spark(6)RDD概念、RDD五大属性、RDD创建方式
🌈RDD
RDD是什么
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD是spark core的底层核心。
- Dataset:就是一个集合,存储很多数据.
- Distributed:它内部的元素进行了分布式存储,方便于后期进行分布式计算.
- Resilient:表示弹性,rdd的数据是可以保存在内存或者是磁盘中.
RDD的五大属性(重要)
ctrl+左击查看RDD的部分源码(如果看不了就download source),源码中对RDD的描述如下:
/**
* A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable,
* partitioned collection of elements that can be operated on in parallel. This class contains the
* basic operations available on all RDDs, such as `map`, `filter`, and `persist`. In addition,
* [[org.apache.spark.rdd.PairRDDFunctions]] contains operations available only on RDDs of key-value
* pairs, such as `groupByKey` and `join`;
* [[org.apache.spark.rdd.DoubleRDDFunctions]] contains operations available only on RDDs of
* Doubles; and
* [[org.apache.spark.rdd.SequenceFileRDDFunctions]] contains operations available on RDDs that
* can be saved as SequenceFiles.
* All operations are automatically available on any RDD of the right type (e.g. RDD[(Int, Int)])
* through implicit.
*
* Internally, each RDD is characterized by five main properties:
*
* - A list of partitions
* - A function for computing each split
* - A list of dependencies on other RDDs
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
* an HDFS file)
*
* All of the scheduling and execution in Spark is done based on these methods, allowing each RDD
* to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for
* reading data from a new storage system) by overriding these functions. Please refer to the
* <a href="http://people.csail.mit.edu/matei/papers/2012/nsdi_spark.pdf">Spark paper</a>
* for more details on RDD internals.
*/
从上面源码中,可以得到RDD的五大属性:
属性1:A list of partitions
一个分区列表,这里表示一个rdd有很多分区,每一个分区内部是包含了该RDD的部分数据,spark中任务是以task线程的方式运行, 一个分区就对应一个task线程。
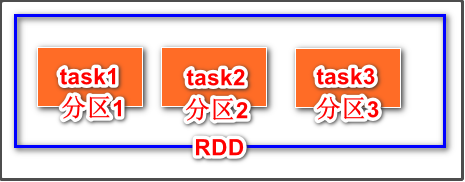
用户可以在创建RDD时指定RDD的分区个数,如果没有指定,那么就会采用默认值。
val rdd=sparkContext.textFile("/words.txt")
分区数的默认值的计算公式如下:
RDD的分区数=max(文件的block个数,defaultMinPartitions)
//通过Spark Context读取hdfs上的文件来计算分区数
属性2:A function for computing each split
一个计算每个分区的函数,这里表示Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute计算函数以达到这个目的.
属性3:A list of dependencies on other RDDs
一个rdd会依赖于其他多个rdd,这里涉及到rdd与rdd之间的依赖关系,spark任务的容错机制就是根据这个特性(血统)而来。
val rdd1:RDD[String]=sc.textFile("/words.txt")
val rdd2:RDD[String]=rdd1.flatMap(x=>x.split(" "))
val rdd3:RDD[(String,Int)]=rdd2.Map(x=>(x,1))
val rdd6=rdd4.join(rdd5)
rdd2依赖于rdd1,而rdd3依赖于rdd2
rdd6依赖于rdd4、rdd5
属性4:Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
一个Partitioner,即RDD的分区函数(可选项)
当前Spark中实现了两种类型的分区函数,
- 基于哈希的HashPartitioner,(key.hashcode % 分区数= 分区号)。它是默认值
- 基于范围的RangePartitioner。
什么会有Partitioner?
- 只有对于key-value的RDD(RDD[(String, Int)]),并且产生shuffle,才会有Partitioner,
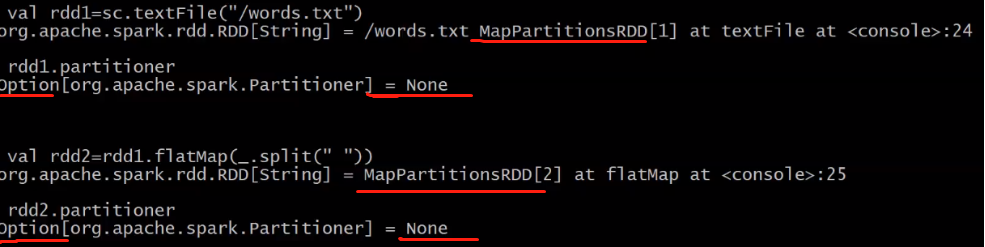
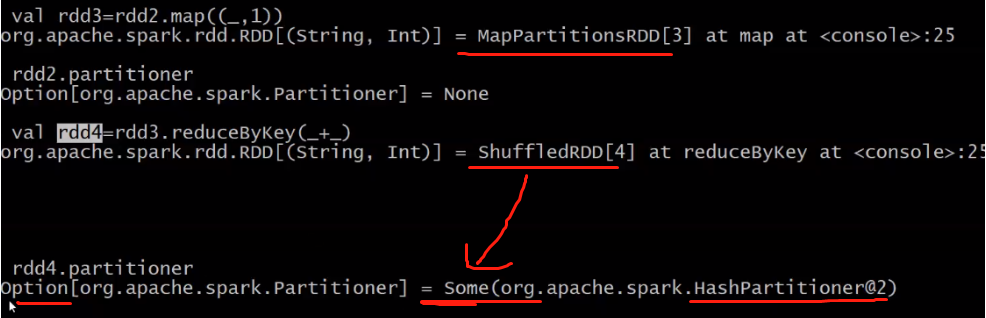
- 非key-value的RDD(RDD[String])的Parititioner的值是None。
Option类型:可以表示有值或者没有值,它有2个子类:
- Some:表示封装了值
- None:表示没有值
属性5:Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
一个列表,存储每个Partition的优先位置(可选项),这里涉及到数据的本地性,数据块位置最优。
spark任务在调度的时候会优先考虑存有数据的节点开启计算任务,减少数据的网络传输,提升计算效率。
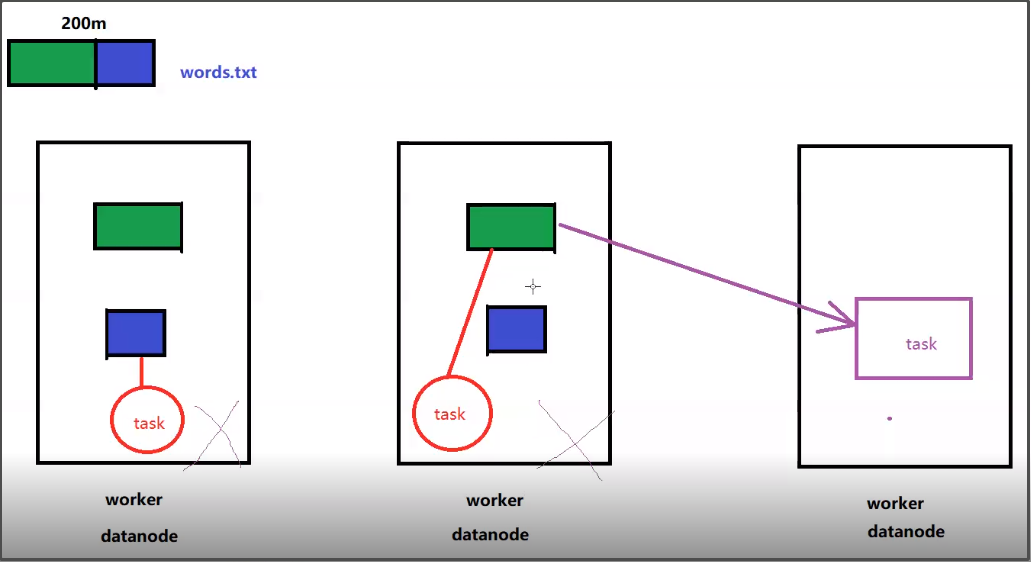
基于spark的单词统计程序剖析rdd的五大属性
需求
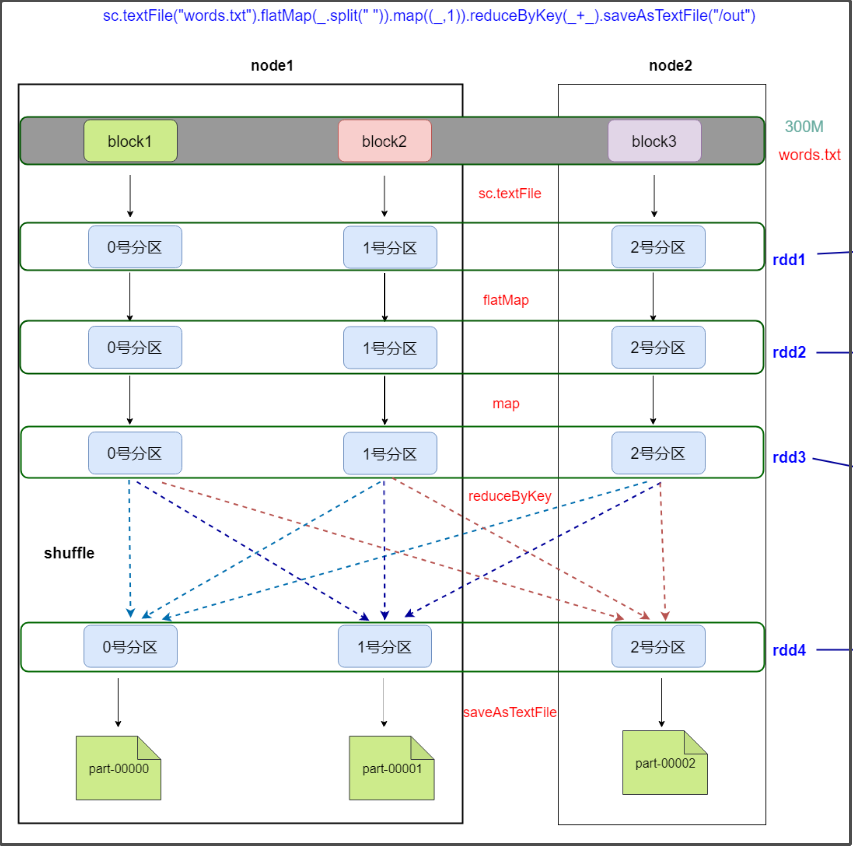
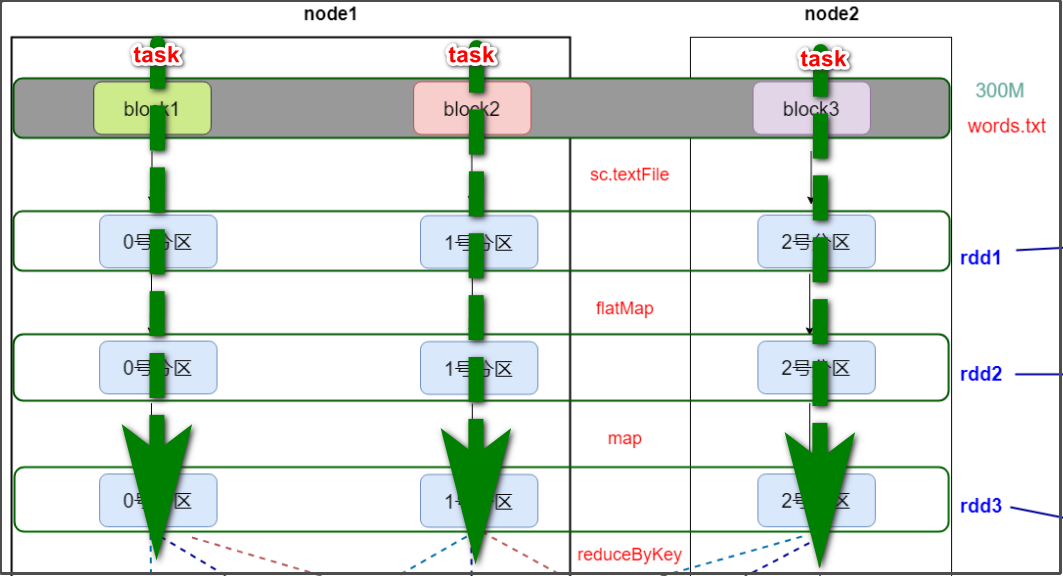
HDFS上有一个大小为300M的文件,通过spark实现文件单词统计,最后把结果数据保存到HDFS上
要执行的代码
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/out")
流程分析
大致流程:
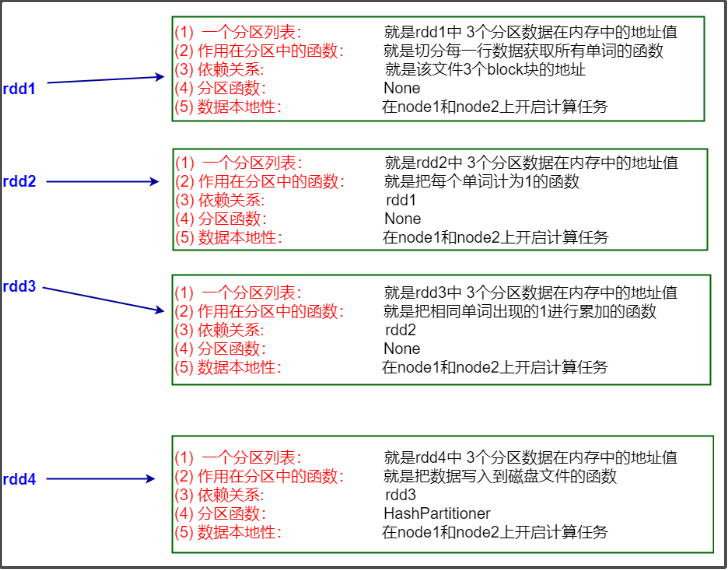
每个rdd的解释:
完整图:
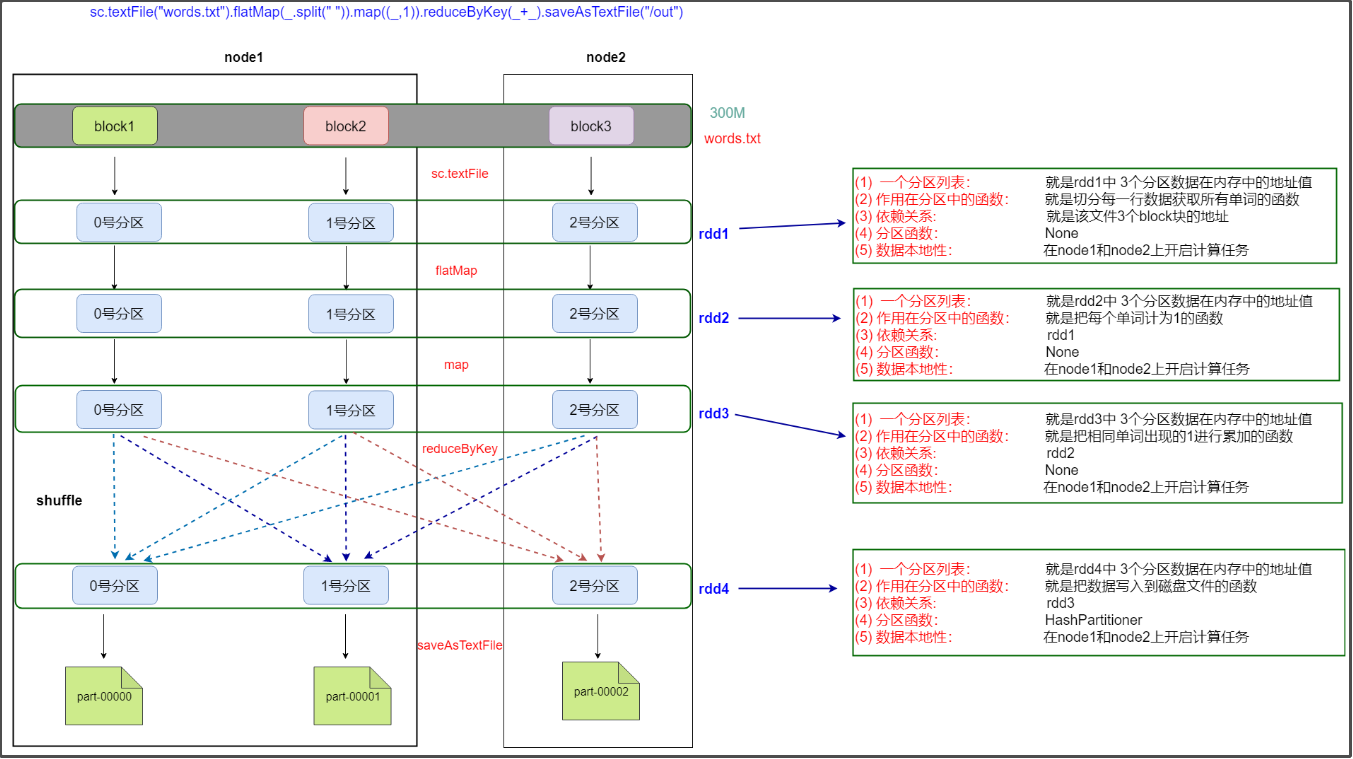
partitioner的解析:
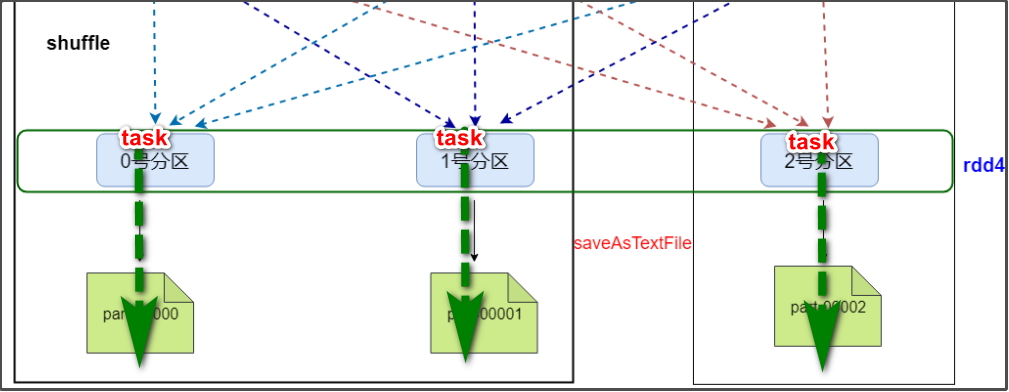
rdd1,rdd2,rdd3的partitioner都是None,经过shuffle,rdd4的partitioner为HashPartitioner。
为什么计算小文件会生成两个结果文件?
通过上面的流程分析,可以知道,加载一个文件时,文件的block个数就是默认的分区个数,而一个分区对应生成一个结果文件。
那为什么我们之前计算words.txt这么一个只有1个block的小文件时,会生成2个结果文件?按道理不是1个才对?
这跟加载数据文件的textFile()方法的参数有关,首先来看一下textFile()的源码:
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
可以看到,textFile方法,有两个参数,path和minPartitions,而我们之前使用的时候,只填了一个参数,如:val data:RDD[String]=sc.textFile(args(0))
这样的话,最小分区数minPartitions就会使用默认值defaultMinPartitions,再来看一下defaultMinPartitions的源码:
def defaultMinPartitions: Int = math.min(defaultParallelism, 2)
defaultMinPartitions是一个方法,返回值是math.min(defaultParallelism, 2)
defaultParallelism是默认并行度,一般是大于2的数,所以math.min(defaultParallelism, 2)=2
因此,最小分区数minPartitions=2,这就是计算分析小文件会生成2个文件的原因。
拓展:并行与并发
并发
并发(Concurrent),在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。
并发不是真正意义上的“同时进行”,只是CPU把一个时间段划分成几个时间片段(时间区间),然后在这几个时间区间之间来回切换,由于CPU处理的速度非常快,只要时间间隔处理得当,即可让用户感觉是多个应用程序同时在进行。如:打游戏和听音乐两件事情在同一个时间段内都是在同一台电脑上完成了从开始到结束的动作。那么,就可以说听音乐和打游戏是并发的。
并行
并行(Parallel),当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。
其实决定并行的因素不是CPU的数量,而是CPU的核心数量,比如一个CPU多个核也可以并行。
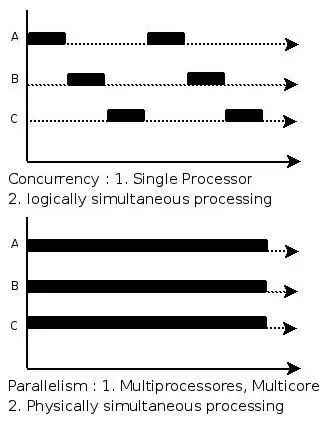
并行与并发示意图
如下图所示:(并发与并发示意图)
 **
**
所以,并发是在一段时间内宏观上多个程序同时运行,并行是在某一时刻,真正有多个程序在运行。
并行和并发的区别
-
并发,指的是多个事情,在同一时间段内同时发生了。
-
并行,指的是多个事情,在同一时间点上同时发生了。
-
并发的多个任务之间是互相抢占资源的。
-
并行的多个任务之间是不互相抢占资源的。
只有在多CPU或者一个CPU多核的情况中,才会发生并行。否则,看似同时发生的事情,其实都是并发执行的。
spark的并行
一个文件有多个block,一个block对应一个分区,一个分区就会对应一个task,一个task对应一个线程,多个线程并行运行:
以上面的300M的文件的计算为例,分析spark中的并行:
并行运行1:
并行运行2:
RDD的创建方式
RDD的创建方式有3种:
1、通过已经存在的scala集合去构建,前期做一些测试用到的比较多
val rdd1=sc.parallelize(List(1,2,3,4,5)) //parallelize可以添加第2个参数,是分区的数量
val rdd2=sc.parallelize(Array("hadoop","hive","spark"))
val rdd3=sc.makeRDD(List(1,2,3,4))
//parallelize表示并行化
无论传入的是什么,元素最终都是用Array封装的:

2、加载外部的数据源去构建
val rdd1=sc.textFile("/words.txt")
3、从已经存在的rdd进行转换生成一个新的rdd
val rdd2=rdd1.flatMap(_.split(" "))
val rdd3=rdd2.map((_,1))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号