一步一步做搜索(一)
感谢枫伶忆
http://www.cnblogs.com/fenglingyi/p/4708006.html
自从了解到搜索优化,分词和权重之后,一直苦于没有结构化的培训数据来做搜索,现在总算可以体验一把了。枫伶忆大大发表博客后半天时间 我就开始在博客园上爬数据,结果爬了一晚上才爬了12w条数据存到数据库,还是比较担心博客园崩溃的,毕竟可以预想到,会有多少人同时开始在博客园爬数据了,嘿嘿 还好没啥事。
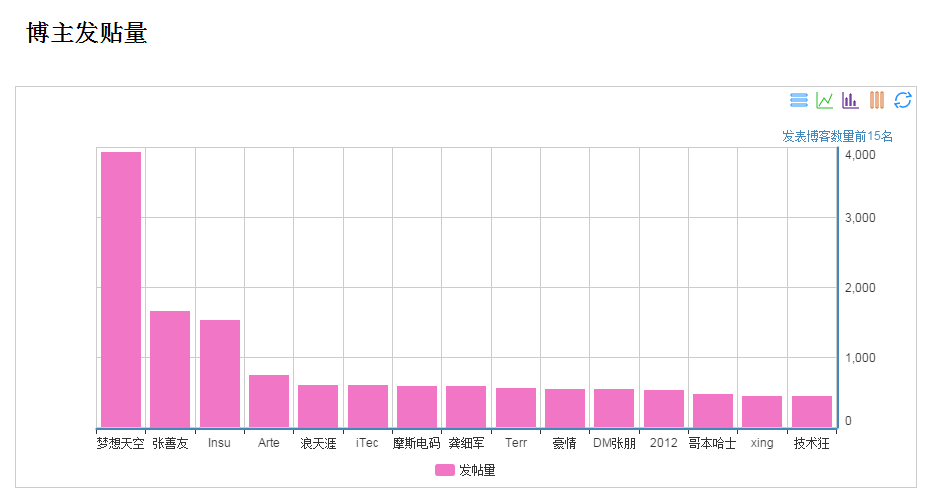
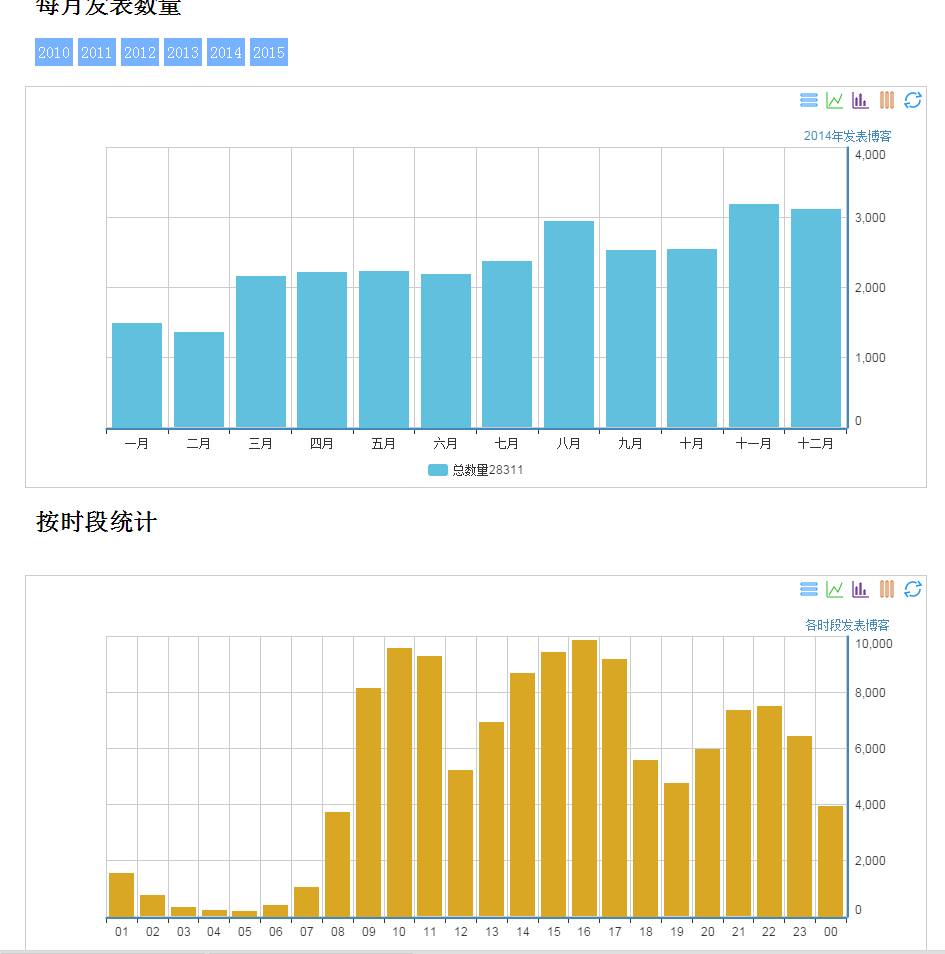
刚把图表做出来时别提有多激动了,成就感啊。慢慢的发现然并卵啊。不过我的初衷不是这个,我还是要做搜索,现在数据有了,那就开工呗。
一开始我就按普通查询来搜索数据库,发现模糊搜索并不能令我满意,再对比一下百度,完全就是渣啊。然后就有了分词的想法,想到就做
char[] slist = keyword.ToCharArray();
将输入关键字分解成一个个字符,然后去拼接sql,结果自然不满意 因为查到的数据太杂乱了 再对比下百度,还是渣啊。怎么办呢 为毛人家搜索出来的东西就是准确率那么高呢,我想到了权重 然后大量查资料,得到了如下的sql
SELECT TOP 15 BlogTitle,BlogTime,BlogUrl FROM BlogActicle WHERE (BlogId >(SELECT MAX(BlogId) FROM (SELECT TOP 20 BlogId FROM BlogActicle ORDER BY BlogId) AS T ) ) and BlogTitle like '%" + keyword + "%'" + substr + " ORDER BY (case when BlogTitle like '%" + keyword + "%' then 3 when BlogTitle like '%" + (keyword.Length > 1 ? slist[0] + slist[1] : slist[0]) + "%' then 2 when BlogTitle like'%" + slist[0] + "%'" + substr + " then 1 end ) desc
我将权重设为3级 完全匹配关键字的 设为3 匹配2个字的设为2 匹配一个就为1 然后将权重排序 便会将权重最高的排在前
然后再对比百度,尼玛 人家关键字是高亮显示,费了一番功夫 从网上剽窃下来一段代码
//切词替换成高亮
public static string HighlightKeyword(string str, char[] keywordValues)
{
int index;
string highlightBegin = "<>";
string highlightEnd = "</>";
for (int i = 0; i < keywordValues.Length; i++)
{
int startIndex = 0;
int length = highlightBegin.Length + keywordValues[i].ToString().Length;
int lengthHighlight = length + highlightEnd.Length;
var temp = str.ToLower();
var temp1 = keywordValues[i].ToString().ToLower();
while((index = str.IndexOf(keywordValues[i].ToString(), startIndex, StringComparison.OrdinalIgnoreCase)) > -1)
{
str = str.Insert(index, highlightBegin).Insert(index + length, highlightEnd);
startIndex = index + lengthHighlight;
}
}
//将<>字符串替换<em>
str = str.Replace("<>", "<em>").Replace("</>", "</em>");
return str;
}
最后得到效果图如下:

看到logo和样式是不是很熟悉呀,没错,就是百度的样式被我扒下来了。
接下来有做了用户输入历史记录匹配
然后再去看本地的txt文件里面都是我的输入记录,不禁感觉有点后怕,尼玛 平常用搜索引擎查东西 百度和浏览器 手机UC 记录了我多少个人记录,太没安全感了 。
接下来地球人已经阻挡不了我要做全文搜索了。但是数据库数量太多 单个字段 表查还好,全局那不得龟速啊 怎么办呢,经常逛博客园 当然知道 检索神器Lucene 了。还有盘古分词

 浙公网安备 33010602011771号
浙公网安备 33010602011771号