Hive(4) hive概念、与数据库的区别、hive优缺点、hive架构原理
Hive的概念
Hive是基于Hadoop的一个数据仓库工具
-
可以将结构化的数据文件映射为一张数据库中的表,并提供类
SQL查询功能。 -
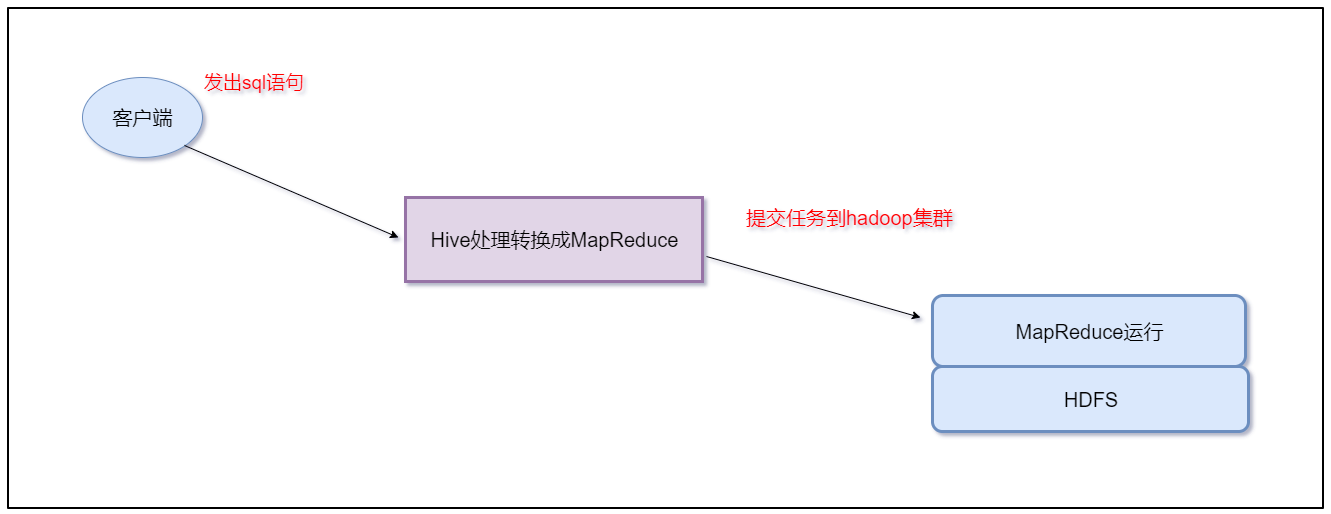
其本质是将
SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储支持,说白了hive可以理解为一个将SQL转换为MapReduce任务的工具,甚至更进一步可以说hive就是一个MapReduce的客户端。

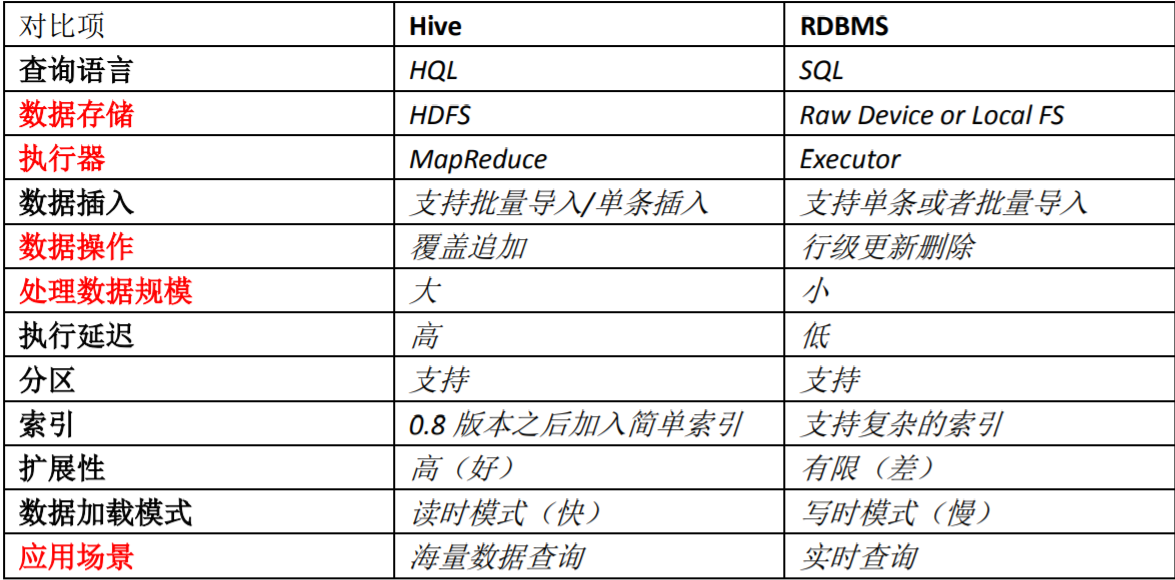
Hive与数据库的区别
-
Hive 具有 SQL 数据库的外表,但应用场景完全不同。
-
Hive 只适合用来做海量离线数据统计分析,也就是数据仓库。
Hive的优缺点
-
优点
-
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
-
避免了去写MapReduce,减少开发人员的学习成本。
-
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
-
-
缺点
-
Hive 的查询延迟很严重
-
Hive 不支持事务
-
Hive架构原理
-
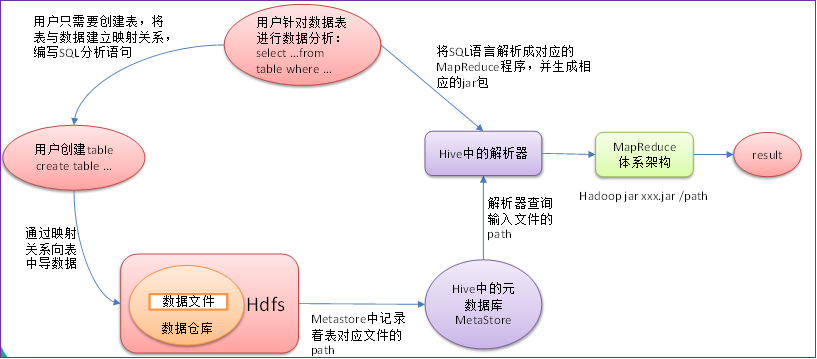
1、用户接口:
Client-
CLI(hive shell) -
JDBC/ODBC(java访问hive)--》启动hiveserver2,通过jdbc协议访问hive,hiveserver2支持高并发。 -
WEBUI(浏览器访问hive)
-
-
2、元数据:
Metastore-
元数据包括:表名、表所属的数据库(默认是
default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等; -
元数据默认存储在自带的
derby数据库中,推荐使用MySQL存储Metastore。 -
我们安装
hive时,在配置文件里设置了元数据保存在node03的mysql的某个数据库里。如下:<property> <name>javax.jdo.option.ConnectionURL</name <value>jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true&characterEncoding=latin1&useSSL=false</value> </property>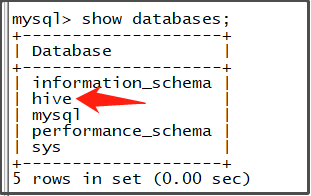
-
-
3、
Hadoop集群- 使用
HDFS进行存储,使用MapReduce进行计算。
- 使用
-
4、
Driver:驱动器-
解析器(
SQL Parser)-
将
SQL字符串转换成抽象语法树AST -
对
AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误
-
-
编译器(
Physical Plan):将AST编译生成逻辑执行计划 -
优化器(
Query Optimizer):对逻辑执行计划进行优化 -
执行器(
Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说默认就是mapreduce任务
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号