PTA第四次到第六次大作业分析
PTA第四次到第六次大作业分析
——OOP第二次总结
一、 前言
OOP的这三次大作业的题目概述如下:
第四次的OOP作业共三道题:1.水文数据校验及处理;2.日期问题面向对象设计;3.图形继承
第五次的OOP作业共五道题:1.找出最长的单词-hebust;2.合并两个有序数组为新的有序数组;3.对整型数据排序;4.统计Java程序中关键词的出现次数;5.日期问题面向对象设计(聚合二);
第六次的OOP作业共六道题:1.正则表达式训练-QQ号校验;2.字符串训练-字符排序;3.正则表达式训练-验证码校验;4.正则表达式训练-学号校验;5.图形继承与多态;6.实现图形接口及多态性;
1:从第四次到第六次作业的题量上来看,题目的数量是在慢慢上涨,从原本的三道题上涨到了五道题目,然后上涨到了六道题;
2:从难易程度上来看,题目的难度是在随着题量的上涨而下降但是做过之后会发现,题目的难度虽然是在下降,但是三次的难易程度相差还是很大的,比如说第四次的OOP作业当中的第一题就相当困难,当时我是最后一天写的,没想到会那么艰难,最后的结果就是没有写出来;
3:从涉及的知识点来看,这三次大作业涉及的知识点还是比较广的:
比如第六次的OOP作业当中涉及的知识点有正则表达式的运用、排序的算法(比如说冒泡排序,选择排序)、字符串的运用、OOP的一些特点:继承,多态,接口;
再比如第五次的OOP作业当中涉及的知识点有:字符串数组的运用、数组的运用、排序算法(当中有一道题规定了一定要使用三种排序:插入排序、选择排序、冒泡排序)、接口和正则表达式的运用、聚合;
第四次的OOP作业所涉及的知识点有:正则表达式对字符串的检验、聚合、继承;
二、 设计与分析
- 题目集4(7-2)、题目集5(7-5)两种日期类聚合设计的优劣比较如下:
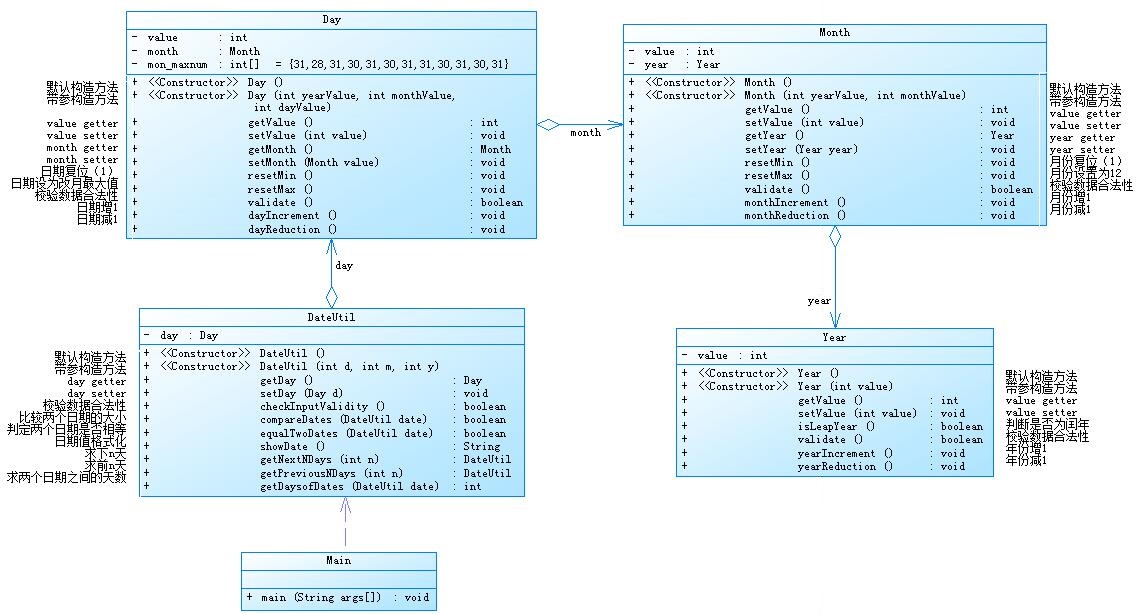
题目集4当中的7-2类图如下:
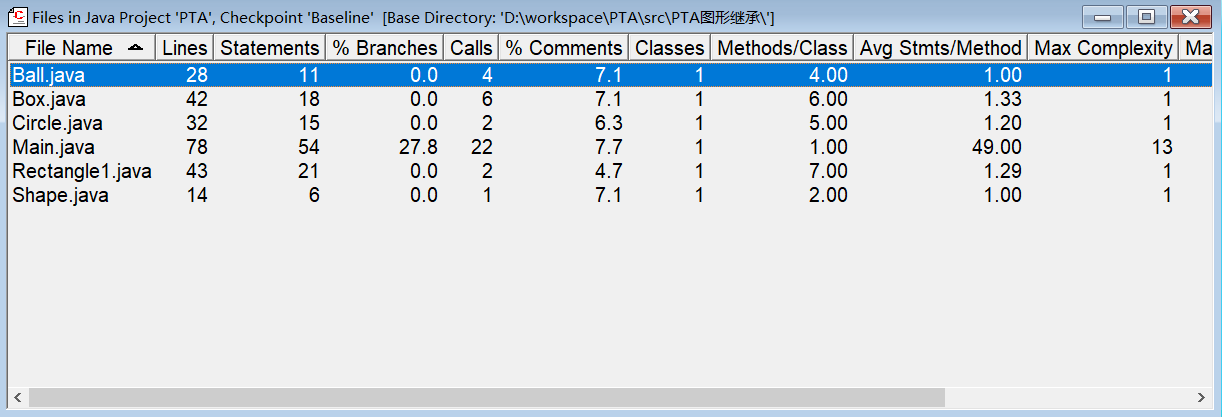
自己所编写的代码在SourceMonitor当中显示的报表结果如下:

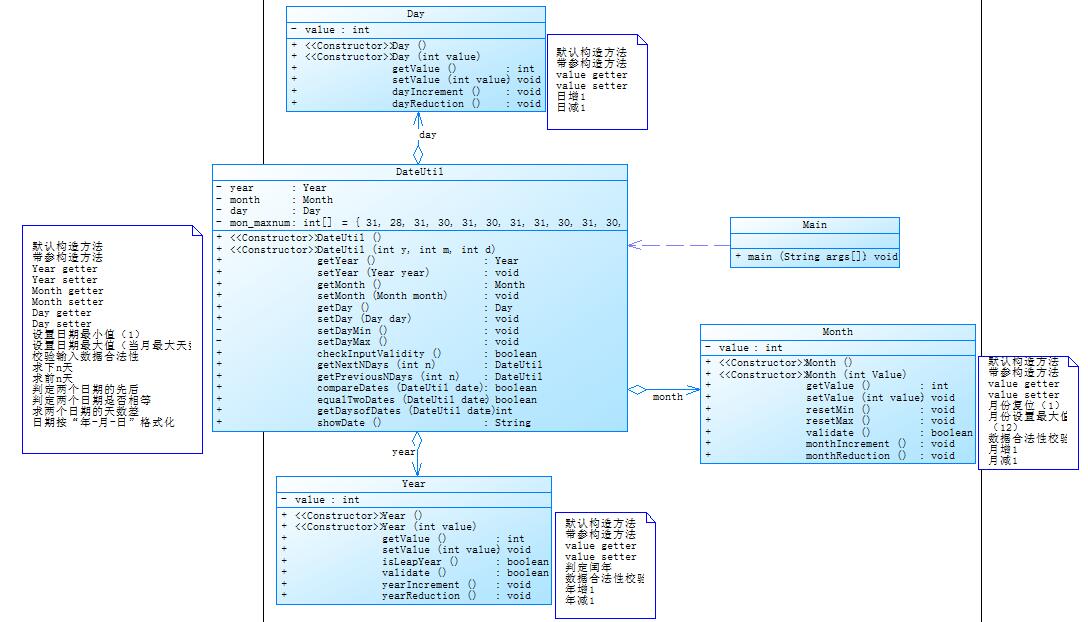
题目集4当中的7-5类图如下:
自己所编写的代码在SourceMonitor当中的所生成的报表结果如下:
根据SourceMonitor的生成报表可以看到两个程序的圈复杂程度相差不是特别的大,于此同时,这两道题目在忽略一些细节的时候,可以说是两道一摸一样的题目,可以使用同一种算法,只需要改变一下下的输出样例即可,在完成题目集5的7-5的时候,我便是在动用了题目集4的7-2的算法,改动一点点的数据之后便成功解题了。另一点就是这两道题的聚合方面的设计是多多少少有些不一样的,比如说在题目集4的7-2当中是一个接连着一个的,如year聚合到month,month聚合到day,day聚合到Dateutil的这种,感觉像是一条“链子”整体不可分割的模样,这种可以说是传递的聚合;而题目集5的7-5是另外一种的聚合,他是借着Dateutil类把year、month、day一起聚合到Dateutil当中,形成一个整体,感觉像是year、month和day三者是独立的关系,但三者可能有共同的方法;
比较之后,我个人觉得两者都各自有各自的特点和优缺点,依照自己的个人之见,我更加喜欢第二种;
第一种的聚合耦合度相对于第二种而言是比较高的,第一种的一个接着一个,一旦某个环节出现了问题,想要改动或者说维修它的话,将会变的更加麻烦,另一个点就是每次要使用Day的时候都要声明一下Month 和Year的属性,这样的话,就显得有些麻烦了;
第二种的话就避免了第一种的这种情况,因为其余三个类当中都是单独的,可以说是没有什么太大的联系,一旦某个环节出现了问题,那么可以单独的对它进行一个修改,方便维护。
2. 题目集4(7-3)
类Shape,无属性,有一个返回0.0的求图形面积的公有方法
类Circle,继承自Shape,有一个私有实型的属性radius(半径),重写父类继承来的求面积方法,求圆的面积
类Rectangle,继承自Shape,有两个私有实型属性width和length,重写父类继承来的求面积方法,求矩形的面积
类Ball,继承自Circle,其属性从父类继承,重写父类求面积方法,求球表面积,此外,定义一求球体积的方法
类Box,继承自Rectangle,除从父类继承的属性外,再定义一个属性height,重写父类继承来的求面积方法,求立方体表面积,此外,定义一求立方体体积的方法
-
- 每个类均有构造方法,且构造方法内必须输出如下内容:
Constructing 类名 - 每个类属性均为私有,且必须有getter和setter方法(可用Eclipse自动生成)
- 输出的数值均保留两位小数
- 每个类均有构造方法,且构造方法内必须输出如下内容:
题目集4(7-3)的类图如下:
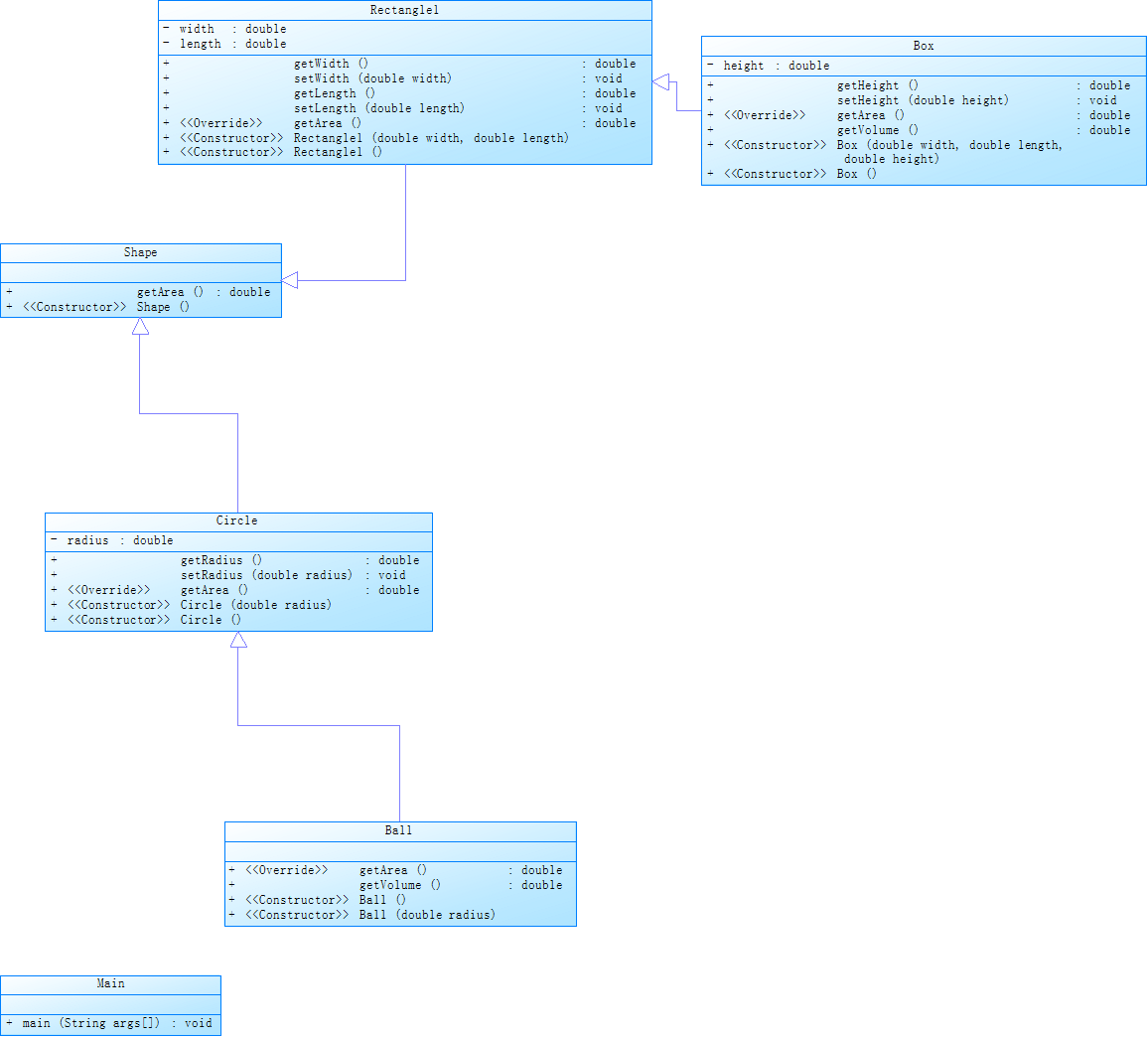
自己所编写的代码在SourceMonitor当中的所生成的报表结果如下:

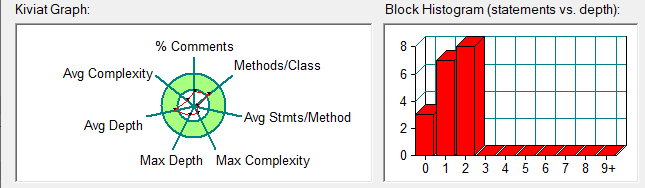



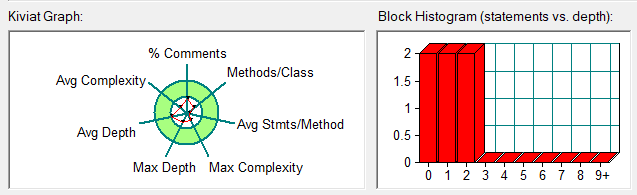
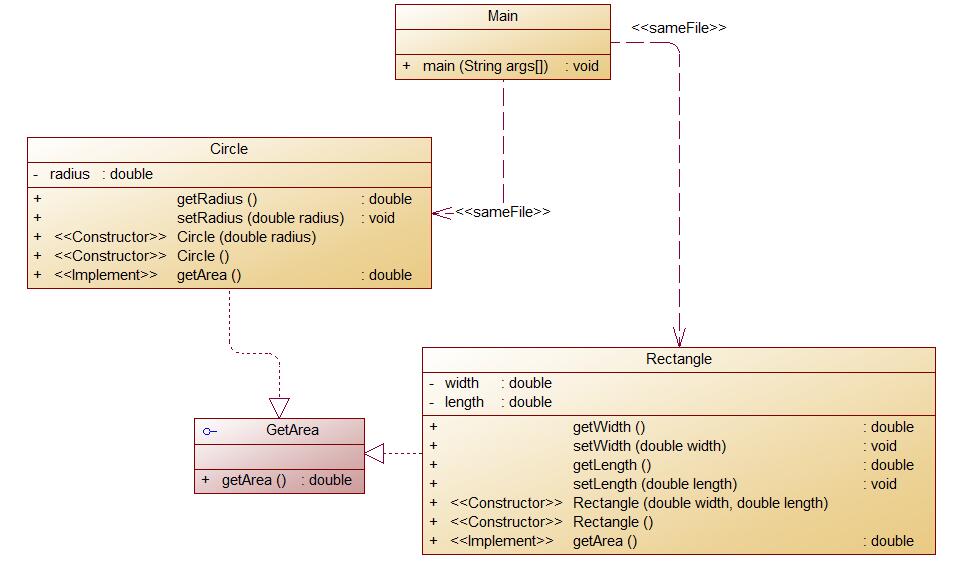
题目集6(7-5):它的类图如下:
自己所编写的代码在SourceMonitor当中的所生成的报表结果如下:

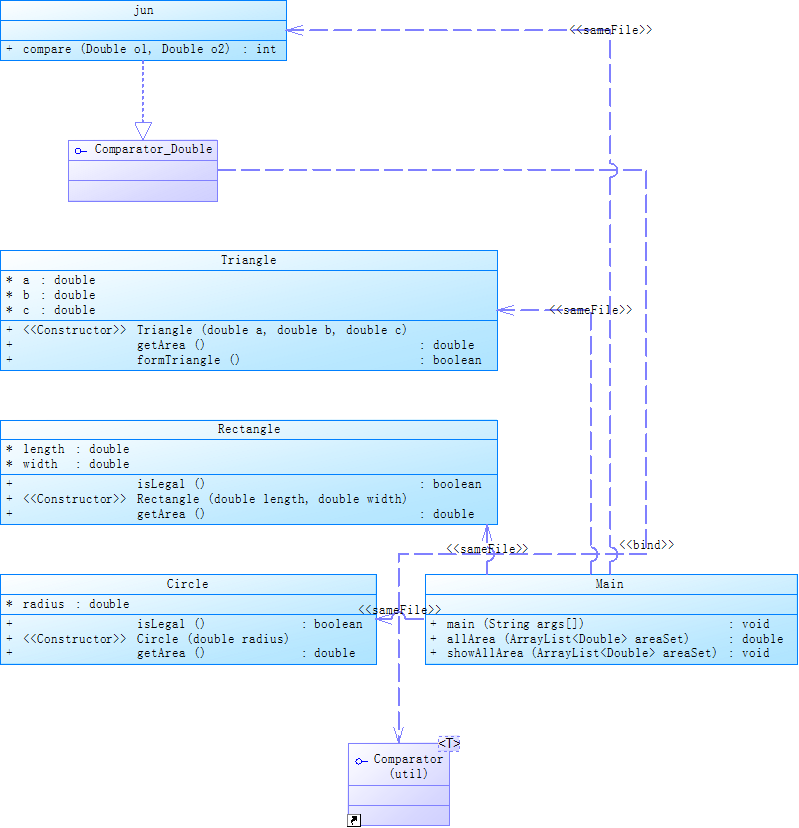
题目集6(7-6):它的类图如下:
自己所编写的代码在SourceMonitor当中的所生成的报表结果如下:

这三道题都是继承类题目,题目集4的7-3是要求我们求面积,几何体的表面积和体积,这道题的目的应该是让我们做了之后,更加熟练的运用Java中的继承这一大特点,首先第一题有一个总的Shape类,它是父类,它里面可以包括很多的类别,比如圆、矩形等等,它的子类包含了一个Circle类和Rectangle类,Shape类有一个getArea的方法,然后在Circle和Rectangle类中重写了求面积的方法,在这个基础上,又写了两个类Ball和Box分别继承了Circle类和Rectangle类,Ball类和Box类中又重写了求面积的方法,又增加了求体积的方法,每个类中都会输出自己的类名,就是一旦跟这个类有关就会输出这个类的类名;子类可以调用父类的方法,所以从而可以简单的实现共有的一些功能,或者说几个类当中有共同的方法或者属性,达到一定的数量之后,我们可以考虑使用父类和子类的关系,即继承的这个特点去加以实现;这样的话可以减少代码量,如果子类的计算方法和父类不一样,还可以重写其方法来达到目的,继承是Java中很重要的一个内容,我们想实现一些东西,在不改变自身代码的情况下,我们可以给之前的代码加一个父类。
第二题也是要求我们求图形的面积,根据图形面积对图形对象进行排序并输出,第二题,这道题采用了抽象类定义,实体类构建的一个方式,我们首先有一个Shape类,但这个类与上一题不同的是,这是一个抽象类,拥有抽象的方法,求面积和数据校验,然后它有三个子类分别是,circle类rectangle类和triangle类分别,三个类继承于shape类,重写了求面积和数据校验的方法,我在主函数中分别创建三个类的对象然后将他们放入shape类型的list中,求面积的时候直接调用shape的getArea的方法就可以了,然后再根据面积对list中的对象排序,最后再输出面积。我认为这道题主要是想让我们更深刻的理解继承以及去理解多态,我们求面积只需要调用shape的求面积方法,就可以直接求面积,不需要调用谁谁的求面积去求谁谁的面积,这样的话,可以减少一个建立对象的次数,如果建立对象太多的话,那么使用多态可以避免这种现象的发生,与此同时,我们也可以减少内存的使用,这就是多态的好处,继承和多态提高了代码的可维护性和可延展性。
第三题还是让我们来求面积,与前两个不同之处便是使用接口来实现了,首先我们创建了一个求面积的接口,接口中有一个求面积的的方法,然后创建了俩个类circle类和rectangle类,这两个类都与接口相连接,这两个类中都有求面积的方法,然后我们在主函数中创建两个对象,声明类型为接口,实际类型还是circle和rectangle,然后调用接口求面积的方法就可以求出面积。这道题主要的目的应该是想让我们了解接口并实践运用它,然后用接口以及类实现多态。
这些题目使用了多态、继承,于此同时也对数据进行了封装。封装可以方便对数据进行修改,有利于保护数据的完整性。提高了代码的可维护性。然后这些题目让我也更加了解了 Java当中继承、多态的实践运用,甚至还了解了 接口的运用。
3. 三次题目集中用到的正则表达式技术的分析总结
在这三次PTA当中出现了正则表达式的地方还是比较多的,比如说:题目集4的7-1,题目集5的7-4以及题目集6的7-1、7-2、7-3和7-4都运用到了正则表达式的地方
正则表达式常用的知识点总结:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
n 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
\W 匹配任意不是字母,数字,下划线,汉字的字符
\S 匹配任意不是空白符的字符
\D 匹配任意非数字的字符
\B 匹配不是单词开头或结束的位置
[^x] 匹配除了x以外的任意字符
[^asdf] 匹配除了asdf这几个字母以外的任意字符
-
Pattern 类:
pattern 对象是一个正则表达式的编译表示。Pattern 类没有公共构造方法。要创建一个 Pattern 对象,你必须首先调用其公共静态编译方法,它返回一个 Pattern 对象。该方法接受一个正则表达式作为它的第一个参数。
-
Matcher 类:
Matcher 对象是对输入字符串进行解释和匹配操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
public boolean lookingAt()
尝试将从区域开头开始的输入序列与该模式匹配。
public boolean find()
尝试查找与该模式匹配的输入序列的下一个子序列。
public boolean find(int start)
重置此匹配器,然后尝试查找匹配该模式、从指定索引开始的输入序列的下一个子序列。
public boolean matches()
尝试将整个区域与模式匹配。
public String replaceAll(String replacement)
替换模式与给定替换字符串相匹配的输入序列的每个子序列。
public String replaceFirst(String replacement)
替换模式与给定替换字符串匹配的输入序列的第一个子序列。
以上是一些正则表达式的部分知识点
题目集4的7-1是要求我们使用Java中的字符串处理类以及正则表达式对输入字符串数据进行合法性校验及计算。最主要的目的就是让我们实践的运用正则表达式,并对字符串进行一个合法性检验的操作,可以说这道题难度是相当大的。
题目集5的7-4统计Java程序中关键词的出现次数也是利用正则表达式去合理性的检验字符串的正确与否,是否达到题目要求的那个目的,这道题目的难易程度可以说是不弱于题目集4的7-1的,虽然7-1的题目分值很大,注意点也很多,7-4的题目就只有25分,但是难点也不低。
另外的四道题是非常基础的正则表达式,相当于是把先前的那两道题的每道分值点拆分开来之后,所单独弄的题目。
总的来说,正则表达式可以使我们的代码简单,我们用起来非常的方便,如果没有正则表达式,我们可能要用更加复杂的算法去写,去判断一个一个的点是否满足字符串的要求,所以正则表达式是帮助我们去操作字符串的一个好的工具。
4. 题目集5(7-4)中Java集合框架应用的分析总结
该题的题目如下:
编写程序统计一个输入的Java源码中关键字(区分大小写)出现的次数。说明如下:
- Java中共有53个关键字(自行百度)
- 从键盘输入一段源码,统计这段源码中出现的关键字的数量
- 注释中出现的关键字不用统计
- 字符串中出现的关键字不用统计
- 统计出的关键字及数量按照关键字升序进行排序输出
- 未输入源码则认为输入非法
输入格式:
输入Java源码字符串,可以一行或多行,以exit行作为结束标志
输出格式:
- 当未输入源码时,程序输出
Wrong Format - 当没有统计数据时,输出为空
- 当有统计数据时,关键字按照升序排列,每行输出一个关键字及数量,格式为
数量\t关键字
输入样例:
在这里给出一组输入。例如:
//Test public method
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
exit输出样例:
在这里给出相应的输出。例如:
1 float 3 if 2 int 2 new 2 public 3 this 2 throw
该题需要对一段代码统计出的关键字及数量按照关键字升序进行排序输出。在这道题需要我们使用正则表达式进行对注释内容的判断,最后将它们替换成空字符,最后只剩代码
内容进行统计即可。
将它换成空字符的部分代码参照如下:
1 //按行来输入源码的字符串 2 sourceCode1 = input.nextLine(); 3 //如果输入的是exit,那么跳出这个输入循环 4 if(sourceCode1.equals("exit")) 5 break; 6 //去除单行注释的情况 7 //如果输入的这行源码字符串匹配到了“//”,那么筛选//前面的内容并将其存储到sourceCodeResult里面 8 if(sourceCode1.matches(".*//.*")) 9 { 10 String tempTwo[]=sourceCode1.split("//"); 11 sourceCodeRecult.append(tempTwo[0]+" "); 12 } 13 //如果没有“//”,那么直接将这行的源码字符串存储到sourceCodeResult里面即可 14 else 15 { 16 sourceCodeRecult.append(sourceCode1+" "); 17 }
1 //创建Pattern类下的一个实例 2 Pattern p=Pattern.compile("/\\*[^*]*\\*/");//这个是多行注释 3 // Pattern p=Pattern.compile("/\\*");//调试的数据 4 //创建Matcher类下的一个m 5 Matcher m=p.matcher(sourceCode2); 6 //调用Matcher类下的一个find方法 7 //通过这个方法查找sourceCode2当中有没有这个多行注释 8 while(m.find()) 9 { 10 //将多行注释里面的那部分全部替换成空格字符串的形式 11 sourceCode2=sourceCode2.replace(m.group()," "); 12 m=p.matcher(sourceCode2); 13 }
1 Pattern q=Pattern.compile("/\\*\\*[^/]*/");//这个是文档注释 2 m=q.matcher(sourceCode2); 3 //同样的道理,是查找有没有这个文档的注释 4 while(m.find()) 5 { 6 sourceCode2=sourceCode2.replace(m.group()," "); 7 m=q.matcher(sourceCode2); 8 }
1 //以下是去除源码当中的字符串内容 2 q = Pattern.compile("\"[\\s\\S]*\""); 3 m=q.matcher(sourceCode2); 4 while(m.find()) 5 { 6 sourceCode2=sourceCode2.replace(m.group()," "); 7 m=q.matcher(sourceCode2); 8 }
全部代码如下:
1 import java.util.Arrays; 2 import java.util.HashMap; 3 import java.util.Map; 4 import java.util.Scanner; 5 import java.util.Set; 6 import java.util.regex.Matcher; 7 import java.util.regex.Pattern; 8 9 public class Main { 10 11 public static void main(String[] args) { 12 // TODO Auto-generated method stub 13 Scanner input=new Scanner(System.in); 14 // 15 String sourceCode1; 16 StringBuilder sourceCodeRecult= new StringBuilder(); 17 // Map<String, Integer> map=new HashMap<String, Integer>(); 18 //将53个关键字存储到一维数组当中 19 //每7个关键字为一行 20 String []keyWord= { "abstract","assert","boolean","break","byte","case","catch", 21 "char","class","const","continue","default","do","double", 22 "else","enum","extends","false","final","finally","float", 23 "for","goto","if","implements","import","instanceof","int", 24 "interface","long","native","new","null","package","private", 25 "protected","public","return","short","static","strictfp","super", 26 "switch","synchronized","this","throw","throws","transient","true", 27 "try","void","volatile","while" 28 }; 29 //定义一个一维的int类型的数组,和keyWord的关键字一一对应,并对应它的数量 30 //默认它们初始化值为零 31 int[] keyWordNumber = new int[53]; 32 while(true) 33 { 34 //按行来输入源码的字符串 35 sourceCode1 = input.nextLine(); 36 //如果输入的是exit,那么跳出这个输入循环 37 if(sourceCode1.equals("exit")) 38 break; 39 //去除单行注释的情况 40 //如果输入的这行源码字符串匹配到了“//”,那么筛选//前面的内容并将其存储到sourceCodeResult里面 41 if(sourceCode1.matches(".*//.*")) 42 { 43 String tempTwo[]=sourceCode1.split("//"); 44 sourceCodeRecult.append(tempTwo[0]+" "); 45 } 46 //如果没有“//”,那么直接将这行的源码字符串存储到sourceCodeResult里面即可 47 else 48 { 49 sourceCodeRecult.append(sourceCode1+" "); 50 } 51 } 52 //将sourceCode2转换成String类型 53 String sourceCode2 = sourceCodeRecult.toString(); 54 //创建Pattern类下的一个实例 55 Pattern p=Pattern.compile("/\\*[^*]*\\*/");//这个是多行注释 56 // Pattern p=Pattern.compile("/\\*");//调试的数据 57 //创建Matcher类下的一个m 58 Matcher m=p.matcher(sourceCode2); 59 //调用Matcher类下的一个find方法 60 //通过这个方法查找sourceCode2当中有没有这个多行注释 61 while(m.find()) 62 { 63 //将多行注释里面的那部分全部替换成空格字符串的形式 64 sourceCode2=sourceCode2.replace(m.group()," "); 65 m=p.matcher(sourceCode2); 66 } 67 Pattern q=Pattern.compile("/\\*\\*[^/]*/");//这个是文档注释 68 m=q.matcher(sourceCode2); 69 //同样的道理,是查找有没有这个文档的注释 70 while(m.find()) 71 { 72 sourceCode2=sourceCode2.replace(m.group()," "); 73 m=q.matcher(sourceCode2); 74 } 75 //以下是去除源码当中的字符串内容 76 // q = Pattern.compile("\"[\\s\\S]*\""); 77 // m=q.matcher(sourceCode2); 78 // while(m.find()) 79 // { 80 // sourceCode2=sourceCode2.replace(m.group()," "); 81 // m=q.matcher(sourceCode2); 82 // } 83 //如果去除掉以上的这些情况之后,源码为空的话,是以下这样的情况并直接输出 84 if(sourceCode2.isEmpty()) 85 { 86 System.out.println("Wrong Format"); 87 System.exit(0); 88 } 89 90 //将除去大小写字母的所有字符串替换成空字符串 91 sourceCode2=sourceCode2.replaceAll("[^a-zA-Z]", " "); 92 int count=0; 93 Map<String, Integer> map=new HashMap<String, Integer>(); 94 String []string1=sourceCode2.split("[ ' ']"); 95 for(int i=0;i<string1.length;i++) 96 { 97 for(int j=0;j<keyWord.length;j++) 98 if(string1[i].equals(keyWord[j])) 99 { 100 map.put(keyWord[j], 0); 101 } 102 } 103 for( int i = 0;i<string1.length;i++) 104 { 105 for(int j=0;j<keyWord.length;j++) 106 if(string1[i].equals(keyWord[j])) 107 { 108 count=map.get(keyWord[j]); 109 map.put(keyWord[j], count+1); 110 } 111 } 112 Set set=map.keySet(); 113 Object[] arr=set.toArray(); 114 Arrays.sort(arr); 115 for(Object k:arr) 116 { 117 System.out.println(map.get(k)+"\t"+k); 118 } 119 //以下的三行都是调试的数据 120 // System.out.println(sourceCodeRecult); 121 // System.out.println(m.pattern()); 122 // System.out.println(sourceCode2); 123 124 } 125 126 }
最后去除掉三种注释的字符串之后 ,采用正则表达式对里面的关键字进行一个统计,统计出数目来之后,按照顺序输出这些关键字以及它出现的数目即可
三、 踩坑心得
1:在题目集6的7-2正则表达式检验当中,明白了两个知识点:一个是string.toCharArray(),另一个是String.valueOf(string),一个是把字符数组转换成字符串的形式,而另一个是将字符串的形式转换成字符的形式,在之前用的比较少,然后在这题当中运用到了,便是提一下。
2:在题目集5的7-4当中,我解决不了如何去除源码当中字符串的内容,因为关键字也是有可能出现在字符串里面的,最终 也是无法完全通过正常的测试。
3:在写有关年月日的那三大题目当中,我之前是并没有把月份的最大天数记录到 数组当中,运用到算法里面的是一个一个的判断,这样的方法是非常的麻烦和累赘的,最后采用采用了优化,把月份的最大天数放进了数组里面,这样运用起来方便多了。
4:在写题目集5的7-5的时候,算法是已经写完了,最后却发现自己提交的答案是错误的,慢慢的也发现了是自己输出结果的样例与标准的不同。
5:每次在Eclipse当中写完的代码,移植到 PTA上面的时候,如果上面加了package的字样,在PTA上面运行出来的结果是空的。
四、 改进建议和方案
1:自己对字符串的运用感觉还是运用的太少了 ,对Java当中已经存在过的算法或者功能,库之类的了解也太少了,所以以后多多查点资料,可以解决这方面的问题。
2:想是有规律的数据或者数据一块一块的,组成起来很多地方的话,我之后会优先考虑一下数组的形式去加以完成。
五、 总结
(1)首先,学到了一些正则表达式的知识点以及它的应用 还需要多加练习。
(2)其次,学习到了类与类之间的关系,聚合,继承,多态等等。我认为这次最重要的就是明白了很多类与类之间的关系,比如关联,聚合,继承。
(3)我觉得这次的题目集,我对于继承有了更深的理解,因为理解了继承的好处,明白了它有什么用处,所以更好了理解了为什么要用继承,继承怎样使用。
(4)对于类的设计,整个代码的设计,要学习如何去进行良好的设计以及类与类之间的关系还需要进一步学习,需要通过练习来进一步掌握知识。
(5)我希望老师能够在PTA上面开放相对比较难的题目的补题,因为我们有的人在规定时间之内没做出来,然后之后想出了更好的算法,想去实践一下,却又不知道从哪下手实践了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号