
我们知道,Kubernetes是Google根据自己的Borg系统,采用go语言重构诞生的,那么我们可以先看看Borg系统的架构。
1、Borg系统架构解读
Borg是一个C++写的的集群管理系统,它负责权限控制、调度、启动、重新启动和监视全部的Google中运行的应用程序。其高可用架构如下所示:
-
BorgMaster是整个集群的大脑,负责维护整个集群的状态,并将数据持久化到Paxos存储中;
-
Scheduer负责任务的调度,根据应用的特点将其调度到具体的机器上去;
-
Borglet负责真正运行任务(在容器中);
-
borgcfg是Borg的命令行工具,用于跟Borg系统交互,一般通过一个配置文件来提交任务。

它有三个好处:
-
隐藏资源管理和故障处理的细节,因此其用户可以专注于应用程序开发;
-
提供高可靠性和高可用性操作,支持的应用也是如此;
-
使我们能够有效地在数万台机器上运行工作负载。
由上图可知Borg的中心控制模块叫BorgMaster(包含主进程、调度器), 每个节点模块叫Borglet,所有组件均使用C++编写。
1.1、borgmaster主进程
BorgMaster主进程负责处理客户端RPC调用(支持包括web浏览器、命令行工具、borgcfg方式),管理系统中所有对象的状态机,与borglet进行通信。
BorgMaster在逻辑上是一个进程,但是有5个副本(单数),每个副本都维护cell状态的一份内存副本,cell状态同时在高可用、分布式、基于Paxos的存储系统中做本地磁盘持久化存储。
一个单一的被选举的master既是Paxos leader, 也是状态管理者。当cell启动或者被选举master挂掉时,系统会选举Borgmaster,选举机制按照Paxos算法流程进行。选举master的过程通常会消耗10秒,在一些规模较大的cell会消耗1分钟左右。
BorgMaster的状态会定时设置checkpoint, 具体形式就是在Paxos store中存储周期性的镜像snapshot和增量更改日志。其作用可以存储borgmaster的状态,修复问题,离线模拟等。
1.2、scheduling调度器
一个Borg作业Job具有name、owner、task数量等属性,Job具有约束性来强制其任务运行在特定属性的机器上。
当job被提交时,borgmaster会将其记录到paxos store中,并将task增加到等待队列中,调度器通过异步的方式扫描队列将机器分配给任务并持久化到paxos(persistent store)中,调度过程主要包括可行性检查和打分。
可行性检查主要用于解决硬约束,找到一组满足硬约束的机器;打分则是满足软约束,在可行的机器中根据用户偏好为机器打分,用户偏好主要是系统内置的标准,如:被抢占的task的优先级和数量最小化,具有任务软件包的机器、 分散任务到不同的失败域中,将高优先级和低优先级的task分配到同一个node上,使得高优先的任务可以抢占低优先级的任务等。
borgmaster一开始使用E-PVN进行打分,其会将任务分散到不同的机器上,称为worst fit;而best fit会尽量使用紧凑的机器以減少资源碎片。考虑到系统中不同类型任务单额资源需求,采用混合的模型进行打分。
如果对于—个新task没有充足的资源、那么系统会杀死低优先级的任务,杀死的低优先级的任务会被放置在等待队列中。任务启动延迟平均在25秒,有80%的时间花费在包安装上。因此在调度的时候尽量把任务调度在含有包的机器上,同时因为包是不变的,所以可以共享和缓存,同时还提供了一些并行分发包的协议。
1.3、Borglet
borglet是运行在每台机器上的代理,负责启动和停止task、重启任务、管理本地资源、向master和监控模块汇报自己的状态。master会周期性的向boralet拉取其当前的状态.这样做能够控制通信速度避免"恢复风暴”。
为了性能扩展,master副本会运行一个无状态的link shard去处理与部分borglet的通信,但重新选举时会重新分区,master副本会聚合和压缩信息,向被选举的master报告状态机的不同部分,减少更新负担。如果borglet多轮都没有进行响应会被标记为down。运行在上面的任务会被重新调度至其他机器,如果通信恢复,master会通知boralet杀死已经重调度的任务保证一致性。
解读:borglet的设计与其他调度系统相同,提供汇报功能。不同的是borg中采用拉取的方式进行,也就是borglet主动去paxos拉取属于自己的任务。另外borg中的副本会与一些borglet通信以此方式来减少更新负担。
1.4、Kubernetes吸取的优缺点
-
在Borg中,Job是用来对task进行分组的唯一方式,这种方式相当不灵活,导致用户自己发展出很多方式来实现更灵活对分组。Kuberntes吸取了Borg的这个教训,引入了Labels,使Pod可以被灵活地分组。
-
在Borg中,1个node 上的所有task共享node的ip,这直接导致端口也成为一种资源,在调度时候需要被考虑。Kubernetes为每个Pod分配独立的P。
-
Kubernetes借鉴了 Alloc (node上的一块可以被多个task共享的资源),设计了Pod (多个容器的封装)。这种设计,可以将1个pod中的任务分拆成不同 的容器,由不同的团队开发,特别是一些辅助性的任务,例如日志采集等。
-
Borg中task、job的命名机制被kubernetes借鉴,提供了service等特性。
-
Borg将系统内部的事件、task的日志暴露给用户,提供了不同级别的UI和调试工具,使几千个用户能够自助地使用Borg。Kubernetes吸收了Borg的这些特性,引入cAdvisor、Elasticsearch/Kibana、Fluentd等组件。
-
Borg采用中心式设计,管理功能集中于Master,这种设计方便了后续更多特性引入以及规模的扩展。Kubernetes更进一步,apiserver只负责处理请求和状态维护,集群的管理逻辑被拆分到多个更精悍、内聚的controller中。
2、 Kubernetes组件说明
2.1、Kubernetes整体架构
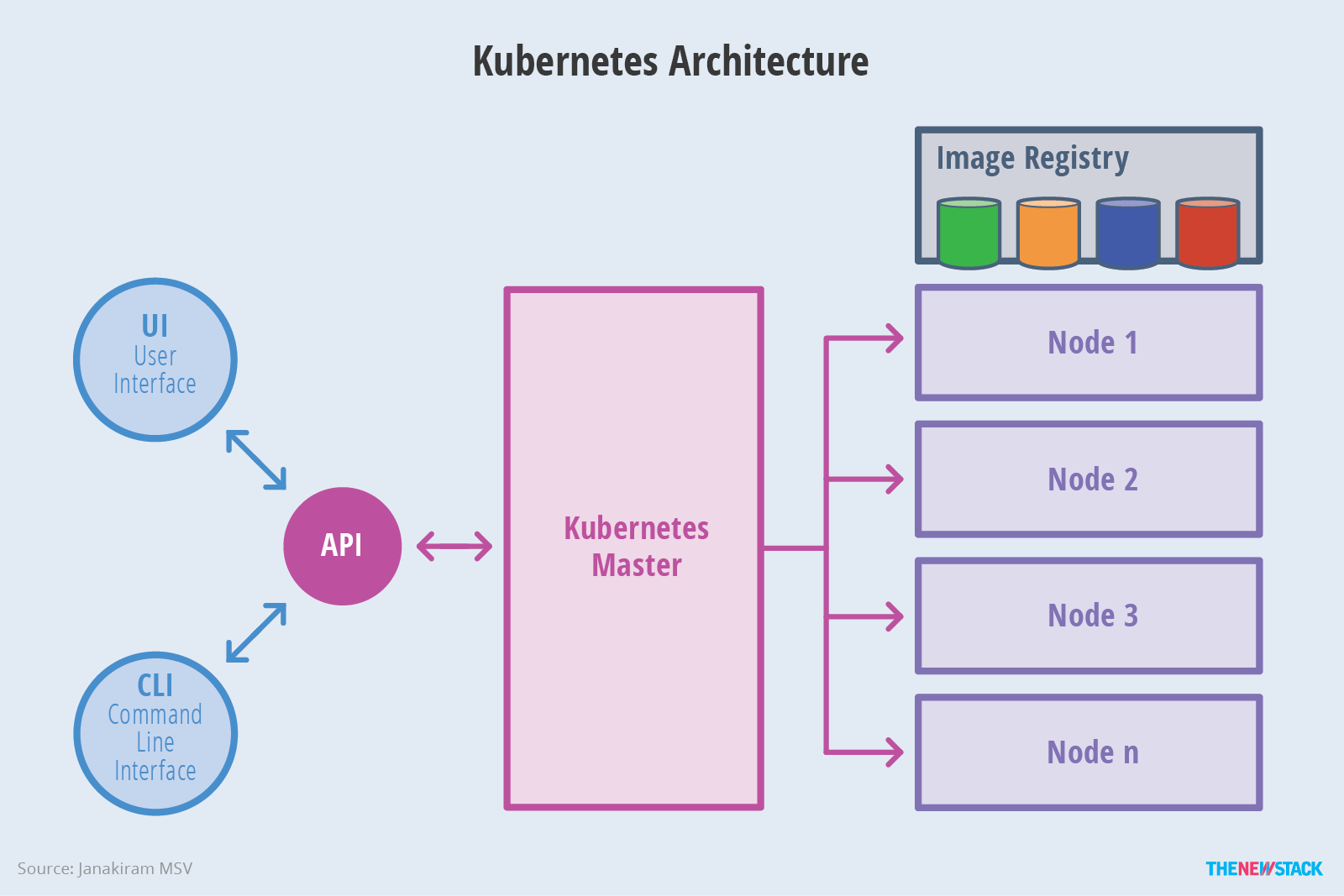
Kubernetes 提供了一种灵活、松耦合的机制,与大多数分布式计算平台一样,Kubernetes 集群由至少一个主节点和多个计算节点组成。master负责公开应用程序接口(API)、调度部署和管理整个集群。每个节点运行一个容器,例如Docker或rkt,与主服务器进行通信。如下图所示:
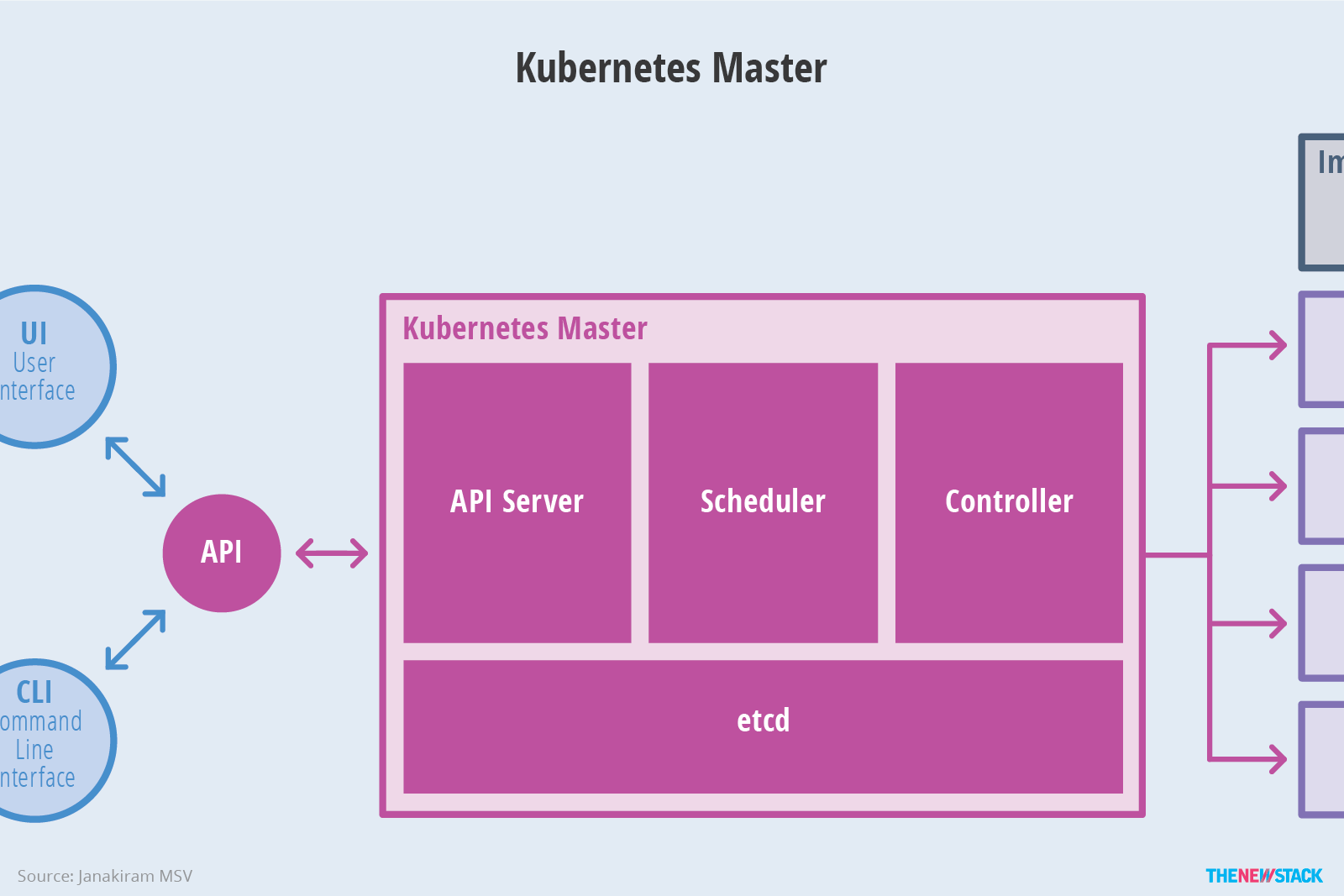
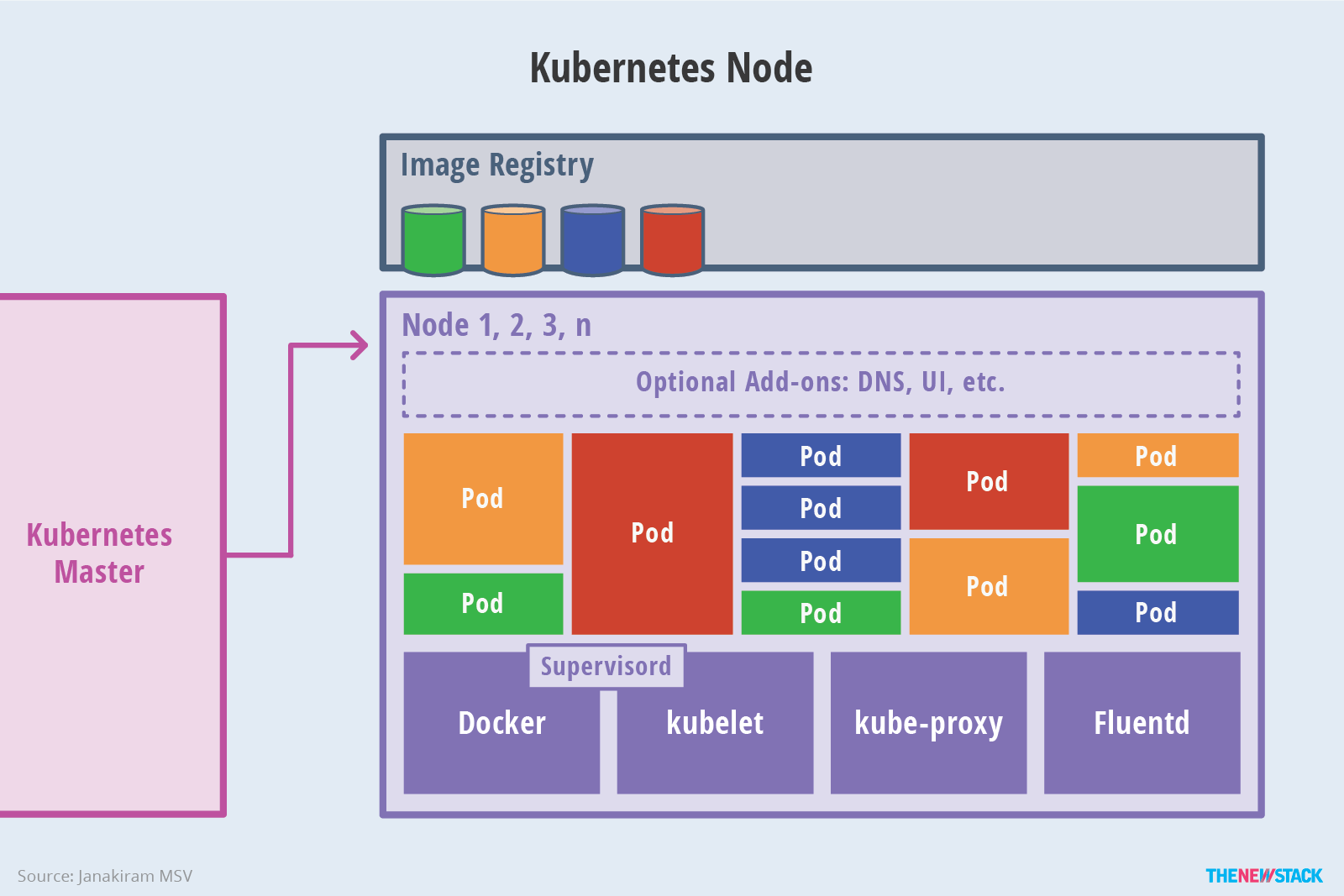
节点是 Kubernetes 集群的主力。它们对应用程序暴露自己的计算、网络和存储资源。节点可以是在云中运行的虚拟机 (VM),也可以是在数据中心内运行的裸机服务器。同时节点还可运行用于日志记录、监控、服务发现和其余可选的附加组件。如下图所示:
2.2、Kubernetes组件概述
Kubernetes借鉴了Borg的设计理念,比如Pod、Service、Label和单Pod单IP等。Kubernetes的整体架构跟Borg非常像,官方的如下图所示:
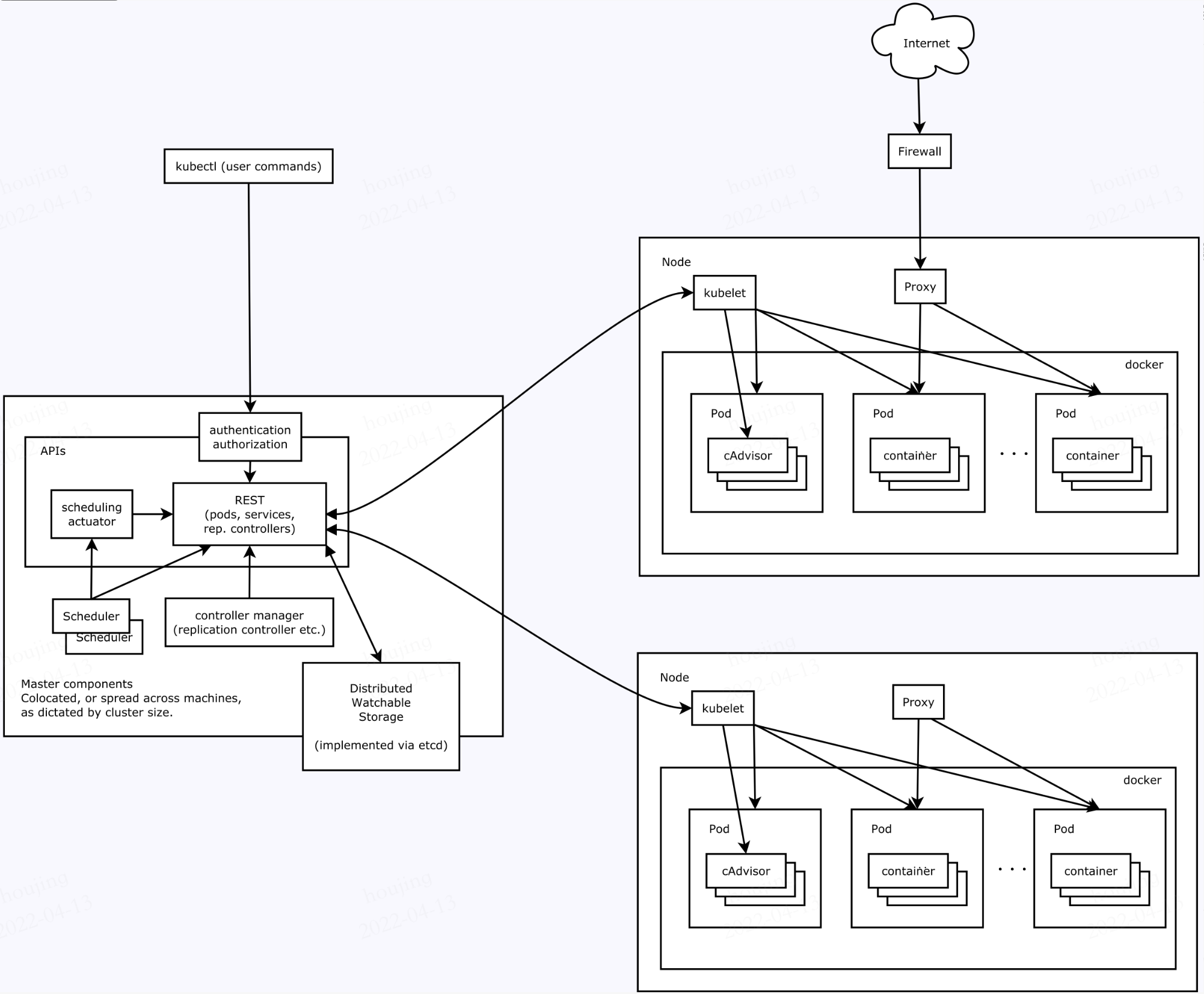
Kubernetes 遵循非常传统的客户端/服务端的架构模式,客户端可以通过 RESTful 接口或者直接使用 kubectl 与 Kubernetes 集群进行通信,Kubernetes主要由Master组件以及一系列节点(Node)组件构成,其中 Master 节点主要负责存储集群的状态并为 Kubernetes 对象分配和调度资源。
2.2.1、Master组件
-
kube-apiserver:所有服务访问的唯一入口,提供认证、授权、访问控制、API 注册和发现等机制,用于对外提供 RESTful 的接口暴露Kubernetes API,包括用于查看集群状态的读请求以及改变集群状态的写请求,也是唯一一个与 etcd 集群通信的组件。
-
etcd:etcd的官方将其定位成一个可信赖的分布式键值存储服务,能够为整个分布式集群存储一些关键数据,协助分布式集群正常运转,因此作为兼具一致性和高可用性的键值数据库,保存了 Kubernetes 所有集群数据,使用时需要为etcd数据提供备份计划。推荐在Kubernetes集群中使用etcs v3,v2版本已经弃用。
-
kube-scheduler: 该组件监视那些新创建的未指定运行节点的 Pod,并选择节点让 Pod 在上面运行。调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
-
kube-controller-manager: 在主节点上运行控制器的组件,从逻辑上讲,每个控制器都是一个单独的进程,但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。这些控制器包括:节点控制器(负责在节点出现故障时进行通知和响应)、副本控制器(负责为系统中的每个副本控制器对象维护正确数量的 Pod)、端点控制器(填充端点 Endpoints 对象,即加入 Service 与 Pod))、服务帐户和令牌控制器(为新的命名空间创建默认帐户和 API 访问令牌)。
-
cloud-controller-manager:云控制器管理器负责与底层云提供商的平台交互,云控制器管理器是Kubernetes版本1.6中引入的,目前还是Alpha的功能。云控制器管理器仅运行云提供商特定的(controller loops)控制器循环,可以通过将--cloud-provider flag设置为external启动kube-controller-manager ,来禁用控制器循环。cloud-controller-manager 具体功能:节点(Node)控制器、路由(Route)控制器、Service控制器、卷(Volume)控制器。(图中未体现,同kube-controller-manager一样与kube-apiserver交互)
除了以上基础组件外还有插件(addon),插件是实现集群pod和Services功能的 。Pod由Deployments,ReplicationController等进行管理。Namespace 插件对象是在kube-system Namespace中创建。
-
CoreDNS:可以为集群中的 SVC 创建一个域名 IP 的对应关系解析的 DNS 服务,虽然不严格要求使用插件,但Kubernetes集群都应该具有集群 DNS,集群DNS是一个DNS服务器,能够为 Kubernetes services提供 DNS记录。由Kubernetes启动的容器自动将这个DNS服务器包含在他们的DNS searches中。
-
kube-ui:给K8s集群提供了一个B/S架构的访问入口,提供集群状态基础信息查看。
-
Cluster-level logging:负责保存容器日志,搜索/查看日志。
-
Prometheus:给K8s集群提供资源监控的能力。
-
Ingress Controller:官方只能够实现四层的网络代理,而 Ingress 可以实现七层的代理
-
Federation:提供一个可以跨集群中心多 K8s 的统一管理功能,提供跨可用区的集群
2.2.2、节点(Node)组件
Worker节点实现就相对比较简单,它主要由 kubelet 和 kube-proxy 两部分组成。
-
kubelet: 是工作节点执行操作的agent,负责具体的容器生命周期管理,根据从数据库中获取的信息来管理容器,并监视已分配给节点的pod,包含:安装Pod所需的volume、下载Pod的Secrets、Pod中运行的docker(或experimentally,rkt)容器、定期执行容器健康检查、上报Pod状态,必要时新建一个pod副本、上报node节点状态。
-
kube-proxy: 是一个简单的网络访问代理,同时也是一个Load Balancer,通过在主机上维护网络规则并执行连接转发来实现Kubernetes服务抽象。它负责将访问到某个服务的请求具体分配给工作节点上同一类标签的 Pod。kube-proxy实质就是通过操作防火墙规则(iptables或者ipvs)来实现Pod的映射。
-
Container Runtime: 容器运行环境是负责运行容器的软件,Kubernetes 支持多个容器运行环境: Docker、 containerd、cri-o、 rktlet 以及任何实现 Kubernetes CRI(容器运行环境接口)。
-
docker:用于运行容器。
-
RKT:rkt运行容器,作为docker工具的替代方案。
-
supervisord:是一个轻量级的监控系统,用于保障kubelet和docker运行。
-
fluentd:是一个守护进程,可提供cluster-level logging。
2.3、Kubernetes组件通信协议
下图清晰表明了Kubernetes的架构设计以及组件之间的通信协议。
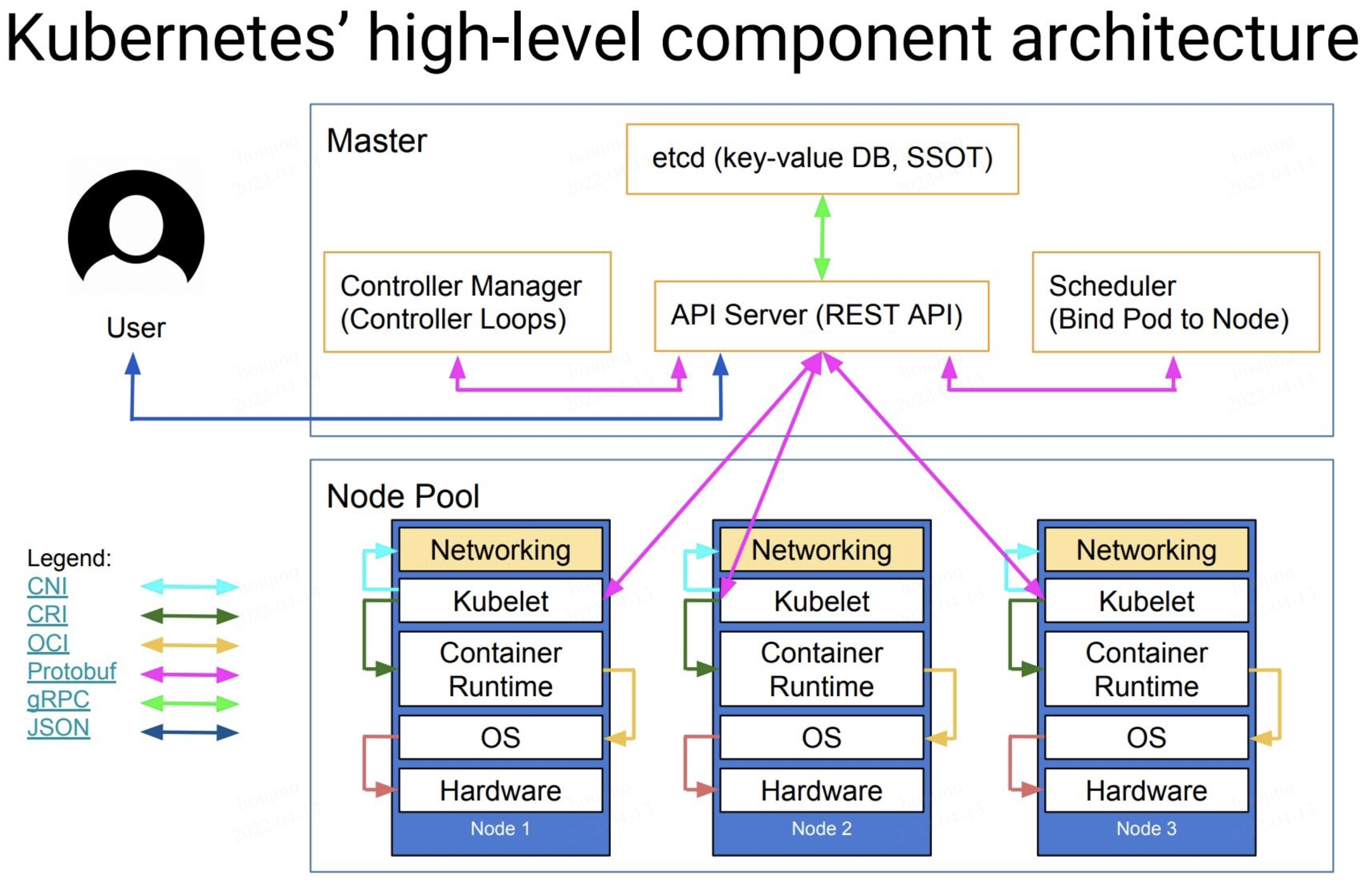
2.4、Kubernetes分层架构
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构,如下图所示:

-
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
-
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
-
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
-
接口层:kubectl命令行工具、客户端SDK以及集群联邦
-
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
- Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
2.5、Kubernetes API设计原则
对于云计算系统,系统API实际上处于系统设计的统领地位,正如本文前面所说,Kubernetes集群系统每支持一项新功能,引入一项新技术,一定会新引入对应的API对象,支持对该功能的管理操作,理解掌握的API,就好比抓住了Kubernetes系统的牛鼻子。Kubernetes系统API的设计有以下几条原则:
- 所有API应该是声明式的。正如前文所说,声明式的操作,相对于命令式操作,对于重复操作的效果是稳定的,这对于容易出现数据丢失或重复的分布式环境来说是很重要的。另外,声明式操作更容易被用户使用,可以使系统向用户隐藏实现的细节,隐藏实现的细节的同时,也就保留了系统未来持续优化的可能性。此外,声明式的API,同时隐含了所有的API对象都是名词性质的,例如Service、Volume这些API都是名词,这些名词描述了用户所期望得到的一个目标分布式对象。
- API对象是彼此互补而且可组合的。这里面实际是鼓励API对象尽量实现面向对象设计时的要求,即“高内聚,松耦合”,对业务相关的概念有一个合适的分解,提高分解出来的对象的可重用性。事实上,Kubernetes这种分布式系统管理平台,也是一种业务系统,只不过它的业务就是调度和管理容器服务。
- 高层API以操作意图为基础设计。如何能够设计好API,跟如何能用面向对象的方法设计好应用系统有相通的地方,高层设计一定是从业务出发,而不是过早的从技术实现出发。因此,针对Kubernetes的高层API设计,一定是以Kubernetes的业务为基础出发,也就是以系统调度管理容器的操作意图为基础设计。
- 低层API根据高层API的控制需要设计。设计实现低层API的目的,是为了被高层API使用,考虑减少冗余、提高重用性的目的,低层API的设计也要以需求为基础,要尽量抵抗受技术实现影响的诱惑。
- 尽量避免简单封装,不要有在外部API无法显式知道的内部隐藏的机制。简单的封装,实际没有提供新的功能,反而增加了对所封装API的依赖性。内部隐藏的机制也是非常不利于系统维护的设计方式,例如StatefulSet和ReplicaSet,本来就是两种Pod集合,那么Kubernetes就用不同API对象来定义它们,而不会说只用同一个ReplicaSet,内部通过特殊的算法再来区分这个ReplicaSet是有状态的还是无状态。
- API操作复杂度与对象数量成正比。这一条主要是从系统性能角度考虑,要保证整个系统随着系统规模的扩大,性能不会迅速变慢到无法使用,那么最低的限定就是API的操作复杂度不能超过O(N),N是对象的数量,否则系统就不具备水平伸缩性了。
- API对象状态不能依赖于网络连接状态。由于众所周知,在分布式环境下,网络连接断开是经常发生的事情,因此要保证API对象状态能应对网络的不稳定,API对象的状态就不能依赖于网络连接状态。
- 尽量避免让操作机制依赖于全局状态,因为在分布式系统中要保证全局状态的同步是非常困难的。
2.6、控制机制设计原则
- 控制逻辑应该只依赖于当前状态。这是为了保证分布式系统的稳定可靠,对于经常出现局部错误的分布式系统,如果控制逻辑只依赖当前状态,那么就非常容易将一个暂时出现故障的系统恢复到正常状态,因为你只要将该系统重置到某个稳定状态,就可以自信的知道系统的所有控制逻辑会开始按照正常方式运行。
- 假设任何错误的可能,并做容错处理。在一个分布式系统中出现局部和临时错误是大概率事件。错误可能来自于物理系统故障,外部系统故障也可能来自于系统自身的代码错误,依靠自己实现的代码不会出错来保证系统稳定其实也是难以实现的,因此要设计对任何可能错误的容错处理。
- 尽量避免复杂状态机,控制逻辑不要依赖无法监控的内部状态。因为分布式系统各个子系统都是不能严格通过程序内部保持同步的,所以如果两个子系统的控制逻辑如果互相有影响,那么子系统就一定要能互相访问到影响控制逻辑的状态,否则,就等同于系统里存在不确定的控制逻辑。
- 假设任何操作都可能被任何操作对象拒绝,甚至被错误解析。由于分布式系统的复杂性以及各子系统的相对独立性,不同子系统经常来自不同的开发团队,所以不能奢望任何操作被另一个子系统以正确的方式处理,要保证出现错误的时候,操作级别的错误不会影响到系统稳定性。
- 每个模块都可以在出错后自动恢复。由于分布式系统中无法保证系统各个模块是始终连接的,因此每个模块要有自我修复的能力,保证不会因为连接不到其他模块而自我崩溃。
- 每个模块都可以在必要时优雅地降级服务。所谓优雅地降级服务,是对系统鲁棒性的要求,即要求在设计实现模块时划分清楚基本功能和高级功能,保证基本功能不会依赖高级功能,这样同时就保证了不会因为高级功能出现故障而导致整个模块崩溃。根据这种理念实现的系统,也更容易快速地增加新的高级功能,因为不必担心引入高级功能影响原有的基本功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号