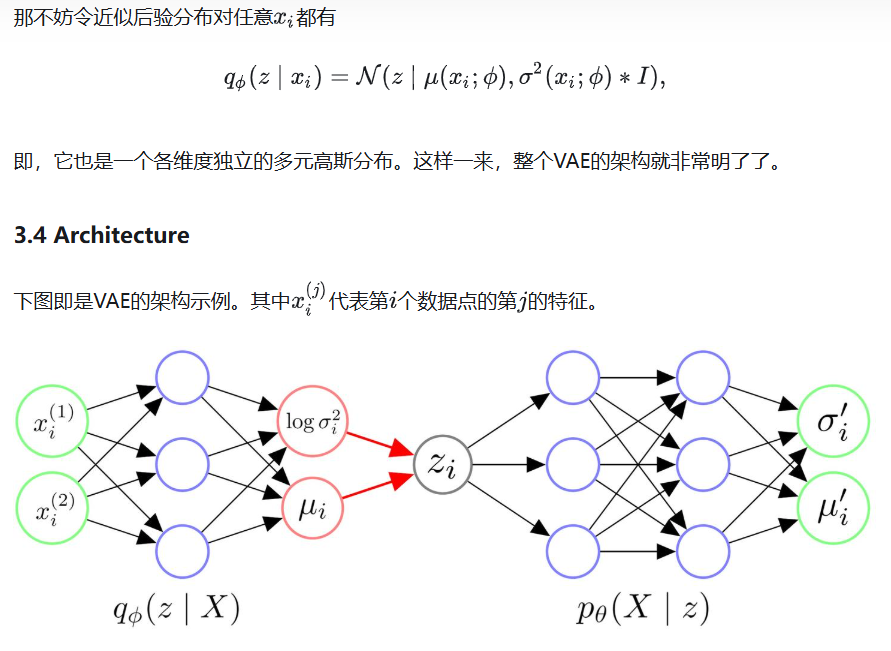


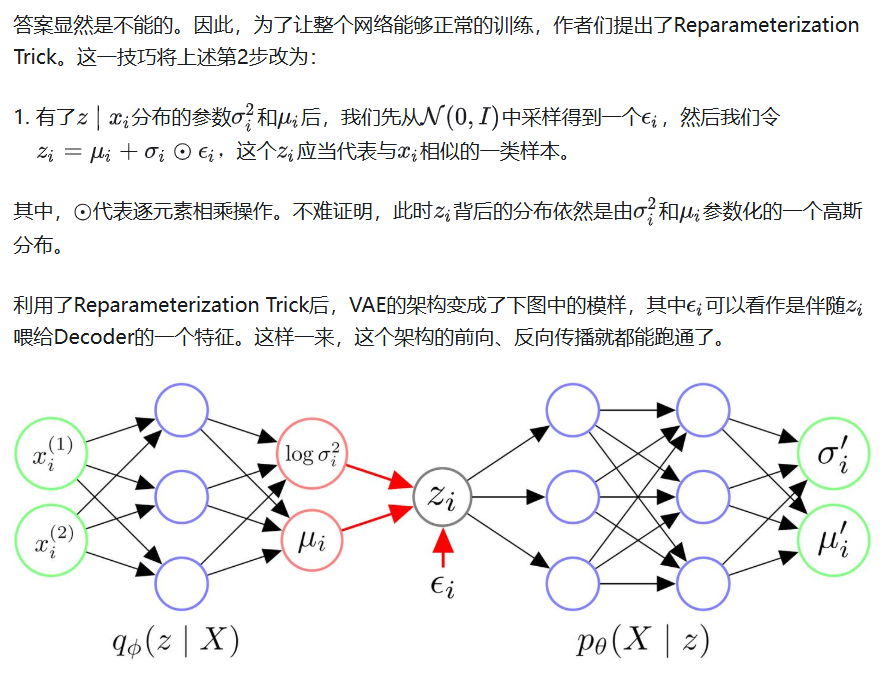











5. Implementation
我们在VAE.py中实现了VAE和CVAE。VAE的实现非常简单,主要就是损失函数的实现。我们在代码中的变量名与该文章中的符号是一致的。
下图是我在MNIST上跑的一组示例。



6. Discussion
VAE中最老生常谈的问题就是,它为什么生成的图片是模糊的?
我在寻找这个问题的答案的时候,从Reddit的一个Post上看到一个高赞回答:
Vanilla VAEs with Gaussian posteriors / priors and factorized pixel distributions aren't blurry, they're noisy. People tend to show the mean value of p(x|z) rather than drawing samples from it. Hence the reported blurry samples aren't actually samples from the model, and they don't reveal the extent to which variability is captured by pixel noise. Real samples would typically demonstrate salt and pepper noise due to independent samples from the pixel distributions.
知乎上也有引用这段话的关于VAE的文章。


7. References
[1] Doersch, Carl. "Tutorial on variational autoencoders." arXiv preprint arXiv:1606.05908 (2016).
[2] Slides from UIUC CS446: Machine Learning
[3] Slides from Hung-yi Lee's ML Lecture
[4] Zhao, Shengjia, Jiaming Song, and Stefano Ermon. "Towards deeper understanding of variational autoencoding models." arXiv preprint arXiv:1702.08658 (2017).
出处:https://zhuanlan.zhihu.com/p/348498294
-------------------------------------------
个性签名:无论在哪里做什么,只要坚持服务、创新、创造价值,其它的东西自然都会来的。
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号