

大数据
大数据
大数据是信息化发展的必然产物,其英文是Big Data,概念起源于美国,早在1980年,著名未来学家阿尔文•托夫勒在其所著的《第三次浪潮》中就将“大数据”称为“第三次浪潮的华彩乐章”。911事件之前,数据分析已经深入应用到美国情报部门,911事件中的多名恐怖份子,在911事件前,已经被CIA进行了锁定,但是缺乏和FBI之间的数据关联分析,将恐怖份子的危害等级标识为“低”,导致了911事件的发生。911事件之后,美国“痛定思痛”,出于对国防情报、反恐信息的需求,大力发展大数据,著名的“棱镜门”事件就是基于大数据技术进行国家情报分析的典型应用场景。
随着数字时代的到来,数据逐步被各国作为国家基础性战略资源,已经成为与物质资产和人力资本同样重要的基础生产要素。国家拥有的数据规模及运用能力已逐步成为综合国力的重要组成部分,对数据的占有权和控制权将成为陆权、海权、空权之外的国家核心权力。在发展大数据的同时,也容易出现军事涉密数据、政府重要数据、法人和其他组织商业机密、个人敏感数据泄露,给国家安全、社会秩序、公共利益以及个人安全造成威胁。没有安全,发展就是空谈。数据安全是发展大数据的前提,必须将它摆在更加重要的位置。
大数据是无法在一定时间范围内用常规软件工具进行捕捉、管理、处理和分析的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。大数据不仅仅是海量的结构数据、非结构数据,但是如果没有分析,数据的价值就无法体现。大数据的价值不是在海量数据本身,虽然我们需要数据,但数据很多时候只是伴随科技进步而产生的副产品。而怎么样将这些数据进行存储、计算、分析处理,从而得到我们想要的信息,才是大数据真正的核心所在,正如马云所说,大数据的‘大’,不仅是数据量‘大’,同时也是指计算量的大。因此,大数据应该是存储与计算相结合的数据应用模式。
大数据有多个特征,结合目前主流意见,大数据总共有7个特点:Volume(数据量大)、Variety(数据多样性)、Velocity(处理速度快)、Value(价值)、Veracity(准确性)、Valence(关联性)和Validity(合规性)。这些特点基本上得到了业界普遍的认可,基本上采用了这7个特点。首先,数据量大是大数据的显著特征,大数据的规模大,需要的存储空间大,一般采用分布式存储架构支撑海量数据的存储。其次,数据多样性是指单一的数据源、单一的数据类型,即时数据量大,也不能称为“大数据”。大数据需要有不同源的数据,通过不同源数据的融合共享、汇聚清洗,横向关联后,才能形成大数据的数据基础。第三,处理速度快。大数据与云计算、物联网、人工智能等新一代信息技术之间相互影响、相互促进、相互融合,在对海量数据的分析和计算中,我们需要对数据进行快速的处理,来即时获取有用的信息,避免造成数据垃圾山的堆积。第四,大数据的价值。这要分为两个维度进行理解,第一个角度是价值大。理论上来说,如果我们有足够多的数据样本,那么我们通过大数据分析和挖掘,能够准确、量化的知道下一阶段将要面临的情况和结果。第二个维度是价值密度低,在大数据统计中,有意义的或者说有价值的数据可能只占总数据的1%甚至更低。第五,是大数据的准确性。指的是当数据的来源变得更多元时,这些数据本身的可靠度、质量需要保证,若数据本身就是有问题的,那分析后的结果也不会是正确的,另外,对于某一个问题,其分析的数据量越多,算法越先进,得出的结果就会越准确,这就是大数据分析魅力十足的原因。第六,大数据的关联性。大数据的目的是为了通过分析挖掘,得到可用的信息,来进行未来趋势的预测。是在海量数据中对有针对性有价值的相关的数据进行分析,得出有价值内容,因此根据不同的数据之间的关联,组成不同的大数据集进行分析,会得到不同的结果。第七,是大数据的合规性。大数据的存储、计算和应用,需要满足相关法律和规定。同时,大数据带来的新的数据使用模式,为相关法律法规提出了新的挑战。
大数据在数据规模、处理方式、应用模式等方面都呈现了与传统数据不同的新特征。传统计算架构处理海量数据无法满足计算效率的要求,需采用基于大数据的新型计算架构。大数据计算架构不仅面临传统信息系统面临的安全风险和威胁,同时在大数据基础平台、数据流转、数据隐私保护等方面引入了新的安全风险和威胁。这些安全风险,阻碍了大数据的应用和推广,而密码技术作为信息安全的核心支撑技术,在大数据安全中势必发挥更重要的作用。
1 大数据技术框架
参考GB-T 35589-2017《信息技术 大数据 技术参考模型》,大数据参考架构如下图所示,大数据参考框架为大数据系统的基本概念和原理提供了一个总体架构。
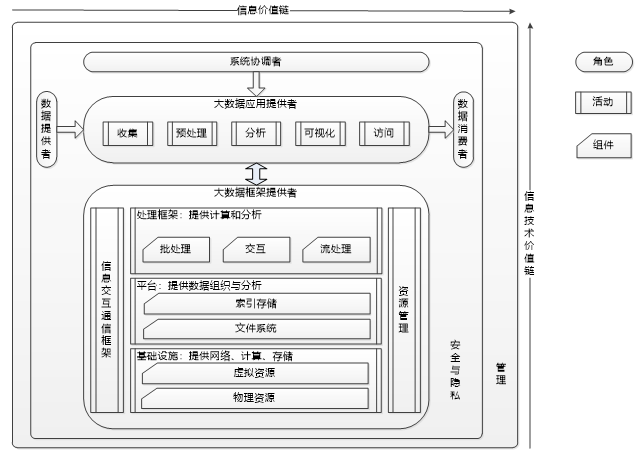
图 1大数据技术框架
框架围绕大数据价值链的两个维度组织展开,信息价值链(水平轴)和信息技术价值链(垂直轴)。信息价值链表现大数据作为一种数据科学方法对从数据到知识的处理过程中所实现的信息流价值。信息价值链的核心价值通过数据采集、预处理、分析、可视化和访问等活动实现。信息技术价值链表现大数据作为一种新兴的数据应用范式对信息技术产生的新需求所带来的价值。信息技术价值链的核心价值通过为大数据应用提供存放和运行大数据的网络、 基础设施、 平台、 应用工具以及其他信息技术服务实现。大数据应用提供者位于两个价值链的交叉点上, 大数据分析及其实现为两个价值链上的大数据利益相关者提供特定价值。
大数据参考框架提出了大数据系统中信息流向、系统活动、系统组件、角色关系,指出了完整的大数据系统应该包括大数据平台框架以及大数据应用。同时明确了安全和隐私、管理需要覆盖硬件、软件和上层应用。
大数据处理平台目前类型繁多,面向海量数据批量处理、实时流信息处理、物联网等不同场景有多种对应解决方案。目前,以Hadoop为代表的高扩展性、高性能的分布式/并行海量数据管理和处理框架为大数据分析挖掘提供了良好的支撑,是最为流行的大数据处理平台。
1.1大数据处理模式
大数据分析是在强大的支撑平台上运行分析算法发现隐藏在大数据中潜在价值的过程, 例如隐藏的模式和未知的相关性,根据处理时间的需求,大数据的分析处理可以分为流式处理和批处理两类。
1.1.1 批处理
在批处理方式中, 数据首先被存储(如分布式数据仓库),随后被分析。MapReduce 是非常重要的批处理模型,其核心思想是:数据首先被分为若干小数据块,随后这些数据块被并行处理并以分布的方式产生中间结果,最后这些中间结果被合并产生最终结果。MapReduce 分配与数据存储位置距离较近的计算资源,以避免数据传输的通信开销。批处理方式用于离线应用,通常计算过程大于10分钟,一般调度在空闲时间(如夜间)进行计算。代表性的开源组件包括基于MapReduce框架的Hive、Spark SQL等。
1.1.2 流处理
在某些场景下,数据的价值会随着时间的流逝而降低,数据的时效性变得非常重要,与批处理方式相比,流处理方式能够更快地处理数据并得到结果。在这种方式下,数据以流的方式到达,在数据连续到达的过程中,由于流携带了大量数据,只有小部分的流数据被保存在有限的内存中。流处理方式一般用于在线类应用, 通常工作在秒或毫秒级别。流式处理理论和技术已研究多年,代表性的开源组件包括 Storm、Spark streaming和 Flink。
通常情况下,流处理适用于数据以流的方式产生,且数据需要得到快速处理获得大致结果,因此流处理的应用相对较少, 大部分应用都采用批处理方式。两种处理模型在体系结构上存在差异,基于批处理的平台通常能够实现复杂的数据存储和管理,而基于流处理的平台面向小批量数据基于内存的快速实时处理的使用场景。
1.2 典型大数据技术平台:Hadoop
谷歌公司从2005年陆续发布的GFS、Bigtable、MapReduce论文奠定了大数据技术的基石。开源社区此后快速的给出了谷歌大数据论文理论的开源Hadoop代码实现。在拥有海量数据的巨头公司业务驱动以及知名高校学术研究等多重因素的驱动下,开源大数据技术产品不断分层细分,目前大数据相关开源项目已达上百个,在开源社区形成了丰富的技术栈,覆盖了存储、计算、分析、管理、运维等各个方面。丰富的开源组件包括文件系统(HDFS)、数据库(HBase、MongoDB)、批处理框架(MapReduce)、流计算框架(Spark、Flink)、查询分析(Hive)、数据挖掘(Mahout)、Sqoop(结构化数据导入)、Flume(日志数据导入)等在内的相对完整的生态系统。某种程度上说,Hadoop已经成为大数据处理工具事实上的标准。
Hadoop系统集成了大数据主要技术体制,包括数据存储、数据处理、系统管理和其他组件,提供了强大的系统级解决方案,成为大数据处理的核心技术,HBase、HDFS和MapReduce构成了 Hadoop的核心技术。HBase提供了高效实时分布式数据库、HDFS代表了 Hadoop大数据平台最基本的存储能力,实现对分布式存储的底层支持;MapReduce代表了 Hadoop大数据平台最基本的计算能力,实现对分布式并行任务处理的程序支持,共同支撑了 Hadoop主要体系架构。下图是Cloudera公司给出了一种Hadoop的开源实现方案。
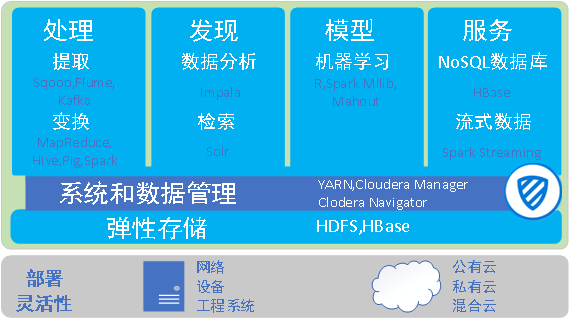
图2 系统组成
1.2.1 HDFS
Hadoop分布式文件系统(HDFS)是Hadoop生态系统中其余部分的基础。HDFS是Hadoop的存储层,在系统存储容量和带宽总容量线性增长时,能够对海量数据进行存储。HDFS是能够跨越多个服务器的逻辑文件系统。客户端与文件交互可能需要与集群中的每一个节点进行通信。HDFS将文件分解成块(block),每一个文件被存储在集群中任何节点的任何物理驱动器上。
1.2.2 Sqoop
Sqoop提供了传统关系型数据库(如Oracle等)以及其他数据源(如FTP服务器)中批量导入/导出数据的功能。Sqoop自身通过提交MapReduce任务,与关系型数据库进行交互。
1.2.3 Flume
Flume是一个基于事件的数据导入工具,主要用于将日志文件等数据导入Hadoop。Flume支持内存通道和文件通道传输数据。内存通道通过牺牲一定的可靠性实现高速传输,文件通道通过牺牲一定的传输速度提供较高的可靠性。
1.2.4 HBase
HBase是分布式key−value存储,由谷歌的BigTable论文“BigTable:A Distributed Storage System for Structured Data”启发而来。HBase在大数据系统中通常用来存储海量结构化数据,底层使用HDFS作为数据的底层存储层。HBase表被划分为不同区域,根据row key进行分隔。区域由RegionServer存放,客户端使用键值从RegionServer请求数据。
1.2.5 MongoDB
MongoDB是一个分布式文件存储的数据库,旨在为Web应用提供可扩展的高性能数据存储。MongoDB不需要定义模式,模式自由的特征适合存储各类非结构化类型的文档。基于JSON格式的BSON文件(二进制数据存储)存储格式,尤其适合视频文件的存储,同时支持对存储对象进行快速查询。
1.2.6 MapReduce
MapReduce是与HDFS相对应的数据处理部分,提供最基本的数据批处理机制。MapReduce作业由客户端提交给MapReduce框架,然后在HDFS中的一个数据子集上执行。MapReduce框架负责客户代码在集群之间的分发和执行,客户端不需要与集群的任何节点进行交互以执行任务,作业本身会申请一定数量的任务完成其工作。根据MapReduce框架的调度算法,每个任务会被分配到一个节点运行。
1.2.7 Spark
Spark是专为大规模数据处理而设计的快速通用的计算引擎,由加州大学伯克利分校开源的通用并行框架。Spark启用了内存分布数据集,支持交互式计算和复杂算法,Spark主要组件包括流计算Spark streaming、查询Spark SQL以及机器学习SparkR、MLlib等。
1.2.8 Sentry
Sentry组件为其他生态组件提供细粒度角色访问控制(role-based access control,RBAC),虽然各个组件可能会有自己的验证机制。Sentry在各个组件之间提供了一个支持强制集中策略的统一验证机制。
1.3 Hadoop安全发展
Hadoop项目最初的关注点是实际的技术实现,项目中许多代码涵盖的逻辑能够针对分布式系统中固有的复杂性进行处理,如故障处理和协同。由于这种较强的针对性,早期的Hadoop项目建立了一个安全立场,即整个机器集群和所有访问它的用户都是可信网络的一部分,Hadoop平台并没有强安全策略执行措施。
在Hadoop项目演变中,首先加入了Kerberos机制对用户身份进行强安全认证。在强认证策略之外,还需要有强授权策略。起初授权策略是在单个组件上实现的,需要大数据运维管理人员在各组件上分别对授权控制进行配置。Apache Sentry项目的出现简化了授权机制,目前在开源大数据平台中,尚未有一个能在Hadoop生态系统中具有整体统筹性的授权机制。
Hadoop安全的另一个演变是,通过加密和其他机密性机制进行的数据保护。Hadoop为节点间的数据传输添加了加密手段,对硬盘上的数据存储也进行了加密。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号