
Volatile
Volatile
一、前言:
Java 内存模型中的可见性、原子性和有序性。
可见性:
可见性是一种复杂的属性,因为可见性中的错误总是会违背我们的直觉。通常,我们无法确保执行读操作的线程能适时地看到其他线程写入的值,有时甚至是根本不可能的事情。为了确保多个线程之间对内存写入操作的可见性,必须使用同步机制。
可见性,是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的。也就是一个线程修改的结果。另一个线程马上就能看到。比如:用volatile修饰的变量,就会具有可见性。volatile修饰的变量不允许线程内部缓存和重排序,即直接修改内存。所以对其他线程是可见的。但是这里需要注意一个问题,volatile只能让被他修饰内容具有可见性,但不能保证它具有原子性。比如 volatile int a = 0;之后有一个操作 a++;这个变量a具有可见性,但是a++ 依然是一个非原子操作,也就是这个操作同样存在线程安全问题。
在 Java 中 volatile、synchronized 和 final 实现可见性。
原子性:
原子是世界上的最小单位,具有不可分割性。比如 a=0;(a非long和double类型) 这个操作是不可分割的,那么我们说这个操作时原子操作。再比如:a++; 这个操作实际是a = a + 1;是可分割的,所以他不是一个原子操作。非原子操作都会存在线程安全问题,需要我们使用同步技术(sychronized)来让它变成一个原子操作。一个操作是原子操作,那么我们称它具有原子性。java的concurrent包下提供了一些原子类,我们可以通过阅读API来了解这些原子类的用法。比如:AtomicInteger、AtomicLong、AtomicReference等。
在 Java 中 synchronized 和在 lock、unlock 中操作保证原子性。
有序性:
Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性,volatile 是因为其本身包含“禁止指令重排序”的语义,synchronized 是由“一个变量在同一个时刻只允许一条线程对其进行 lock 操作”这条规则获得的,此规则决定了持有同一个对象锁的两个同步块只能串行执行。
二、特征
1、保证线程可见性
- MESI
- 缓存一致性协议
2、禁止指令重排序(CPU)
- DCL单例
- Double Check Lock
- Mgr06.java --loadfence原语指令 --storefence原语指令
线程可见性举例代码:没加volatile,循环不能终止
加了volatile。“m start”——>“m end!”
package com.mashibing.testvolatile; public class T01_ThreadVisibility { private static volatile boolean flag = true; public static void main(String[] args) throws InterruptedException { new Thread(()-> { while (flag) { //do sth } System.out.println("end"); }, "server").start(); Thread.sleep(1000); flag = false; } }
三、相关知识
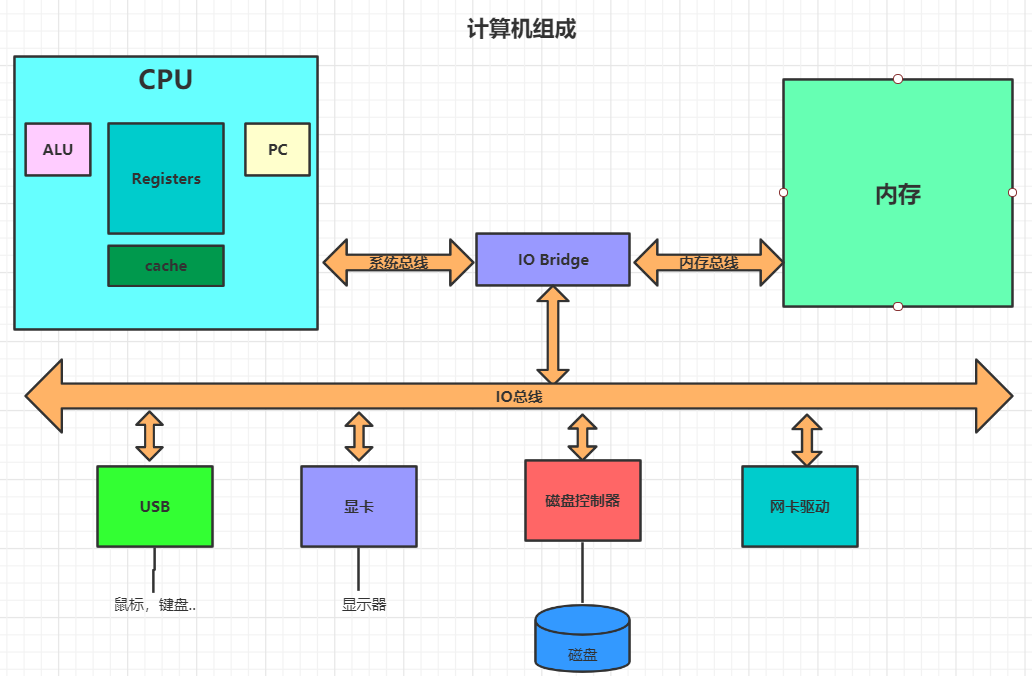
Registers:寄存器
ALU:逻辑运算单元
PC:指令寄存器
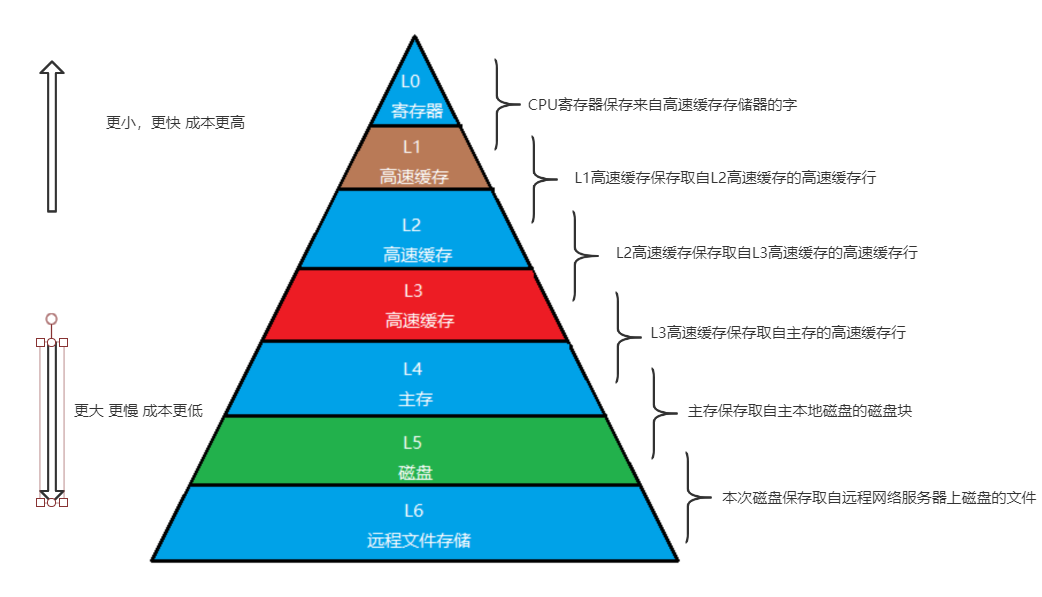
存储器的层次结构
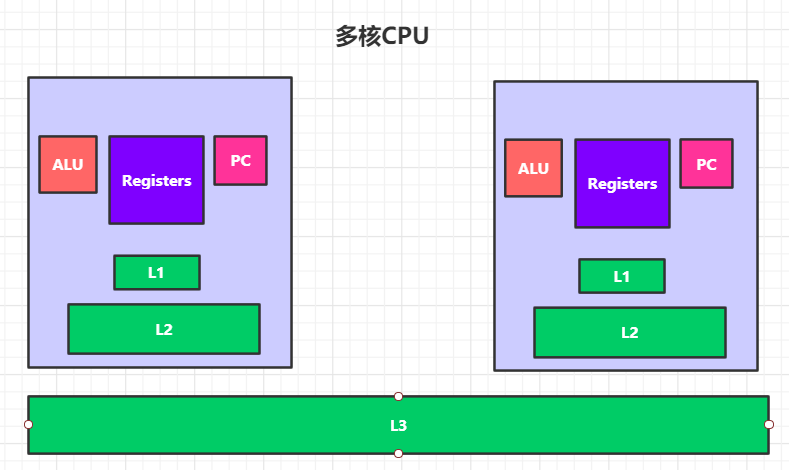
超线程:一个ALU对应多个PC/Registers( 所谓的四核八线程)。
线程是CPU执行的基本单位
进程是CPU分配资源的基本单位
四、cache line的概念 缓存行对齐伪共享
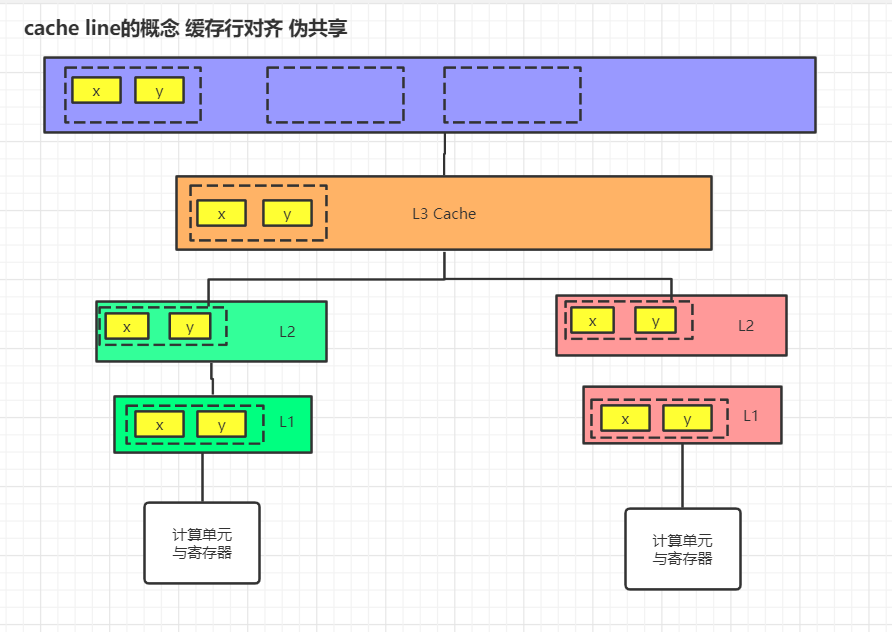
CPU到主内存,之间要经过多层缓存(L1,L2,L3)
举例:
1. 想找数据x,先到缓存L1找,没有就到L2,还没有就到L3,L3没有就要从主存中读到内存L3中,再读到L2,再读到L1。
2. 主存读数据不光读x,而是按块读,比如读x,y这一块。
3. 因为是按块读,所以如果找数据y,就可以在L1中直接找到。
一个缓存行64字节
在CPU层级 数据的一致性是以缓存行为单位的。
代码示例:

执行需要200多毫秒
修改代码:
package com.mashibing.juc.c_028_FalseSharing; public class T02_CacheLinePadding { private static class Padding { public volatile long p1, p2, p3, p4, p5, p6, p7; // } private static class T extends Padding { public volatile long x = 0L; } public static T[] arr = new T[2]; static { arr[0] = new T(); arr[1] = new T(); } public static void main(String[] args) throws Exception { Thread t1 = new Thread(()->{ for (long i = 0; i < 1000_0000L; i++) { arr[0].x = i; } }); Thread t2 = new Thread(()->{ for (long i = 0; i < 1000_0000L; i++) { arr[1].x = i; } }); final long start = System.nanoTime(); t1.start(); t2.start(); t1.join(); t2.join(); System.out.println((System.nanoTime() - start)/100_0000); } }
修改以后x,y都独占一行。因为添加了p1-p7 已经64字节了。
执行需要80多多毫秒
这种写法叫做缓存行对齐。
典型框架:Disruptor(环形队列,MQ)不需要做判断,全世界最快的单机MQ。
底层除了是环形队列,还有就是用了缓存行对齐。
源码:![]()
前后都堆了7个long值,这样cursor始终独占一行。
缓存行:
缓存行越大,局部性空间效率越高,但读取时间慢。
缓存行越小,局部性空间效率越低,但读取时间快。
取一个折中值,目前多用:64字节
CPU是可以做到缓存行之间做到一致性
五、MESI一致性协议
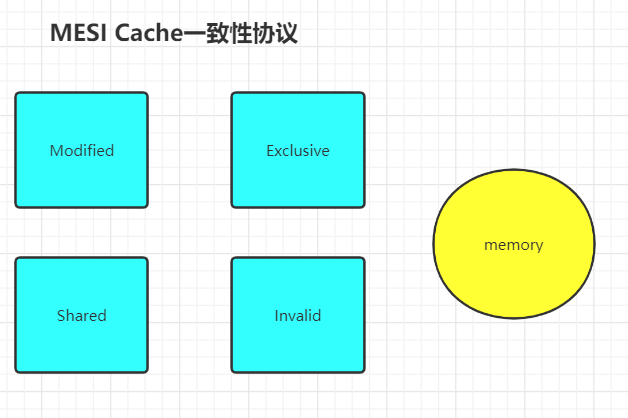
MESI协议将cache line的状态分为modify、exclusive、shared、invalid分别是修改、独占、共享、失效
| 状态 | 描述 |
|---|---|
| M(modify) | 当前CPU刚修改完数据的状态,当前CPU拥有最新数据,其他CPU拥有失效数据,而且和主存数据不一致 |
| E(exclusive) | 只有当前CPU中有数据,其他CPU中没有改数据,当前CPU的数据和主存的数据是一致的 |
| S(shared) | 当前CPU和其他CPU中都有共同的数据,并且和主存中的数据一致; |
| I(invalid) | 当前CPU中的数据失效,数据应该从主存中获取,其他CPU中可能有数据也可能无数据;当前CPU中的数据和主存中的数据被认为不一致。 |
M和E状态下的Cache Line数据是独有的,不同点在于M状态的数据时dirty和内存的不一致,E状态下数据和内存是一致的;
六、指令重排序
package com.mashibing.jvm.c3_jmm; public class T04_Disorder { private static int x = 0, y = 0; private static int a = 0, b =0; public static void main(String[] args) throws InterruptedException { int i = 0; for(;;) { i++; x = 0; y = 0; a = 0; b = 0; Thread one = new Thread(new Runnable() { public void run() { //由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间. //shortWait(100000); a = 1; x = b; } }); Thread other = new Thread(new Runnable() { public void run() { b = 1; y = a; } }); one.start();other.start(); one.join();other.join(); String result = "第" + i + "次 (" + x + "," + y + ")"; if(x == 0 && y == 0) { System.err.println(result); break; } else { //System.out.println(result); } } } public static void shortWait(long interval){ long start = System.nanoTime(); long end; do{ end = System.nanoTime(); }while(start + interval >= end); } }
系统底层如何实现数据一致性
1.MESI如果能解决,就使用MESI
2.如果不能,就锁总线
系统底层如何保证有序性
1.内存屏障sfence mfence lfence等系统原语(不具备可移植性)
2.锁总线
volatile如何解决指令重排序(5个层级)
1.volatile i(源码层级)
2.ACC_VOLATILE(字节码层级)
3.JVM的内存屏障(JVM层级)
JVM规范:对volatile的读写前后都要加屏障
屏障两边的指令不可以重排!保障有序!


4.hotspot实现
int field_offset = cache->f2_as_index(); if (cache->is_volatile()) { if (support_IRIW_for_not_multiple_copy_atomic_cpu) { OrderAccess::fence(); }
orderaccess_linux_x86.inline.hpp(C++)关键字还是 lock (支持多种cpu 具备可移植性)
inline void OrderAccess::fence() { if (os::is_MP()) { // always use locked addl since mfence is sometimes expensive #ifdef AMD64 __asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory"); #else __asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory"); #endif } }
5.电信号层级(省略)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号