yarn工作机制
大致过程
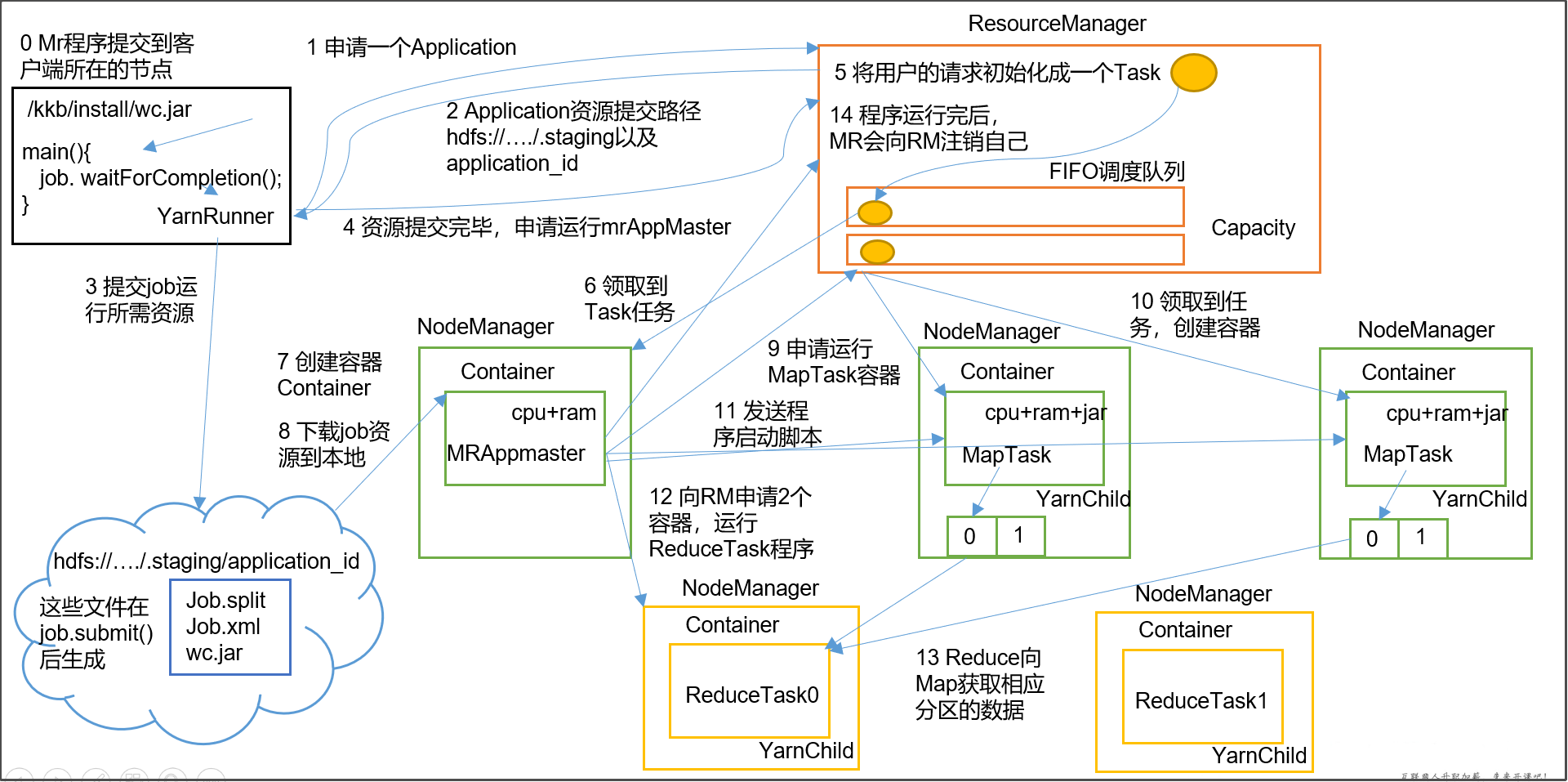
- MR程序提交到客户端所在的节点。
- YarnRunner向ResourceManager申请一个Application。
- RM将该应用程序的资源路径返回给YarnRunner。
- 该程序将运行所需资源提交到HDFS上。
- 程序资源提交完毕后,申请运行mrAppMaster。
- RM将用户的请求初始化成一个Task。
- 其中一个NodeManager领取到Task任务。
- 该NodeManager创建容器Container,并产生MRAppmaster。
- Container从HDFS上拷贝资源到本地。
- MRAppmaster向RM 申请运行MapTask资源。
- RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
- MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
- MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
- ReduceTask向MapTask获取相应分区的数据。
- 程序运行完毕后,MR会向RM申请注销自己。
详细过程
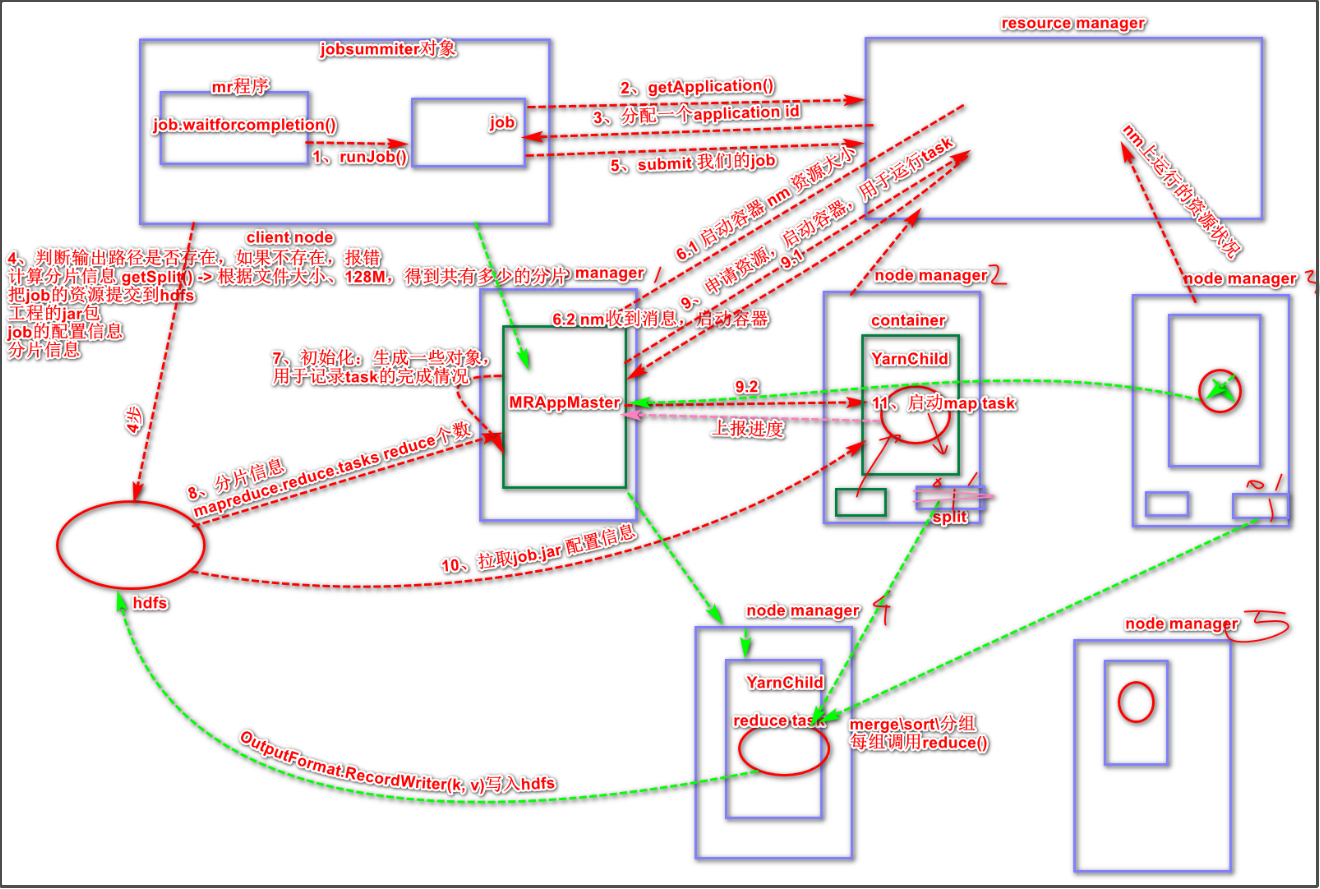
MR程序(可以理解成jar包)提交到客户端所在的节点,MR程序里面有一个Job.waitforcompletion()方法,这个方法会生成一个jobsummiter实例对象,然后这个过程还会通过jobsummiter调用runJob()方法。- 客户端与
ResourceManager进行通信,调用getApplication()方法申请一个应用,RM收到申请后,返回分配给客户端一个applicaion id。
- 客户端判断
MR程序的输入路径是否存在,若不存在则报错。然后客户端会计算分片信息,比如根据文件大小得到要多少个分片。
4. 上述操作无误后,客户端把Job资源提交到hdfs。Job资源包括jar包、job的配置信息(job.xml)、分片信息。
- 客户端
summit提交 job,RM收到提交后,根据各个NodeManager上运行的资源状况向某个NM节点发送启动容器的请求,该NM收到RM的请求会启动一个容器Container。然后在该容器上启动一个MRAppMaster进程(进程运行在JVM虚拟机里)。
MRAppMaster进行初始化,生成一些对象,用于记录task的完成情况。MRAppMaster从hdfs获取分片信息(得知maptask个数)以及reducetask个数。MRAppMaster向RM申请资源,启动容器,用于运行task。MRAppMaster会优先为Maptask申请资源。RM会返回要在哪几个Nodemanager开启容器、这个容器有多少资源等信息。MRAppMaster与RM返回的所有NM节点,进行通信。NM收到信息后,就会在本地启动容器。- 在容器内启用
YarnChild类,从hdfs拉取job.jar包、配置信息等一些运行task的资源。然后每个容器就可以启动一个maptask了。
- 接下来
maptask运行的过程,就跟我们前面的学的maptask工作机制一样了。
- 当整个
job中的maptask的进程达到5%的时候,MRAppMaster就开始向RM为reducetask申请资源,启动容器。(每个Maptask运行过程都会向MRAppMaster上报进度信息,进度信息可看成是已经输入的数据占所有数据的百分比)
- 然后
RM再次返回要开启容器的NM节点信息,MRAppMaster再跟这些NM通信,NM启动容器,启用YarnChild,最后开启reducetask。
reducetask要从完成100%进度的maptask的所在节点拷贝数据过来自身所在节点。(maptask会向MRAppMaster上报进度信息,这些信息保存在MRAppMaster初始化生成的对象里,reducetask会不定期跟MRAppMaster通信,询问哪个maptask完成了)- 接下来
reducetask的过程就跟我们前面学的reducetask工作机制一样了,最终会把输出结果保存到hdfs里。
补充:
- 每个
task完成后,容器都会被释放掉。
- 每个
maptask完成后,maptask在本地磁盘产生的临时文件都会被删除掉
- 程序运行完毕后,
MR会向RM申请注销自己,MRAppMaster所在容器也会释放掉。
- 我们在运行MR程序的时候可以发现,会打印一些进度、计数器等信息出来,这是因为每个task在运行过程都会向
MRAppMaster上报,如果在编写MR程序的时候,为job.waitForCompletion();传入参数true,客户端就会每隔几秒向MRAppMaster获取最新进度信息,取到就打印出来。
MRAppMaster为maptask申请资源时,会把maptask的要使用的数据分片的所在节点信息一带发送给RM,如果分片所在的节点的资源是足够使用的话,RM会优先考虑这些NM节点,这样maptask运行直接从本地磁盘读数据就可以了,更高效点,这是移动计算不移动数据的思想。- 企业生产当中,一般是一个节点(机器)同时运行
datanode+namanode。效率更高点。
- 如果
task运行失败,MRAppMaster会知道,并会为task重新申请资源容器,且优先考虑其它的NM节点,每个task有4次重试机会,如果超过4次,整个job失败。
MRAppMaster会向RM发送心跳,如果超过一定时间,RM没有收到心跳,会判断MRAppMaster挂掉了。如果MRAppMaster运行失败,会启动一个新容器,运行MRAppMaster。新的MRAppMaster可以得知之前的task完成情况,因为启用了历史日志服务,任务完成情况会记录在内。maptask和reducetask的进度等信息都会保存在MRAppMaster初始化产生的对象里。- 每个
job对应一个MRAppMaster。
posted @
2020-08-26 23:27
Whatever_It_Takes
阅读(
332)
评论()
收藏
举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号