

结合目标识别小项目——软件设计方案
结合目标识别小项目——软件设计方案
一、项目背景
我的工程实践项目是NLP算法,但是这个学期主要学的还是CV,所以我用一个关于人脸口罩识别的小项目,作为例子,来学习软件设计方案。我觉得无论是CV还是NLP,知识点都是融会贯通的,用做过的项目入手,能够更好地把握知识点。
目标识别技术的应用已经越来越广泛。我目前完成的是在keras版本的yolov3框架下,实现迁移学习,实现人脸是否佩戴口罩的目标识别,调用本地摄像头实现实时检测。作为一个软件系统,我所做的东西只是冰山一角,训练出的模型还可以部署到服务器和移动端。所以我增加了一些细节,假设我实现的只是服务器端应该完成的内容,相对于一个比较完善的项目——该系统采用摄像头对现场环境实时监控,服务器读取摄像机采集到的视频图像,并且对是否佩戴口罩进行人脸检测识别,将检测和识别结果返回到客户端。如果识别结果符合某个判断,系统将发送相关信息给工作人员。
首先,我们使用到的yolov3算法的网络结构如下,关于网络模型这里,不做赘述。
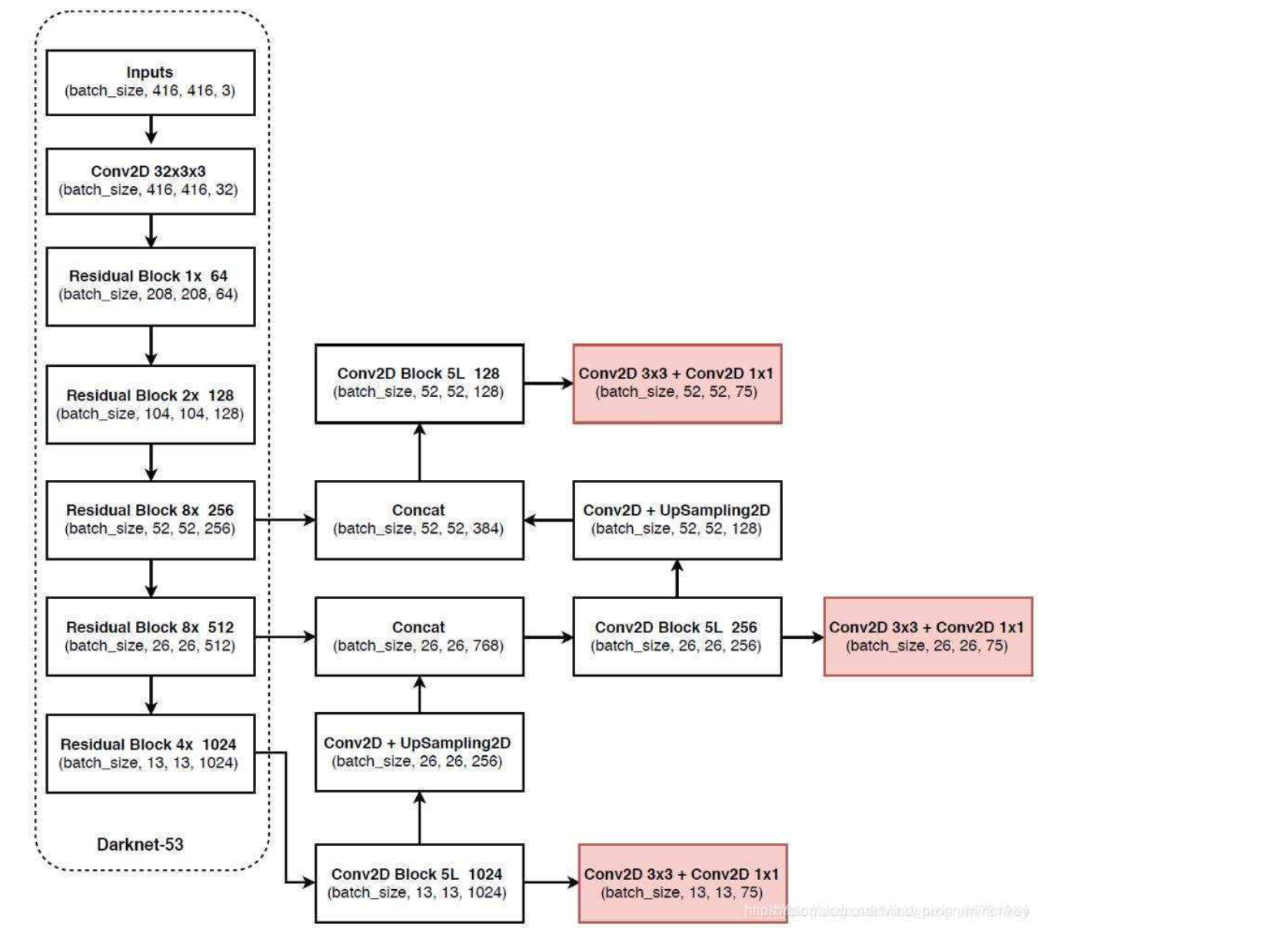
二、项目设计方案
软件架构
本项目采用MVC架构,MVC即为Model-View-Controller(模型-视图-控制器),MVC中M、V和C所代表的含义如下:
- Model(模型)代表一个存取数据的对象及其数据模型。
- View(视图)代表模型包含的数据的表达方式,一般表达为可视化的界面接口。
- Controller(控制器)作用于模型和视图上,控制数据流向模型对象,并在数据变化时更新视图。控制器可以使视图与模型分离开解耦合。
在我的这个系统中,可以分为三个部分:
第一个部分是用过摄像头对视频图像进行采集,将采集到的视频文件传输给服务器中的模型,以供服务器对图像进行分析处理。
主服务器:对采集模块的视频文件进行分析,主要是通过深度学习模型对传过来的模型进行分析处理,将识别来的结果发送给客户端。
客户端:在某一个平台搭建人机交互界面,主要可以展示识别的结果,信息检索,统计和历史数据查询等。用户通过界面查看识别结果,通过界面上的按钮,进行鼠标操作触发一系列动作,系统通过函数实现用户所要求的任务。
三、软件系统概念原型的不同视图以及API
UML类图:
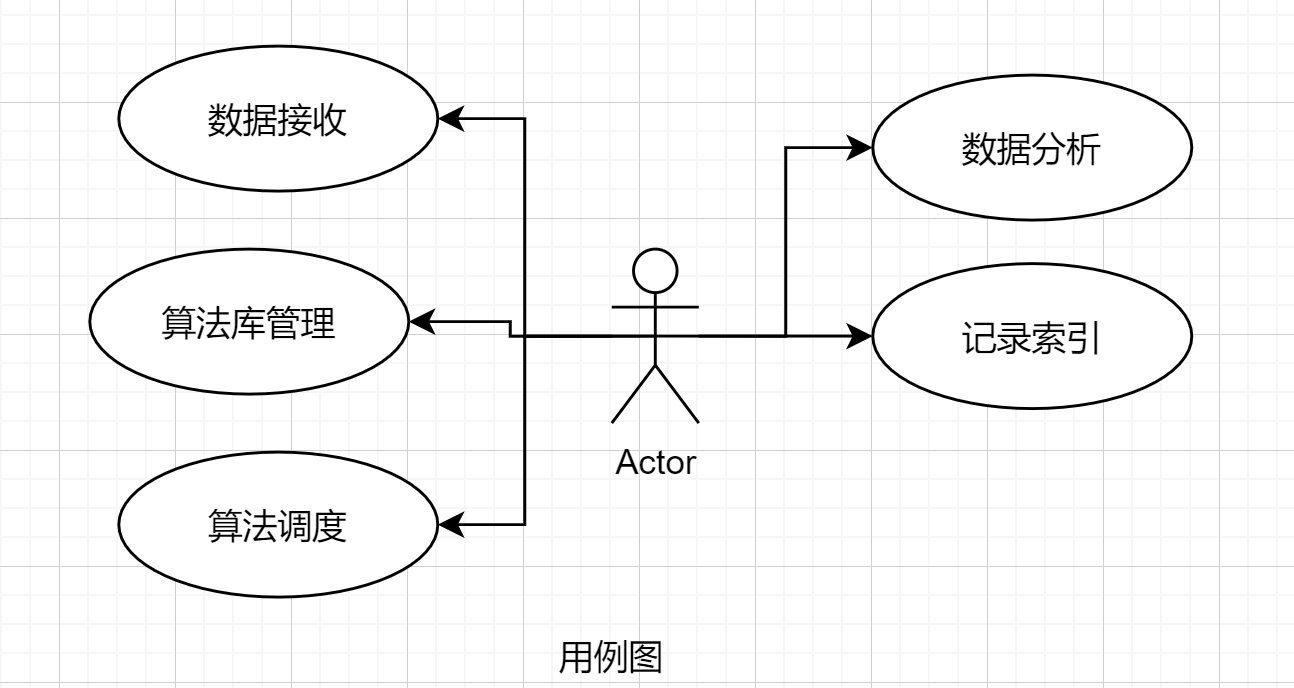
1、分解视图
分解是构建软件架构模型的关键步骤,分解视图也是描述软件架构模型的关键视图,一般分解视图呈现为较为明晰的分解结构特点。分解视图用软件模块勾划出系统结构,往往会通过不同抽象层级的软件模块形成层次化的结构。
2、依赖视图
依赖视图展现了软件模块之间的依赖关系。比如一个软件模块A调用了另一个软件模块B,那么我们说软件模块A直接依赖软件模块B。如果一个软件模块依赖另一个软件模块产生的数据,那么这两个软件模块也具有一定的依赖关系。
依赖视图在项目计划中有比较典型的应用。比如它能帮助我们找到没有依赖关系的软件模块或子系统,以便独立开发和测试,同时进一步根据依赖关系确定开发和测试软件模块的先后次序。
依赖视图在项目的变更和维护中也很有价值。比如它能有效帮助我们理清一个软件模块的变更对其他软件模块带来影响的范围。
在本项目中,要想画出依赖视图,首先要明确项目有哪几个功能模块,然后理清各个功能模块之间的依赖关系,最后只需要把这些依赖关系画出来即可。

3、执行视图
执行视图展示了系统运行时的时序结构特点,比如流程图、时序图等。执行视图中的每一个执行实体,一般称为组件(Component),都是不同于其他组件的执行实体。如果有相同或相似的执行实体那么就把它们合并成一个。
以下是训练过程以及服务端口罩识别的的执行视图。
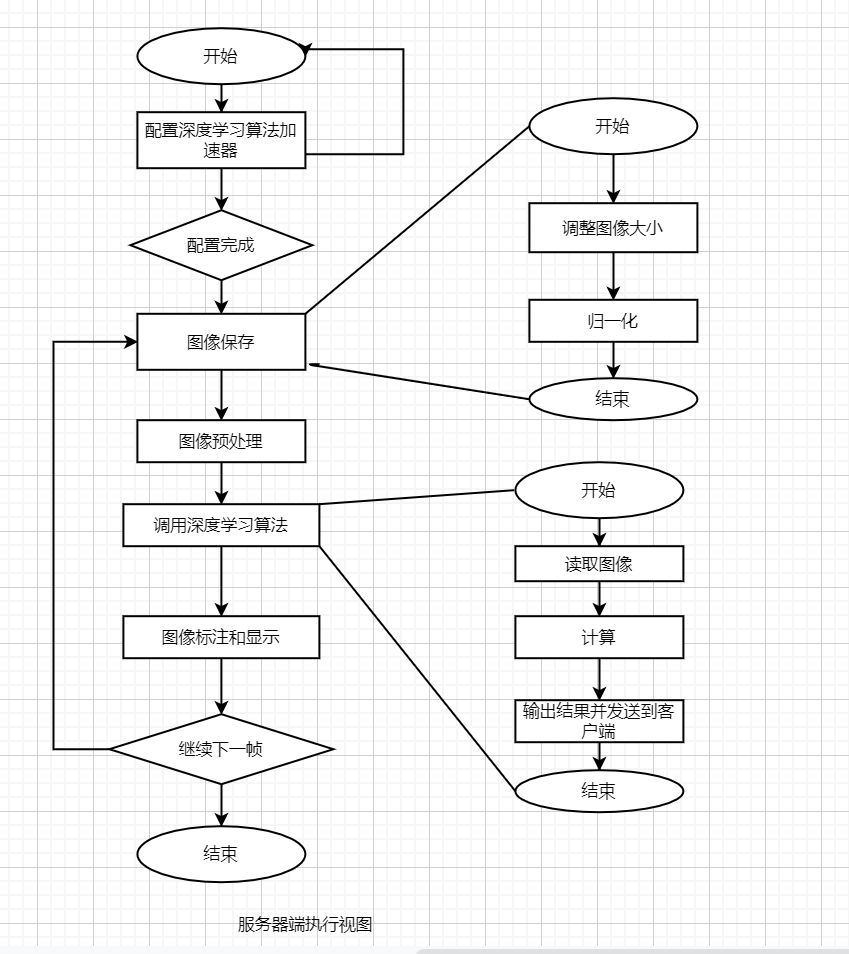
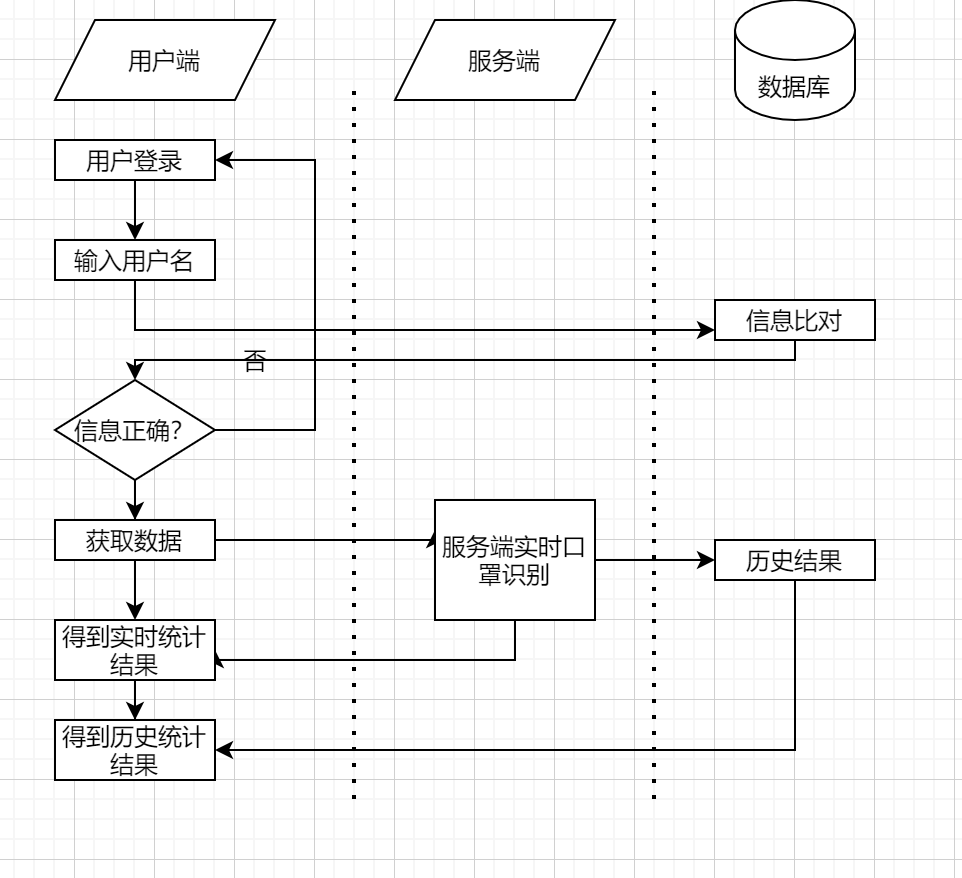
服务端与客户端的执行视图:
4、实现视图
实现视图是描述软件架构与源文件之间的映射关系。比如软件架构的静态结构以包图或设计类图的方式来描述,但是这些包和类都是在哪些目录的哪些源文件中具体实现的呢?一般我们通过目录和源文件的命名来对应软件架构中的包、类等静态结构单元,这样典型的实现视图就可以由软件项目的源文件目录树来呈现。
这里的服务器端口罩识别算法的目录树。
mask_Identification
├─ annotations # 标注信息
├─ convert.py # 参数转换脚本
├─ ImageSets # 图片信息
│ ├─ mask_dataset
│ ├─ test.txt
│ ├─ train.txt
│ ├─ trainval.txt
│ └─ val.txt
├─ LOG # 训练权重存储
│ ├─ train.h5
│ ├─ train_mask_v1.h5
│ └─ train_mask_v2.h5
├─ makeTxt.py
├─ model_data # 模型参数
│ ├─ coco_classes80.txt
│ ├─ mask_anchors.txt
│ ├─ mask_classes.txt
│ ├─ voc_classes.txt
│ ├─ yolo.h5
│ └─ yolo_anchors.txt
├─ train.py # 加载权重进行预测
├─ yolo.py
├─ yolo3 # yolov3模型
│ ├─ model.py
│ ├─ utils.py
│ ├─ __init__.py
5、工作分配视图
工作分配视图将系统分解成可独立完成的工作任务,以便分配给各项目团队和成员。工作分配视图有利于跟踪不同项目团队和成员的工作任务的进度,也有利于在各项目团队和成员之间合理地分配和调整项目资源,甚至在项目计划阶段工作分配视图对于进度规划、项目评估和经费预算都能起到有益的作用。
由于这是设想的项目,所以并没有实际的进程。以下是设想的对于一个完整系统的工作分配:
| 任务 | 预计周期 | 状态 |
|---|---|---|
| 数据预处理,数据清洗 | 0.5个月 | 已完成 |
| 模型的搭建和调整 | 1个月 | 已完成 |
| 权重训练和微调 | 1个月 | 已完成 |
| 模型的部署和上线 | 1个月 | 进行中 |
| 后台数据模块管理 | 1个月 | 尚未开始 |
6. 服务器端口罩识别算法接口:
- 模型定义:
class yolo
定义模型主体yolo_body(inputs, num_anchors, num_classes)、
损失函数box_iou(b1, b2)
评价标准 yolo_loss(args, anchors, num_classes, ignore_thresh=.5, print_loss=False)。
- 模型搭建:
create_model(input_shape, anchors, num_classes, load_pretrained,freeze_body,weights_path)
参数:输入图片大小,标注框尺寸、是否加载预训练权重、冻结层数、预训练权重;
-
图像预处理
class utils将输入的图像预处理。
-
图像生成:
data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes)
- 模型预测:
class YOLO
提供模型参数的加载(模型权重、先验框、分类)、调用摄像头进行预测输出
四、项目数据库设计
User(客户端用户)
| 属性 | 数据类型 | 约束 | 描述 |
|---|---|---|---|
| userId | String | 主键 | ID |
| String | 邮箱 | ||
| registerDate | Date | 注册日期 |
ModelData(训练用数据)
| 属性 | 数据类型 | 约束 | 描述 |
|---|---|---|---|
| pictureID | int | 主键 | 训练用图片 |
| addr | String | 图片位置 | |
| tag | int | 标签值 | |
| box | float | 标注框 |
Result(返回结果)
| 属性 | 数据类型 | 描述 |
|---|---|---|
| faceID | int | 识别人脸编号 |
| result | int | 返回预测结果(0,1) |
| Time | TimeStamp | 时间戳 |
五、系统运行环境和技术选型说明
运行环境
TensorFlow-GPU 2.3.0
Keras 2.4.3
Python 3.7.4
opencv-python==4.4.0.46
h5py==2.10.0
Intel(R) Core(TM) i3-10100F CPU @ 3.60GHz
GeForce RTX 2080 Ti
六、概念原型的核心工作机制
本项目概念原型的核心工作机制如下,从两方面阐述:
从服务端角度,包含了口罩识别以及后台框架模块。其中服务端使用python编写,结合keras、tensorflow等深度学习框架来实现。通过对数据采集模块传输过来的视频文件进行分析处理,包括视频的预处理、口罩识别等工作,通过TCP/IP传到客户端。
客户端可以获得服务端返回的数据,以获得口罩佩戴的信息。主要可以查询在时间戳下用户佩戴口罩的数据,并且对于没有佩戴口罩的情况做出预警。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号