spark(9)spark程序的序列化问题及解决方法
spark程序的序列化问题
transformation操作为什么需要序列化
spark是分布式执行引擎,其核心抽象是弹性分布式数据集RDD,其代表了分布在不同节点的数据。Spark的计算是在executor上分布式执行的,所以用户执行RDD的map,flatMap,reduceByKey等transformation 操作时可能有如下执行过程:
- 代码中对象在driver本地序列化
- 对象序列化后传输到远程executor节点
- 远程executor节点反序列化对象
- 最终远程节点执行
这些操作要序列化的原因:
我们知道,transformation这些算子都是要传入参数的,而且很多的参数都是函数,类似于闭包,闭包可简单理解成“定义在一个函数内部的函数”。
假如说作为算子参数的函数是:x=>(x,外部定义的对象或变量等),外部定义的对象或变量等是在driver端创建的,那么如果作为算子参数的函数要使用外部的东西,就要从driver端拉取外部对象等过来到当前executor,从而使用。
因此,对象在执行中需要序列化通过网络传输,则必须经过序列化过程。
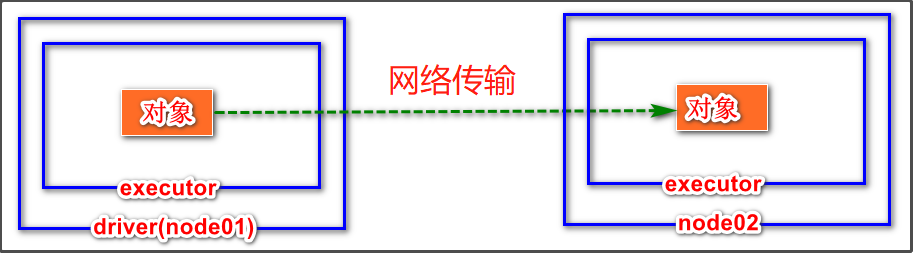
spark的任务序列化异常原因
报错的可能原因
在编写spark程序中,由于在map,foreachPartition等算子内部使用了外部定义的变量和函数,从而引发Task未序列化问题。
然而spark算子在计算过程中使用外部变量在许多情形下确实在所难免,比如在filter算子根据外部指定的条件进行过滤,map根据相应的配置进行变换。
经常会出现“org.apache.spark.SparkException: Task not serializable”这个错误,出现这个错误的原因可能是:
- 这些算子使用了外部的变量,但是这个变量不能序列化。
- 当前类使用了“extends Serializable”声明支持序列化,但是由于某些字段不支持序列化,仍然会导致整个类序列化时出现问题,最终导致出现Task未序列化问题。
示例1:
数据库连接定义在了foreachPartition算子外部,当算子内部要使用该连接时,就出现了序列化错误。这是因为这个数据库连接是在driver端构建的,而数据库连接没有实现序列化,无法传输到不同机器的executor,就报错了。
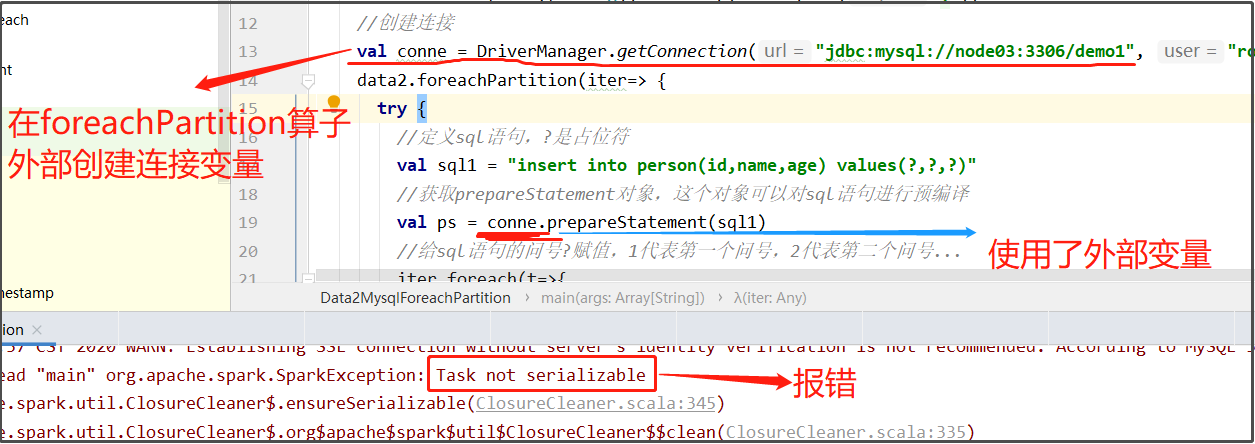
示例2:
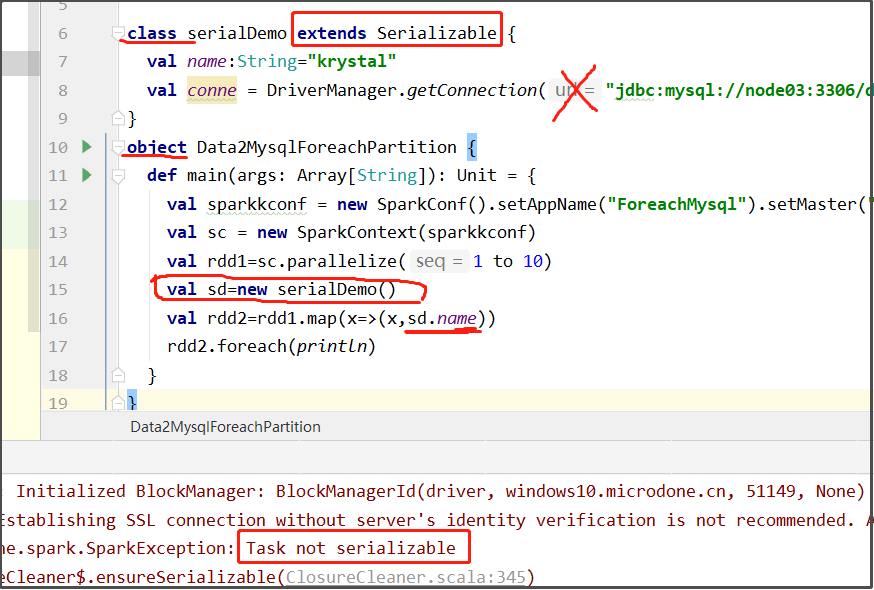
看下图,serialDemo是在object外部定义的类,虽然serialDemo extends Serializable实现序列化,但是,因为该类里面的数据库连接是conne是不支持序列化的,导致序列化不成功。虽然引用的是name变量,但还是报错了。
如果函数中使用了该类对象的成员变量,该类除了要实现序列化之外,所有的成员变量必须要实现序列化。
spark中解决序列化问题的办法
- 如果函数中使用了该类对象,该类要实现序列化,序列化方法:class xxx extends Serializable{}
- 如果函数中使用了该类对象的成员变量,该类除了要实现序列化之外,所有的成员变量必须要实现序列化
- 对于不能序列化的成员变量使用“@transient”标注,告诉编译器不需要序列化
- 也可将依赖的变量独立放到一个小的class中,让这个class支持序列化,这样做可以减少网络传输量,提高效率。
- 可以把对象的创建直接在该函数中构建这样避免需要序列化
因此,遵从这些方法,将上面示例2中的代码改成如下就可以运行成功了:
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.{SparkConf, SparkContext}
class serialDemo extends Serializable {
val name:String="krystal"
@transient
val conne = DriverManager.getConnection("jdbc:mysql://node03:3306/demo1", "root", "123456")
}
object Data2MysqlForeachPartition {
def main(args: Array[String]): Unit = {
val sparkkconf = new SparkConf().setAppName("ForeachMysql").setMaster("local[2]")
val sc = new SparkContext(sparkkconf)
val rdd1=sc.parallelize(1 to 10)
val sd=new serialDemo()
val rdd2=rdd1.map(x=>(x,sd.name))
rdd2.foreach(println)
}
}
运行结果为:
(6,krystal)
(1,krystal)
(2,krystal)
(3,krystal)
(4,krystal)
(5,krystal)
(7,krystal)
(8,krystal)
(9,krystal)
(10,krystal)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号