mysql join语句分析(二)
join表优化
create table t1(id int primary key, a int, b int, index(a));
create table t2 like t1;
假设在表t1里,插入了1000行数据,每一行a=1001 - id,表t1中字段a是逆序的,同时t2插入了100万行数据。
Multi-Range Read优化
这个优化的目的是尽量使用顺序读盘。
select * from t1 where a>=1 and a<=100;
主键索引是b+树,在这颗树上,每次只能根据一个主键id查到一行数据,因此回表是一行行搜索主键索引的。
如果随着a的值递增顺序查询的话,id的值就变成随机的,那么就会出现随机访问,性能相对较差。虽然“按行查”这个机制不能改,但是调整查询的顺序,还是能够加速的。
因为大多数的数据都是按照主键递增顺序插入得到的,所以我们可以认为,如果按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能。
- 根据索引a,定位到满足条件的记录,将id放入到read_rnd_buffer中
- 将buffer中的id按递增顺序排列,
- 排序后的id数组,依次到主键id索引中查记录,返回结果。
- 如果buffer反满了,就会执行完2,3,清空buffer,之后继续招索引a的下个记录,并继续循环。
- MRR能够提升性能的核心在于,这条查询语句在索引a上做的是一个范围查询,也就是一个多值查询,可以得到足够多的id,这样通过排序以后,再去主键索引查数据,才能体现顺序优势。
Batched Key Access
回顾以下NLJ算法的执行逻辑,从驱动表t1,一行行的取出a,再到t2中去join,对于t2来说,每次都是匹配一个值,这样不能多传值给t2,MRR的优势就用不上了。
可以先取出表t1的数据取出一部分,放到join_buffer中,下图就是NLJ算法优化后的BKA算法流程。
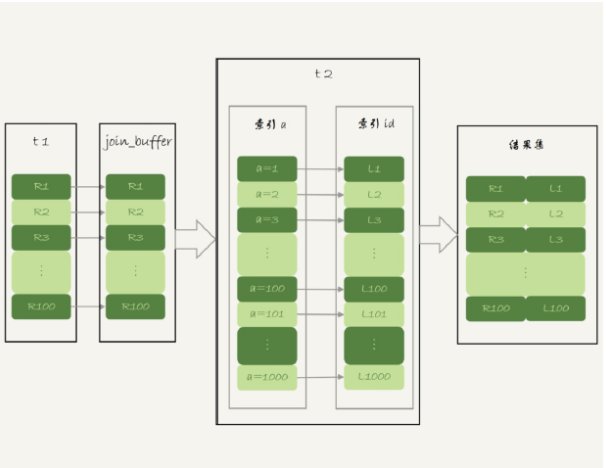
BNL算法的性能问题
- 可能会多次扫描被驱动表,占用IO资源。
- 判断join条件需要执行M*N次对比,如果是大表就会占用非常多的CPU资源,
- 可能会导致Buffer Pool的热数据淘汰,影响内存命中率。
在执行语句前,先应该分析和查看explain结果的方式,确认是否要使用BNL算法,如果优化器会选择BNL做法,应该给被驱动表加上索引,把BNL算法转化成BKA算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号