Java设计模式学习记录-组合模式
前言
今天要介绍的设计模式是组合模式,组合模式也是结构型设计模式的一种,它主要体现了整体与部分的关系,其典型的应用就是树形结构。组合是一组对象,其中的对象可能包含一个其他对象,也可能包含一组其他对象。
组合模式
组合模式定义为:将对象组合成树形结构以表示“整体-部分”的层次结构。组合模式是单个对象和组合对象的使用具有一致性。
在使用组合模式的使用要注意以下两点:
组合中既要能包含个体,也要能包含其他组合。
要抽象出对象和组合的公共特性。
举例说明
介绍了一些基本内容,可能会还是不清楚组合模式到底是什么样的一个模式,还是老样子,举🌰说明。
在我们的家用PC电脑上的文件结构就是一个很好的例子,例如在我的电脑上有如下图所示的文件目录结构。
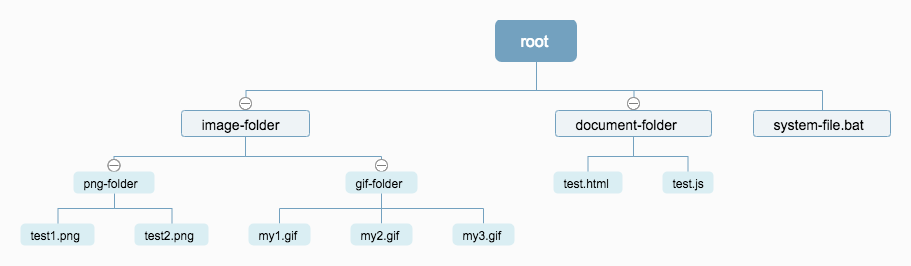
从root文件夹到具体的文件,一层一层的这种结构就是典型的树形结构,root是硬盘中的某个文件夹,可以理解为根节点,这个文件下下面有两个文件夹和一个文件,image-folder文件夹这种有分支的可以理解为分支节点,文件则理解为叶子节点。
为了要实现这种结构,这三种节点,我们一般的思路是,创建三个根节点、分支节点、叶子节点这三个类,但是我们发现根节点的特性其实和分支节点一样,可以理解为一类,所以我们只需要创建两个类就可以。
定义分支节点(包含根节点)的接口
/** * 定义分支节点(根节点) */ public interface IBranch { /** * 获得分支节点信息 * @return */ public String getInfo(); /** * 增加分支节点(文件夹下还可能会有文件夹) * @param branch */ public void addBranch(IBranch branch); /** * 增加叶子节点 * @param leaf */ public void addLeaf(ILeaf leaf); /** * 获得子集 * @return */ public ArrayList getChildren(); }
具体的实现如下
/** * 分支节点(文件夹) */ public class Folder implements IBranch{ /** * 节点名称 */ private String name; /** * 子集 */ private ArrayList children = Lists.newArrayList(); /** * 带参数的构造方法 * @param name */ public Folder(String name){ this.name = name; } /** * 获得分支节点信息 * * @return */ @Override public String getInfo() { return "名称:" + name; } /** * 增加分支节点(文件夹下还可能会有文件夹) * * @param branch */ @Override public void addBranch(IBranch branch) { children.add(branch); } /** * 增加叶子节点 * * @param leaf */ @Override public void addLeaf(ILeaf leaf) { children.add(leaf); } /** * 获得子集 * * @return */ @Override public ArrayList getChildren() { return children; } }
定义叶子节点的接口
/** * 定义叶子节点 */ public interface ILeaf { /** * 获得叶子节点的信息 * @return */ public String getInfo(); }
因为叶子节点,不会有子集所以只需要一个获得描述信息的方法即可,具体的实现如下。
/** * 叶子节点(文件) */ public class File implements ILeaf { private String name; /** * * @param name */ public File(String name){ this.name = name; } /** * 获得叶子节点的信息 * * @return */ @Override public String getInfo() { return "名称:"+name; } }
节点类已经定义完成了,所以现在可以开始组装数据了,然后将最终的数据打印出来看看是不是这个结构。
public class ClientTest { public static void main(String[] args) { //定义根节点 IBranch root = new Folder("root"); //定义二级节点的文件夹 IBranch imageFolder = new Folder("image-folder"); IBranch documentFolder = new Folder("document-folder"); //定义二级节点的文件 ILeaf systemFile = new File("system-file.bat"); //定义三级节点的文件夹 IBranch pngFolder = new Folder("png-folder"); IBranch gifFolder = new Folder("gif-folder"); //定义三级节点的文件 ILeaf testHtml = new File("test.html"); ILeaf testJS = new File("test.js"); //定义四级节点的文件,两个png文件 ILeaf test1png = new File("test1.png"); ILeaf test2png = new File("test2.png"); //定义四级节点的文件3个gif文件 ILeaf my1gif = new File("my1.gif"); ILeaf my2gif = new File("my2.gif"); ILeaf my3gif = new File("my3.gif"); //填充一级文件夹 root.addBranch(imageFolder); root.addBranch(documentFolder); root.addLeaf(systemFile); //填充二级图片文件夹 imageFolder.addBranch(pngFolder); imageFolder.addBranch(gifFolder); //填充二级文档文件夹 documentFolder.addLeaf(testHtml); documentFolder.addLeaf(testJS); //填充三级png图片文件夹 pngFolder.addLeaf(test1png); pngFolder.addLeaf(test2png); //填充三级gif图片文件夹 gifFolder.addLeaf(my1gif); gifFolder.addLeaf(my2gif); gifFolder.addLeaf(my3gif); System.out.println(root.getInfo()); //打印出来 getChildrenInfo(root.getChildren()); } /** * 递归遍历文件 * @param arrayList */ private static void getChildrenInfo(ArrayList arrayList){ int length = arrayList.size(); for(int m = 0;m<length;m++){ Object item = arrayList.get(m); //如果是叶子节点就直接打印出来名称 if(item instanceof ILeaf){ System.out.println(((ILeaf) item).getInfo()); }else { //如果是分支节点就先打印分支节点的名称,再递归遍历子节点 System.out.println(((IBranch)item).getInfo()); getChildrenInfo(((IBranch)item).getChildren()); } } } }
最终的打印结果:
名称:root 名称:image-folder 名称:png-folder 名称:test1.png 名称:test2.png 名称:gif-folder 名称:my1.gif 名称:my2.gif 名称:my3.gif 名称:document-folder 名称:test.html 名称:test.js 名称:system-file.bat
这个结果确实是我们想要的,但是仔细看看其实还是有可以优化的地方,Folder和File都有包含名字的构造方法,以及getInfo()方法,那么是不是可以抽取出来?那就改变一下吧。
新增节点公共抽象类
/** * 节点公共抽象类 */ public abstract class Node { private String name; /** * 带参数的构造方法 * @param name */ public Node(String name){ this.name = name; } /** * 获得节点信息 * @return */ public String getInfo(){ return "名称:"+name; } }
改造后的File类
/** * 叶子节点(文件) */ public class File extends Node { /** * 调用父类的构造方法 * @param name */ public File(String name) { super(name); } }
改造后的Folder类
/** * 分支节点(文件夹) */ public class Folder extends Node{ /** * 子集 */ private ArrayList children = Lists.newArrayList(); /** * 带参数的构造方法 * @param name */ public Folder(String name){ super(name); } /** * 新增节点,有可能是文件也有可能是文件夹 * @param node */ public void add(Node node){ this.children.add(node); } /** * 获得子集 * * @return */ public ArrayList getChildren() { return children; } }
改造后的使用方式
public class ClientTest { public static void main(String[] args) { //定义根节点 Folder root = new Folder("root"); //定义二级节点的文件夹 Folder imageFolder = new Folder("image-folder"); Folder documentFolder = new Folder("document-folder"); //定义二级节点的文件 File systemFile = new File("system-file.bat"); //定义三级节点的文件夹 Folder pngFolder = new Folder("png-folder"); Folder gifFolder = new Folder("gif-folder"); //定义三级节点的文件 File testHtml = new File("test.html"); File testJS = new File("test.js"); //定义四级节点的文件,两个png文件 File test1png = new File("test1.png"); File test2png = new File("test2.png"); //定义四级节点的文件3个gif文件 File my1gif = new File("my1.gif"); File my2gif = new File("my2.gif"); File my3gif = new File("my3.gif"); //填充一级文件夹 root.add(imageFolder); root.add(documentFolder); root.add(systemFile); //填充二级图片文件夹 imageFolder.add(pngFolder); imageFolder.add(gifFolder); //填充二级文档文件夹 documentFolder.add(testHtml); documentFolder.add(testJS); //填充三级png图片文件夹 pngFolder.add(test1png); pngFolder.add(test2png); //填充三级gif图片文件夹 gifFolder.add(my1gif); gifFolder.add(my2gif); gifFolder.add(my3gif); System.out.println(root.getInfo()); //打印出来 getChildrenInfo(root.getChildren()); } /** * 递归遍历文件 * @param arrayList */ private static void getChildrenInfo(ArrayList arrayList){ int length = arrayList.size(); for(int m = 0;m<length;m++){ Object item = arrayList.get(m); //如果是叶子节点就直接打印出来名称 if(item instanceof File){ System.out.println(((File) item).getInfo()); }else { //如果是分支节点就先打印分支节点的名称,再递归遍历子节点 System.out.println(((Folder)item).getInfo()); getChildrenInfo(((Folder)item).getChildren()); } } } }
这样实现起来的各个节点的代码变的更简洁了,但是组装数据的的代码是没变的。因为放数据要么自己造要么从某个地方查询出来,这么个步骤是不能简化的。
分析
现在我们的这个实现过程就是使用的了组合模式,下面我们来分析一下组合模式都有哪些部分组成。先来看一下根据上面这个例子画出来的类图。
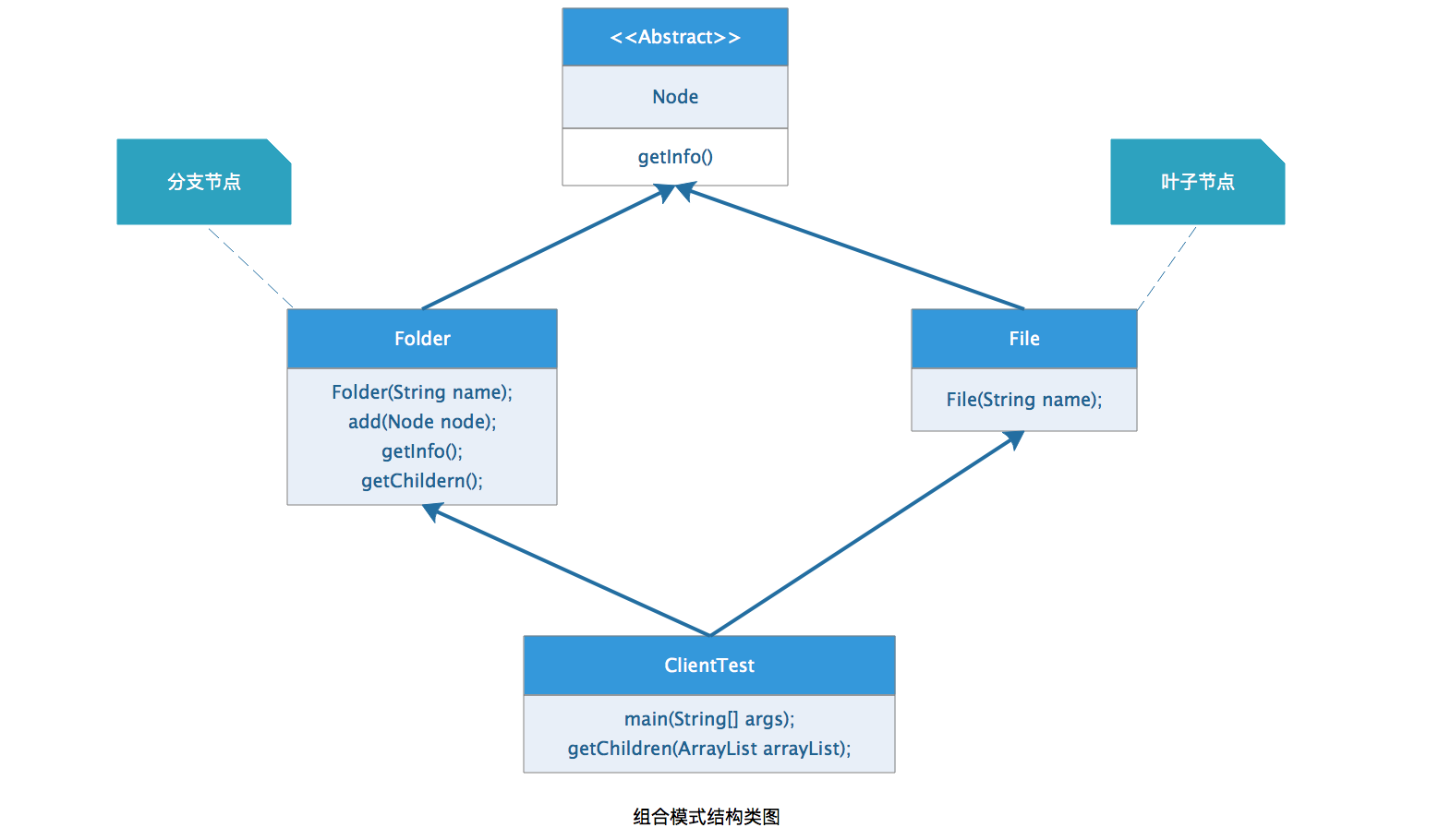
组合模式主要有这么几个角色:
抽象构件角色:
(Node类)这是一个抽象角色,它给参加组合的对象规定一个接口或抽象类,给出组合中对象的默认行为。
叶子构件角色:
(File类)代表参加组合的叶子节点对象,没有子集,并且要定义出参加组合的原始对象行为。
树枝构件角色:
(Folder类)代表参加组合的含义子对象的对象,并且也要给出参加组合的原始对象行为以及遍历子集的行为。
组合模式的两种形式
透明方式
透明方式来实现组合模式是指,按照上面举得例子来说,File和Folder的方法和和属性都一样,就是说File也包含children属性和getChildren方法两者在类上没有什么区别,只不过File的children为null,getChildren()获得的也永远是空。这样叶子节点对象和树枝节点对象的区别在抽象层次上就消失了,客户端可以同等对待所有对象。
这种方式的缺点是不够安全,因为叶子节点和树枝节点在本质上是有区别的,叶子节点的getChildren()方法和children的存在没有意义,虽然在编译时不会出错,但是如果在运行时之前没有做过处理是很容易抛出异常的。
安全方式(非透明)
安全方式实现的组合模式,就是上面的例子介绍的那样,这种实现方式把叶子和树枝彻底的区分开来处理,并做到互不干扰,树枝有单独自己处理子类的方法,保证运行期不会出错。
一般在如下情况下应当考虑使用组合模式:
- 需要描述对象的部分和整体的等级结构。
- 需要客户端忽略掉个体构件和组合构件的区别,客户端平等对待所以构件。
其实在我们日常的业务当中有很多场景其实都是可以使用组合模式的,例如,某公司的人员组织结构,从CEO到小职员,一级一级的人员关系就可以使用组合模式,还有就是在网上商城购物时,选择地址,从省道区再到县也是可以使用组合模式的。
想了解更多的设计模式请查看Java设计模式学习记录-GoF设计模式概述。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号