

tensorflow源码分析
前言:
一般来说,如果安装tensorflow主要目的是为了调试些小程序的话,只要下载相应的包,然后,直接使用pip install tensorflow即可。
但有时我们需要将Tensorflow的功能移植到其它平台,这时就无法直接安装了。需要我们下载相应的Tensorflow源码,自已动手编译了。
正文:
Tensorflow功能代码庞大,结构复杂;如何快速了解源码结构,就显示尤为重要了。
Tensorflow主体结构:
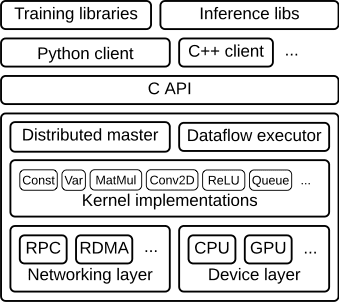
整个框架以C API为界,分为前端和后端两大部分。
前端:提供编译模型,多语言接口支持,如:python,java,c++等。
后端:提供运行环境,完成计算图执行,大致可分为4层:
运行层:分布式运行时和本地运行时,负责计算图的接收,构造,编排等;
计算层:提供各算子的内核实现,例如: conv2d,relu等;
通信层:实现组件间数据通信,基于GRPC,RDMA两种通信方式;
设备层:提供多种异构设备支持,如:CPU,GPU,TPU,FPGA等;
模型构造和执行流程:
Tensorflow图的构造与执行是分开的,用户添加完算子,构建好图后,才开始进行训练和执行。
流程如下:
1、图构建:用户在Client中基于Tensorflow的多语言编程接口,添加算子,完成计算图的构造;
2、 图传递:Client开启Session,通过它建立和Master之间的连接,执行Session.run()时,将构造好的graph序列化为graphdef后,以protobuf格式传递给master。
3、图剪枝:master 根据session.run()传递的fetches和feeds列表,反向遍历全图full graph,实施剪枝,得到最小依赖子图;
4、图分裂:master将最小子图分裂为多个graph partition,并注册到多个worker上,一个worker对应一个graph partition;
5、图二次分裂:worker根据当前可用硬件资源,如CPU,GPU,将graph partition按照op算子设备约束规范( 例如:tf.device('/cpu:0')),二次分裂到不同设备上。每个计算设备对应一个 graph partition.
6、图运行:对于每一个计算设备,worker依照op在kernel中的实现,完成op的运算。设备间数据通信可以使用send/recv节点,而worker间通信,则使用GRPC或RDMA协议。
前端多语言实现:Swig包装器
Tensorflow提供了多种语言的前端接口,使得用户可以通过多种语言来完成模型的训练和推断。如何实现要归功于swig包装器。
swig是一个帮助C或C++编写的软件能与其它各种高级编程语言进行嵌入联接的开发工具,在Tensorflow使用bazel编译时,swig会生成两个wrapper文件:
1、pywrap_tensorflow_internal.py :对接上层Python调用
2、pywrap_tensorflow_internal.cc :对接底层C API调用
pywrap_tensorflow_internal.py模块被导入时,会加载_pywrap_tensorflow_internal.so动态链接库,里面包含所有运行时接口符号。而在pywrap_tensorflow_internal.cc中,注册了一个函数符号表,实现python接口和C接口的映射。运行时,可以通过映射表,找到python接口在C层的实现。
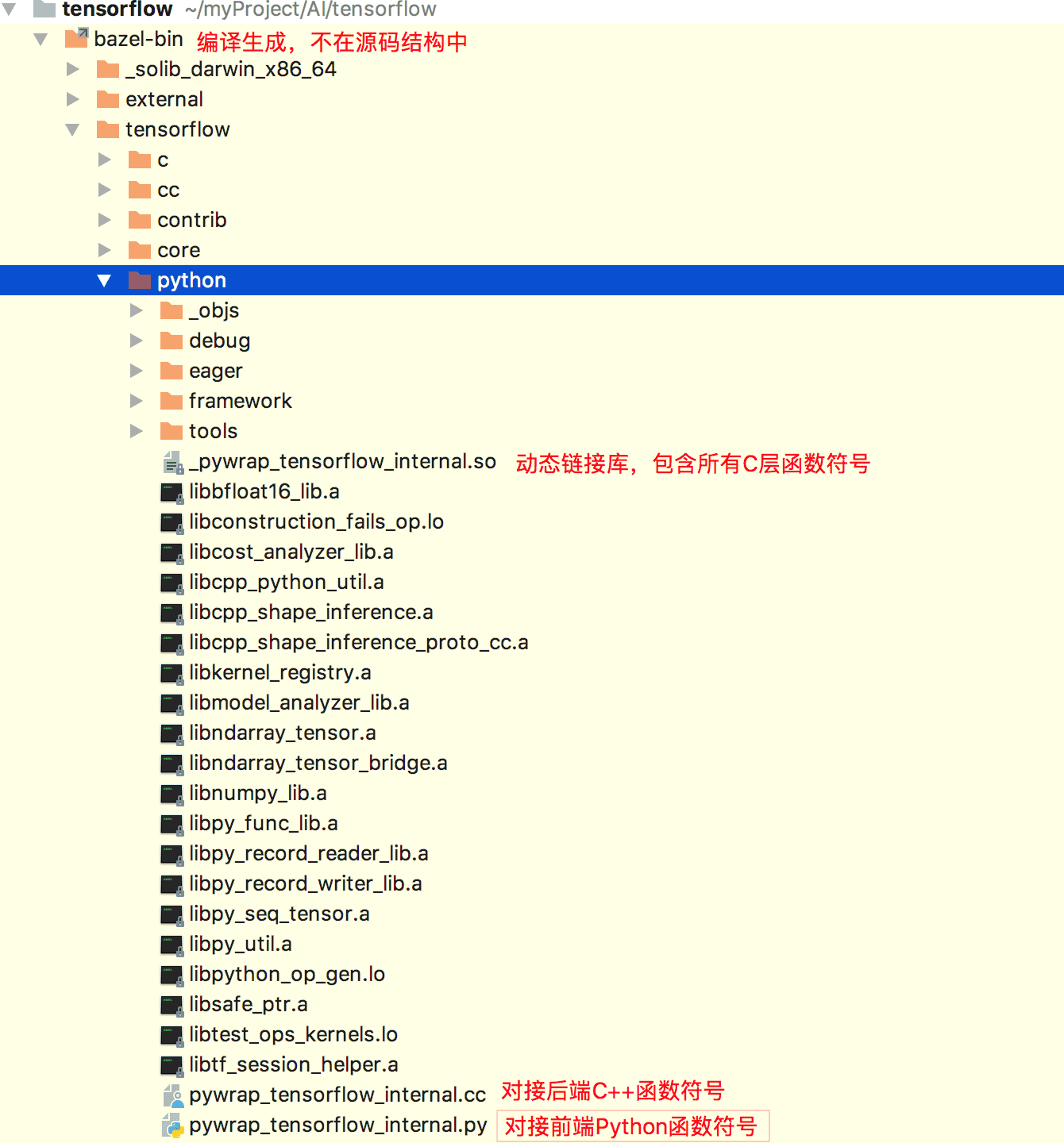
Tensorflow源码结构
Tensorflow源码基本按照框架分层来组织文件,如下图:

其中目录core是tensorflow的核心,源码结构如下:

Session:
Session是连接前后端的桥梁,用户可利用session使得client能够与master的执行引擎建立连接,通过session.run()来触发一次计算。
Session创建时,系统会分配一些资源,如graph引用,连接的计算引擎名称等,所以,计算完毕后,需要使用session.close()关闭session,避免引起内存泄漏,特别是graph无法释放问题。可以显式调用Session.close(),使用with上下文管理器,或使用InteractiveSession()
session之间采用共享graph方式来提高 运行效率。一个session只能运行一个graph实例,但一个graph可以运行在多个session中。在session创建时,不会重新创建graph实例,而是默认graph引用计算加1.当session close时,引用计数减1.只有引用计数为0时,graph才会被回收。
在后端master中,根据前端client调用tf.session(target='',graph=none,config=none)时指定的target,来创建不同的session.target为要连接的tf后端执行引擎,默认为空字符串。Session创建了抽象工厂模式,如果为空字符串,则创建本地DirectSession,如果以grpc://开头,则创建分布式grpcSession。
DirectSession只能利用本地设备,将任务创建在本地的CPU和GPU上。而grpcSession可利用远端分布式设备,将任务创建在其他机器的CPU,GPU上,然后通过grpc协议通信。
Session生命周期,大致有4个阶段:
1、创建:通过tf.session()创建,进行系统资源分配,特别是graph引用计数加1;
2、运行:通过session.run()触发计算的执行,client会将整图graph传递给master,由master进行执行;
3、关闭:通过session.close()关闭,进行系统资源的回收,graph引用计数减1;
4、销毁:Python垃圾回收器进行GC时,调用 session.__del__()回收。
基本都在python的basesession中,通过swig自动生成的函数符号映射关系,调用C层的实现。
未完待续。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号