
CAS、Synchronized
高并发——CAS、Synchronized、Volatile
一、CAS(无锁优化、自旋、乐观锁)
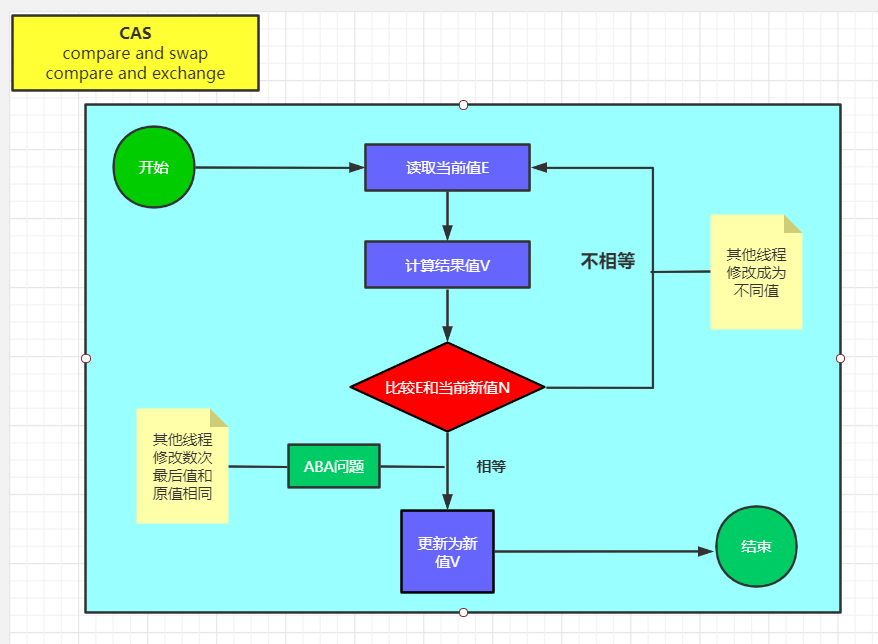
Compare and Set/Swap 比较并交换
- CAS(V,Expected,NewValue)
1. CAS在JAVA最终底层的实现:cmpxchg=cas修改变量值。
2. CAS操作在底层上有一条对应的汇编指令(硬件级别):lock cmpxchg。
3. 多个CPU的话前面要加lock。
4. Cmpxchg指令是非原子性,加上Lock 就保证了原子性 。
5. Synchronized和volatile的底层都有lock指令。
- ABA问题 ----加version
二、Synchronized的实现
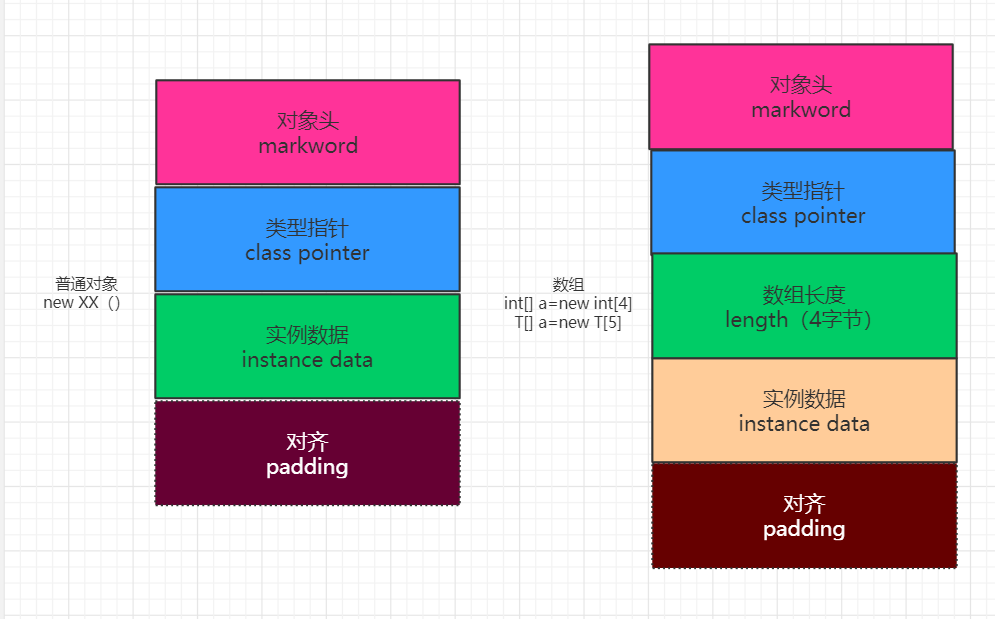
1. 对象在内存中的存储布局:
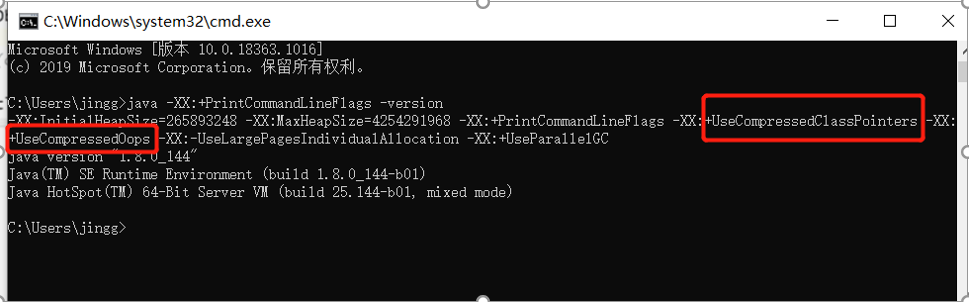
java -XX:+PrintCommandLineFlags -version
2.工具查看对象在内存中大小
JOL=Java Object Layout
导入依赖
<dependencies>
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
</dependencies>
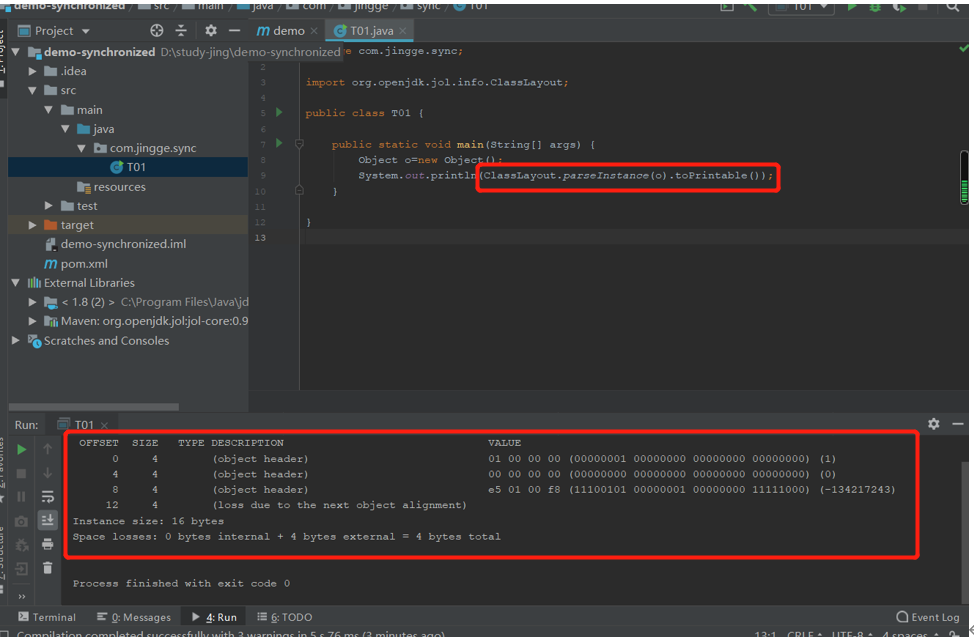
Markword:8
Classpointer:4 本来是8开启指针压缩变4
Instance date:0
Padding:4 补齐至被8整除
Object o =new Object()在内存中占16字节
下图可以看出,锁信息是在markword中
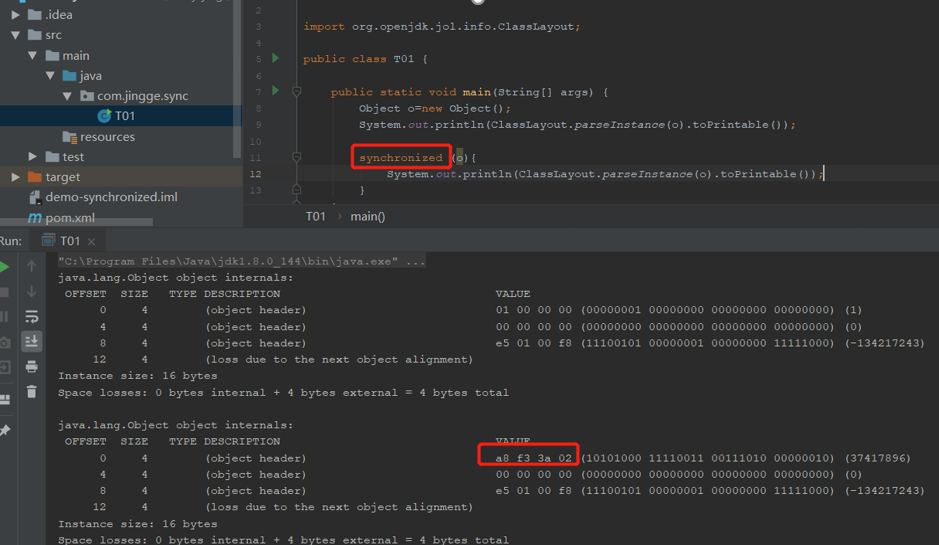
3.锁升级过程
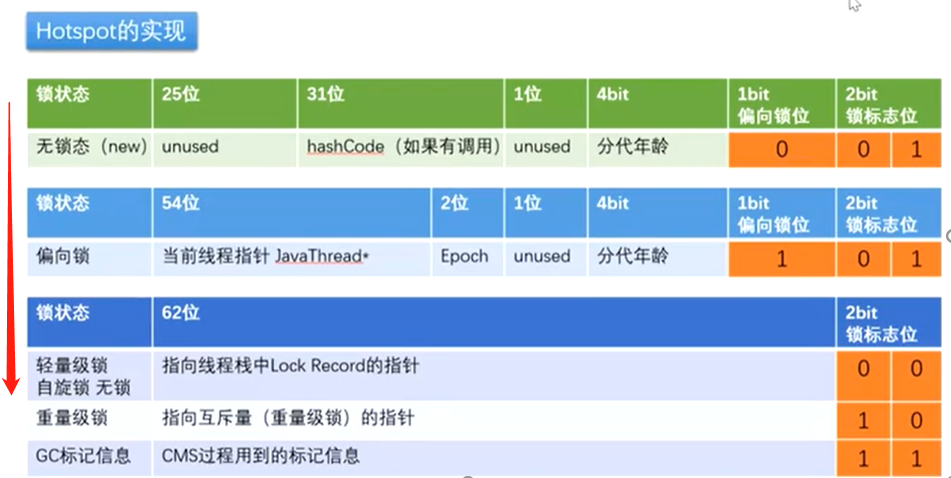
锁升级过程:
new ——>>偏向锁——>>轻量级锁(无锁,自旋锁,自适应自锁) ——>>重量级锁
synchronized优化的过程和markword息息相关。
new:刚new出来对象,没有给它上锁。
偏向锁:;来了一个线程上去直接“贴个标签(线程ID)”,后面可能还是这个线程。(效率高,无竞争)。
轻量级锁(自旋锁):来线程竞争了,撤销偏向锁,升级轻量级锁,线程都有自己的线程栈,在自己线程栈里生成各自的对象:lockrecord。
抢的过程是CAS操作,看谁能将自己的lockrecord“贴上去”。用CAS操作讲markword设置为指向自己这个想成的LR的指针。
重量级锁:竞争加剧,有线程超过10次自旋,或者自选线程数超过CPU核数的一半,JVM自己控制。升级为重量级锁(向操作系统申请资源)
每一个重量级锁下面有一个队列,锁升级成功相当于进入了锁的队列,在队列里如果没轮到线程执行就不会消耗CPU,线程在wait或阻塞状态。
每个线程都进入队列中“冻死”,什么时候轮到对应的线程,就将其“解冻”。
锁消除 lock eliminate

我们都知道StringBuffer是线程安全的,因为它的关键方法都是被synchronized修饰,但我们看上面
这段代码,我们会发现,sb这个引用只会在add方法中使用,不可能被其他线程引用(因为是局部变
量,栈私有),因此sb是不可能共享的资源,JVM会自动消除StringBuffer对象内部的锁。
锁粗化 lock coarsening
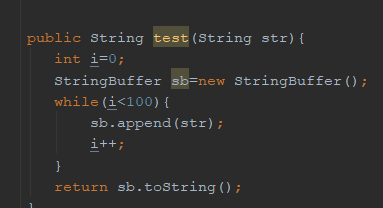
JVM会检测到这样一连串的操作,都对同一个对象加锁(while 循环内100次执行append,没有锁
粗化的就会进行100次加锁/解锁),此时JVM就会将加锁的范围粗化到这一连串的操作的外部(比如
while虚幻体外),使得这一连串操作只需要加一次锁即可。
实验(需要安装插件):
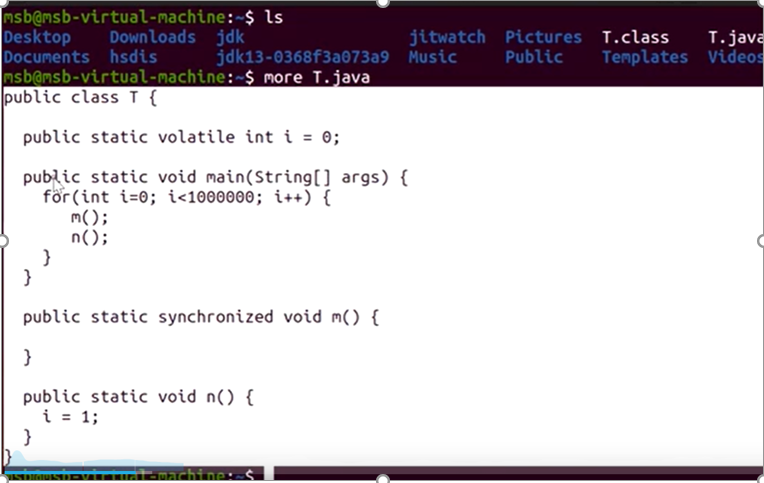
JIT:Just In Time Compiler 即时编译
将热点代码做即时编译,直接编译成机器语言。效率可以高很多
总结:
Synchronized实现过程
1. java代码:synchronized
2.monitorenter moniterexit
3.执行过程中自动升级
4.lock comxchg
扩充知识:
一、解决同样更搞笑的方法,使用AtomXXX类
AtoXXX类本身方法都是原子性的,但不能保证多个方法连续调用时原子性的
代码示例:
public class T02_AtomicInteger { /*volatile*/ //int count=0; AtomicInteger count= new AtomicInteger(0); /*synchronized*/void m(){ for (int i = 0; i <10000 ; i++) { count.incrementAndGet();//count++ } } public static void main(String[] args) { T02_AtomicInteger t=new T02_AtomicInteger(); List<Thread> threads=new ArrayList<>(); for (int i = 0; i <10 ; i++) { threads.add(new Thread(t::m,"thread-"+i)); } threads.forEach((o)->o.start()); threads.forEach((o)->{ try { o.join(); } catch (InterruptedException e) { e.printStackTrace(); } }); System.out.println(t.count); }
点进去AtomicInteger 可以看到Unsafe类(此类java11以后已关闭):
Unsafe=C C++的指针
- 直接操作内存 - allcateMemory putXX freeMemory pageSize
- 直接生产类实例 - allocateInstance
- 直接操作类或实例变量 - objectFieldOffset -getInt -getObject
- CAS相关操作:weakCompareAndSetObject Int Long
二、synchronized优化
同步代码块中的语句越少越好,
示例代码 比较m1 m2:
public class FineCoarseLock { int count=0; synchronized void m1() { //do sth neew not sync try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } //业务逻辑中只有下面这句需要sync,这时不应该给整个方法加sync count++; //do sth neew not sync try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } void m2(){ //do sth neew not sync try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } //业务逻辑中只有下面这句需要sync,这时不应该给整个方法加sync //采用细粒度的锁,可以使线程争用时间变短,从而提高效率。 synchronized (this){ count++; } //do sth neew not sync try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } }
三、synchronized可以保证可见性和原子性,volatile只能保证可见性
public class T03 { /*volatile*/ int count=0; synchronized void m(){ for (int i=0;i<10000;i++){ count++; } } public static void main(String[] args) { T03 t=new T03(); List<Thread> threads=new ArrayList<>(); for (int i = 0; i <10 ; i++) { threads.add(new Thread(t::m,"thread-"+i)); } threads.forEach((o)->o.start()); threads.forEach((o)->{ try { o.join(); } catch (InterruptedException e) { e.printStackTrace(); } }); System.out.println(t.count); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号