Doris入门到实战
Doris的介绍
官方文档:https://doris.apache.org/zh-CN/docs/2.0/gettingStarted/what-is-apache-doris
Doris的优点
MPP架构
秒级查询返回延时
兼容MySQL协议
向量执行器
高效的聚合表技术
新型预聚合技术Rollup
高性能、高可用、高可靠
极简运维、弹性伸缩
Doris是什么 ?
是一款基于 MPP 架构的高性能、实时的分析型数据库,以高效、简单、统一的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
什么是MMP架构 ?
Doris 在执行一条 SQL 时,会把计算任务并行地(Parallel)、分布地(Distributed)、无共享地(Shared-Nothing)*地切分到集群中的每一个*独立节点上,节点之间只通过高速网络交换中间结果,最终再把所有局部结果聚合起来返回给用户。这种架构统称 Massively Parallel Processing(大规模并行处理)
Doris 的 MPP 模型 = “把一条查询切成很多小任务,让集群里所有 CPU/磁盘同时开工,节点之间只通过网络交换必要数据,最后把局部结果拼成最终结果”。
因此它在海量数据、复杂分析场景下,比传统单机或主从 MySQL 的“一机扛所有”快一个到两个数量级。
这就是它比MySQL快的原因。
整体架构和技术特点 :
Frontend(FE):主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
Backend(BE):主要负责数据存储、查询计划的执行。
MySQL Client:用户连接Doris
Broker:主要用于备份、导入导出数据(HDFS、S3存储)。
FE:类似于是前端(元数据存储、负责接收查询请求、解析查询请求、规划查询请求、调度查询请求、然后查询结果。)
FE又分三个角色:
1、Leader
2、Follower
3、Observer 负责查询的扩展、不负责写入(只读不写、查询压力大时候可以扩展这个组件)
Observer 节点仅从 Leader 节点同步元数据,不参与选举。可以横向扩展以提供元数据的读服务的扩展性。
BE:一个类似于后端(负责物理数据的存储和计算、写入数据、执行FE的查询计划中的查询规则、并且计算。)
通过副本保障数据的可靠性、
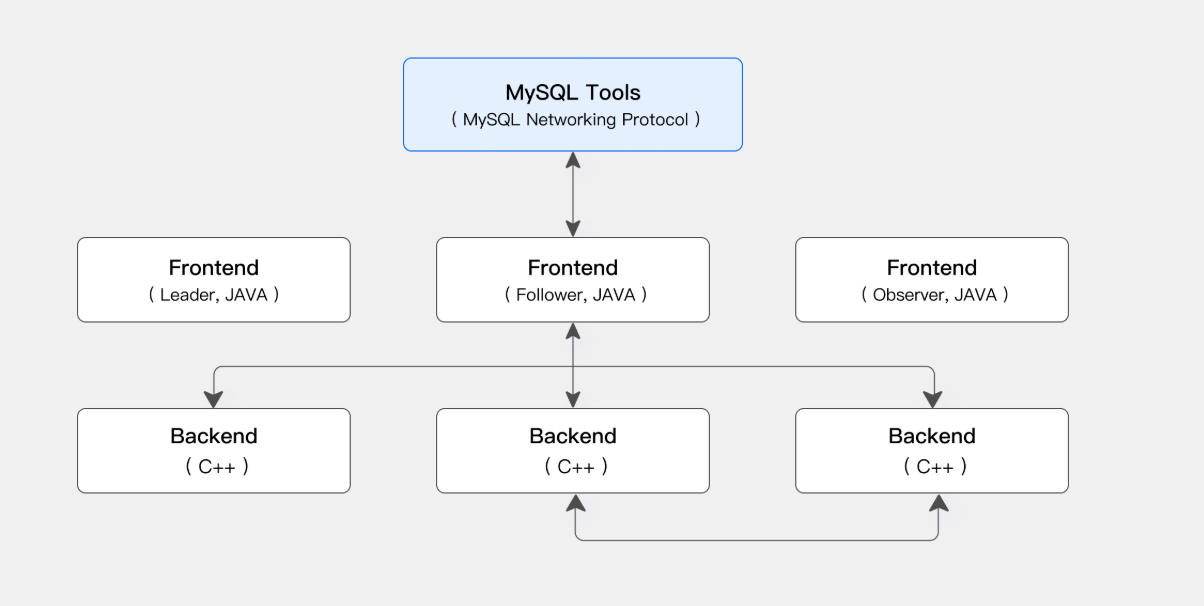
这两类进程都是可以横向(水平)扩展的,单集群可以支持到数百台机器,数十 PB 的存储容量。并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大地降低了一款分布式系统的运维成本。
Doris使用的接口 ?
Apache Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL,用户可以通过各类客户端工具来访问 Apache Doris,并支持与 BI 工具的无缝对接。Apache Doris 当前支持多种主流的 BI 产品,包括不限于 Smartbi、DataEase、FineBI、Tableau、Power BI、Apache Superset 等,只要支持 MySQL 协议的 BI 工具,Apache Doris 就可以作为数据源提供查询支持。
Doris存储数据方式 ?
采用列式存储,按列进行数据的编码压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更加有效利用 IO 和 CPU 资源。
Doris使用的查询引擎 ?
在查询引擎方面,Apache Doris 采用 MPP 的模型,节点间和节点内都并行执行,也支持多个大表的分布式 Shuffle Join,从而能够更好应对复杂查询。
Apache Doris 查询引擎是向量化的查询引擎,所有的内存结构能够按照列式布局,能够达到大幅减少虚函数调用、提升 Cache 命中率,高效利用 SIMD 指令的效果。在宽表聚合场景下性能是非向量化引擎的 5-10 倍。
为什么使用doris 选型对比 ?
| 开源OLAP引擎 | 特点(完整) | 技术融合成本 | 易用性 | 性能 | 运维成本 |
|---|---|---|---|---|---|
| ClickHouse | 列式存储、向量化引擎、单机性能强悍、支持多表 JOIN、支持物化视图、国外用户多 | 高 | 非标准协议 | 满足 | 高 |
| Doris | 列式存储、向量化引擎、支持多表 JOIN、支持物化视图、支持弹性扩容、兼容 MySQL 协议、国内用户多 | 低 | 兼容 MySQL 协议 | 满足 | 低 |
| TiDB | 支持分布式事务、使用简单、生态工具完善、可完全替换 MySQL | 低 | SQL 标准 | 不满足(OLAP 部分) | 低 |
Doris的安装部署 ?
相关文档:
https://doris.apache.org/zh-CN/docs/2.0/install/cluster-deployment/standard-deployment
https://www.modb.pro/db/1899726419832352768
1、前置条件
| 检查项 | 命令/操作 | 不做的后果 |
|---|---|---|
| Java 8 | ${CTRL_DIR}/bin/install_java.sh -p /opt -f java8.tgz |
FE/BE 起不来 |
| CPU 指令集 | grep avx2 /proc/cpuinfo |
如果无 avx2 却用了默认包,BE 会 core dump |
| 内存 | ≥ CPU 核数×4;报表场景 8C16G 也能跑 | OOM 或查询慢 |
| 磁盘 | 50 G 起步;生产 2 TB NVMe | 装不下数据 |
| 文件句柄 | nofile 65536、nproc 65536 |
高并发瞬间报 “Too many open files” |
Doris版本如何选择 ?
稳定版本:2.0.6(1版本也相对稳定、注意2版本的有的有问题)
linux环境:x86-64
运行环境:JDK8
2、二进制安装部署
手动部署 Doris 集群,通常要进行四步规划:
-
软硬件环境检查:检查用户的硬件资源情况及操作系统兼容性
-
操作系统检查:检查操作系统参数及配置
1、硬件检查 当安装 Doris 时,建议选择支持 AVX2 指令集的机器,以利用 AVX2 的向量化能力实现查询向量化加速。 cat /proc/cpuinfo | grep avx2 2、环境配置 16 核机器至少配置 64G 内存 3、关闭swap(注释掉 /etc/fstab 中的 swap 分区,然后重启即可彻底关闭 swap 分区。) swapoff -a 4、检测和关闭系统防火墙、时间同步 systemctl disable firewalld.service systemctl enable ntpd.service 5、设置系统最大打开文件句柄数 vi /etc/security/limits.conf * soft nofile 1000000 * hard nofile 1000000 6、修改虚拟内存区域数量为(修改虚拟内存区域至少 2000000) sysctl -w vm.max_map_count=2000000 7、关闭透明大页(在部署 Doris 时,建议关闭透明大页。) -
集群规划:规划集群的 FE、BE 节点,预估使用资源情况
FE 节点主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。 对于生产集群,一般至少需要部署 3 节点 FE 的高可用环境。FE 节点分为两种角色: 通常情况下,建议部署 3 个 Follower 节点。在高并发的场景中,可以通过扩展 Observer 节点提高集群的连接数。 FE 节点数量 3 副本存储数据 BE 节点数量 3个节点、Follower备用节点、master宕机后去替位。 -
集群部署:根据部署规划进行集群部署操作
-
部署验证:登录并验证集群正确性
#把二进制文件展开,目录结构:fe/、be/、udf/ 等。 tar -xf apache-doris-1.2.7.1-bin-x86.tar.gz -C /data/apps/public #环境变量(以后直接敲 start_fe.sh、start_be.sh 就能找到脚本。) cat <<EOF >> /etc/profile.d/doris.sh export DORIS_HOME=/data/apps/public/apache-doris-1.2.7.1-bin-x86 export PATH=$PATH:$DORIS_HOME/fe/bin:$DORIS_HOME/be/bin export JAVA_HOME=/opt/java EOF source /etc/profile #创建存储目录(storage 放 BE 真实列存文件;doris-meta 放 FE 的元数据(类似 MySQL ibdata1)。) #(priority_networks 让 FE 在有多网卡时绑定正确 IP;stream_load_enable 打开 HTTP 导入。) mkdir -p /data/apps/public/doris/{storage,doris-meta} 配置 FE(/fe/conf/fe.conf) meta_dir = /data/apps/public/doris/doris-meta priority_networks = 10.10.26.0/24 # 写死本机网段 stream_load_enable = true #配置 BE(/be/conf/be.conf) #(storage_root_path 可以写多盘,如 /ssd1,medium:SSD;/hdd1,medium:HDD) enable_stream_load_record = true priority_networks = 10.10.26.0/24 storage_root_path = /data/apps/public/doris/storage #启动FE(--daemon 放后台;第一次启动会在 meta_dir 生成 bdbje 日志。) ./fe/bin/start_fe.sh --daemon jps | grep PaloFe # 看到 PaloFe 即成功 #启动 BE(BE 日志在 be/log/be.out,报端口冲突或磁盘权限错误一眼能看到。) ./be/bin/start_be.sh --daemon ps -ef | grep doris #把 BE 注册到 FE(只需一次)(9050 是 BE 心跳端口;单机填本机 IP。) mysql -h127.0.0.1 -P9030 -uroot ALTER SYSTEM ADD BACKEND "127.0.0.1:9050"; #验证 SHOW PROC '/frontends'\G SHOW PROC '/backends'\G -- Alive=true 即 OK #改 root和admin 密码 SET PASSWORD FOR 'root' = PASSWORD('jigoabo123'); SET PASSWORD FOR 'admin' = PASSWORD('jigaobo123');
部署高可用(3 节点)——只需记住 3 句 SQL
192.168.1.100:9010 Leader
192.168.1.101:9010 Follower
192.168.1.102:9010 Follower
192.168.1.101:9050 BE
192.168.1.102:9050 BE
添加FE节点
1、先起 Master FE(127.0.0.1)
2、在 Master 里加 Follower:
ALTER SYSTEM ADD FOLLOWER "192.168.1.101:9010";
ALTER SYSTEM ADD FOLLOWER "192.168.1.102:9010";
3、可选(添加OBSERVER)
ALTER SYSTEM ADD OBSERVER "<fe_ip_address>:<fe_edit_log_port>"
4、添加Follower(启动第一个 Follower)
#第一次 启动 Follower 时需要加 --helper:(就是添加Leader的地址、后续就不需要了)
./start_fe.sh --helper 127.0.0.1:9010 --daemon # 仅第一次
以后 Follower 再起直接:
./start_fe.sh --daemon
添加BE节点
1. 准备新 BE 节点
硬件要求:与现有 BE 节点配置一致(CPU/内存/磁盘)。
软件部署:
# 解压 Doris 安装包(版本需与集群一致)
tar -zxvf apache-doris-be-x.x.x-bin.tar.gz
cd apache-doris-be-x.x.x
# 修改配置文件 conf/be.conf
vim conf/be.conf
#关键配置项:
priority_networks = 192.168.1.0/24 # 指定BE的IP网段
storage_root_path = /path/to/storage # 数据存储目录(建议SSD)
2. 启动新 BE 节点
# 启动 BE 服务(首次启动无需特殊参数)
./bin/start_be.sh --daemon
3. 将 BE 加入集群
#(通过 MySQL 客户端连接 Doris FE的master:)
mysql -h FE_IP -P 9030 -uroot
#执行添加命令:(BE_IP:9050 是新 BE 节点的 IP 和心跳端口(默认 9050))
ALTER SYSTEM ADD BACKEND "BE_IP:9050";
ALTER SYSTEM ADD BACKEND "192.168.1.101:9050";
ALTER SYSTEM ADD BACKEND "192.168.1.102:9050";
4. 验证节点状态
#检查 Alive 字段是否为 true,LastHeartbeat 是否更新。
#新 BE 的 SystemDecommissioned 应为 false。
SHOW PROC '/backends';
端口速查(单机防火墙全开即可)
9030 客户端 JDBC/MySQL 协议(最重要)
8030 HTTP Stream Load / Web UI
9050 FE→BE 心跳
8040 BE 的 Web UI
9010 FE 之间复制(高可用才用)
3、docker部署
详细文档:https://doris.apache.org/zh-CN/docs/2.0/install/cluster-deployment/run-docker-cluster
1、部署前总结:
用官方镜像 apache/doris:2.0.3-fe-x86_64 和 apache/doris:2.0.3-be-x86_64,单机 1 分钟拉起,3 节点高可用 5 分钟完成,数据持久化到宿主机 /data/doris/*。
2、部署流程:
A[宿主机环境检查] --> B[拉取/构建镜像]
B --> C{部署规模}
C -->|单机| D[docker run fe & be]
C -->|3节点高可用| E[docker-compose up -d]
D --> F[验证:mysql -h127.0.0.1 -P9030 -uroot]
E --> F
F --> G[SHOW PROC '/backends' Alive=true]
3、部署步骤
-
前置
# 系统参数 sysctl -w vm.max_map_count=2000000 # 目录规划 mkdir -p /data/doris/{fe/{doris-meta,log},be/{storage,log}} -
单机 1FE+1BE(最快)
export LOCAL_IP=$(hostname -I | awk '{print $1}') #注意:先启动FE、BE要通过FE加入 # FE docker run -d --name doris-fe \ --env FE_SERVERS="fe1:${LOCAL_IP}:9010" \ --env FE_ID=1 \ -p 8030:8030 -p 9030:9030 \ -v /data/doris/fe/doris-meta:/opt/apache-doris/fe/doris-meta \ -v /data/doris/fe/log:/opt/apache-doris/fe/log \ --net host \ apache/doris:2.0.3-fe-x86_64 # BE docker run -d --name doris-be \ --env FE_SERVERS="fe1:${LOCAL_IP}:9010" \ --env BE_ADDR="${LOCAL_IP}:9050" \ -p 8040:8040 \ -v /data/doris/be/storage:/opt/apache-doris/be/storage \ -v /data/doris/be/log:/opt/apache-doris/be/log \ --net host \ apache/doris:2.0.3-be-x86_64 -
3 节点高可用(示例)
# docker-compose.yml version: "3" services: fe1: image: apache/doris:2.0.3-fe-x86_64 env: [FE_SERVERS="fe1:192.168.1.11:9010,fe2:192.168.1.12:9010,fe3:192.168.1.13:9010", FE_ID=1] ports: ["8030:8030","9030:9030"] volumes: ["/data/doris/fe1:/opt/apache-doris/fe/doris-meta"] network_mode: host fe2: { image: apache/doris:2.0.3-fe-x86_64, env: [FE_SERVERS="...", FE_ID=2], ... } fe3: { image: apache/doris:2.0.3-fe-x86_64, env: [FE_SERVERS="...", FE_ID=3], ... } be1: { image: apache/doris:2.0.3-be-x86_64, env: [FE_SERVERS="...", BE_ADDR="192.168.1.21:9050"], ... } be2: { image: ..., env: [BE_ADDR="192.168.1.22:9050"], ... } be3: { image: ..., env: [BE_ADDR="192.168.1.23:9050"], ... }启动
docker-compose up -d -
验证
mysql -h127.0.0.1 -P9030 -uroot mysql> SHOW PROC '/frontends'\G mysql> SHOW PROC '/backends'\G -- Alive=true 即 OK
4、部署目录对照表
| 宿主机路径 | 容器内路径 | 作用 |
|---|---|---|
/data/doris/fe/doris-meta |
/opt/apache-doris/fe/doris-meta |
FE 元数据 |
/data/doris/fe/log |
/opt/apache-doris/fe/log |
FE 日志 |
/data/doris/be/storage |
/opt/apache-doris/be/storage |
BE 数据 & 索引 |
/data/doris/be/log |
/opt/apache-doris/be/log |
BE 日志 |
5、备忘清单
- 镜像列表
apache/doris:2.0.3-fe-x86_64
apache/doris:2.0.3-be-x86_64 - 常用端口
8030(FE Web)、9030(MySQL 协议)、8040(BE Web) - 一键停止/清理
docker-compose down && docker volume prune
4、docker-compose部署
docker-compose生产可用:
https://www.cnblogs.com/jigaobo/articles/19004214
5、k8s部署
yaml文件部署
1、需要先部署CRD资源
kubectl create -f https://raw.githubusercontent.com/apache/doris-operator/master/config/crd/bases/doris.selectdb.com_dorisclusters.yaml
2、部署Doris服务(注意持久化数据目录)
kubectl apply -f https://raw.githubusercontent.com/apache/doris-operator/master/config/operator/operator.yaml
Helm 部署 Doris Operator
#在线添加仓库(通过 repo add 命令添加远程仓库)
helm repo add doris-repo https://charts.selectdb.com
#通过 repo update 命令更新最新版本的 chart
helm repo update doris-repo
#安装 Doris Operator
helm install operator doris-repo/doris-operator
#重点:使用配置文件自定义镜像版本号
helm install -f values.yaml operator doris-repo/doris-operator
kubectl get pod -A | grep doris
查看helm自定义模板配置
helm get values operator
helm get values operator -n default
更新helm实例版本
#修改镜像版本、然后执行更新命令
vim values.yaml
dorisOperator:
image:
repository: apache/doris
tag: operator-25.5.1 #修改镜像版本
imagePullSecret: ""
imagePullPolicy: "Always"
nodeSelector: {}
resources: {}
nodeAffinity: {}
enableAggregatedClusterRole: false
#新命令
helm upgrade operator doris-repo/doris-operator -f values.yaml
#指定helm版本
helm upgrade operator doris-repo/doris-operator --version 25.5.1 -f values.yaml
回滚
#查看历史版本:
helm history operator
helm rollback operator 1
#验证查看
helm get values operator
k8s中持久化部署(生产可用)
# 1. 命名空间
apiVersion: v1
kind: Namespace
metadata:
name: doris
---
# 2. PVC(FE & BE)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: doris-fe-pvc
namespace: doris
spec:
storageClassName: managed-nfs-storage
accessModes: [ReadWriteOnce]
resources:
requests:
storage: 50Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: doris-be-pvc
namespace: doris
spec:
storageClassName: managed-nfs-storage
accessModes: [ReadWriteOnce]
resources:
requests:
storage: 200Gi
---
# 3. Deployment(单机版,强制调度到 k8s-33)
apiVersion: apps/v1
kind: Deployment
metadata:
name: doris-single
namespace: doris
spec:
replicas: 1
selector:
matchLabels:
app: doris-single
template:
metadata:
labels:
app: doris-single
spec:
nodeName: k8s-33 # 固定节点
initContainers:
- name: init-sysctl
image: busybox
command: ["sysctl","-w","vm.max_map_count=2000000"]
securityContext:
privileged: true
containers:
# FE
- name: fe
image: apache/doris:2.0.3-fe-x86_64
ports:
- containerPort: 8030
- containerPort: 9030
env:
- name: FE_SERVERS
value: "fe1:127.0.0.1:9010"
- name: FE_ID
value: "1"
volumeMounts:
- name: fe-meta
mountPath: /opt/apache-doris/fe/doris-meta
- name: fe-log
mountPath: /opt/apache-doris/fe/log
# BE
- name: be
image: apache/doris:2.0.3-be-x86_64
ports:
- containerPort: 8040
- containerPort: 9050
env:
- name: FE_SERVERS
value: "fe1:127.0.0.1:9010"
- name: BE_ADDR
value: "127.0.0.1:9050"
volumeMounts:
- name: be-storage
mountPath: /opt/apache-doris/be/storage
- name: be-log
mountPath: /opt/apache-doris/be/log
volumes:
- name: fe-meta
persistentVolumeClaim:
claimName: doris-fe-pvc
- name: fe-log
emptyDir: {}
- name: be-storage
persistentVolumeClaim:
claimName: doris-be-pvc
- name: be-log
emptyDir: {}
---
# 4. Headless Service(集群内 Java 访问)
apiVersion: v1
kind: Service
metadata:
name: doris-single-headless
namespace: doris
spec:
clusterIP: None
ports:
- name: fe-mysql
port: 9030
targetPort: 9030
- name: be-heartbeat
port: 9050
targetPort: 9050
selector:
app: doris-single
---
# 5. NodePort Service(集群外访问)
apiVersion: v1
kind: Service
metadata:
name: doris-single-nodeport
namespace: doris
spec:
type: NodePort
ports:
- name: fe-http
port: 8030
targetPort: 8030
nodePort: 30030
- name: fe-mysql
port: 9030
targetPort: 9030
nodePort: 30031
selector:
app: doris-single
Doris相关问题 ?
Doris是什么同步机制 ?
1. 主动拉取模式(Doris从MySQL读取)
工作原理:
- Doris 主动 通过工具或定时任务从MySQL拉取数据(如通过Binlog、定时导出CSV等方式)。
- 典型工具:
- Broker Load:批量导入MySQL导出的文件(CSV/Parquet等)。
- Binlog Load:通过订阅MySQL的Binlog实现近实时同步(类似Canal/Flink CDC)。
- DataX/Flink:通过ETL工具定时抽取MySQL数据。
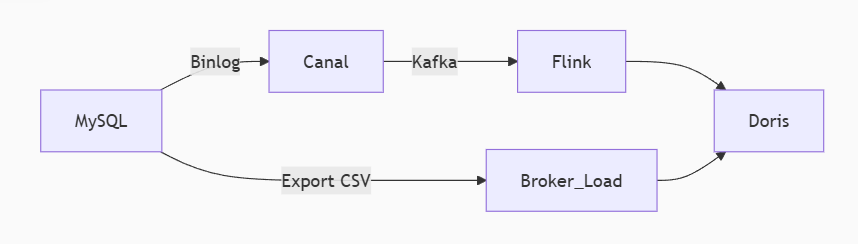
特点:
- ✅ 对业务代码无侵入,无需修改Java服务。
- ⚠️ 有同步延迟(取决于拉取频率)。
- 适用场景:
- 数据分析场景(允许分钟级延迟)。
- 历史数据迁移或T+1离线同步。
2. 双写模式(业务代码同步写)
工作原理:
- Java服务在写MySQL时同步/异步写入Doris(需改业务代码)。
- 实现方式:
- 同步双写:事务中同时写MySQL和Doris(强一致,但性能低)。
- 异步双写:写MySQL后发MQ(如Kafka),消费者写Doris(最终一致)。
// Java服务中
public void saveOrder(Order order) {
// 1. 写MySQL
mysqlMapper.insert(order);
// 2. 发Kafka事件(异步写Doris)
kafkaTemplate.send("doris-sync-topic", order);
}
// Kafka消费者侧
@KafkaListener(topics = "doris-sync-topic")
public void syncToDoris(Order order) {
dorisMapper.insert(order);
}
3. 混合模式(业务无关 + 主动拉取)
工作原理:
- 基础数据通过Binlog Load近实时同步到Doris。
- 业务自定义数据(如计算指标)通过双写或Spark/Flink加工后写入Doris。
特点:
- ✅ 平衡实时性与解耦。
- ⚠️ 架构复杂度较高。
- 适用场景:
- 既有实时报表需求,又需复杂ETL计算的场景。
4、为什么需要实时数据捕获?
Doris 只是一个数据仓库,他提供的功能是实时数据统计、查询和存储,他不支持主动实时抓取数据,需要借助第三方工具来进行实现,比如我们在 MySQL修改了一条数据,怎么让 Doris 进行更新?目前想到的答案是主动发送更新数据至Kafka,然后Doris订阅 KafKa 的 Topic 然后进行实时同步,虽然以上能实现我们想要的功能,但是有点复杂,业务每次操作都要发送 Kafka,同时要想对数据进行加工,工作量相对较大,正因为有以上问题,所以我们采用Flink CDC
业务如何使用Doris
注意:(没有最好的技术、只有最适配的)要根据业务选择合适的方案、不要浪费资源、合理按照公司业务分配。
1、MySQL和Doris的同步方案:
我的数据库有1个亿数据、使用doris融入到我的业务、我每个月的数据是5000万、超过两个月的数据就归档到Doris 客户查询接口、查MySQL超过两个月的数据就走路由判断、到doris里面查询
业务:1亿数据
运维工作:归档到Doris、使用MySQL备份的方式。(shell脚本+mysqldump备份+同步推送到OSS、再归档到Doris)
开发工作:超过两个月的数据、业务上查询的SQL走Doris ?(ODBC、JDBC连接工具)
1、查询速度
1亿行级别、带聚合或范围过滤的复杂查询,Doris(列式、MPP、分布式)通常比 MySQL 快 4~30 倍
简单点查(主键/索引回表)MySQL 更快,但既然你已经把“超过 2 个月”的数据放到 Doris,就默认走的是复杂查询场景,Doris 优势明显
2、数据量与生命周期
每月 5000 万,2 个月≈1 亿,Doris 单机都能轻松撑住,分布式集群就更不是问题
Doris 支持分区(按日期一级分区,再按业务键二级分桶),两个月后的分区直接 ALTER TABLE DROP PARTITION 即可物理删除,归档到对象存储也支持。
3、业务侧如何路由(开发需要修改代码、让超过两个月的数据查询走Doris)
if (查询月份 >= 当月-2) {
走 MySQL
} else {
走 Doris(通过 MySQL 协议,JDBC 连过去,SQL 几乎不改)
}
4、如何将MySQL数据同步到Doris(链路跑通后日常运维成本极低)
首次全量:DataX / mysqldump → Broker Load
实时增量:Flink CDC → Kafka → Doris Stream Load(Exactly-Once)
5、需要关注的小坑
Doris 目前主键更新/删除是 Merge-on-Write,频繁小更新场景需控制批次大小。
如果客户偶尔会查“两年前的单通电话”,建议在 Doris 里建 Bitmap / BloomFilter 索引,毫秒级点查也能满足。
提前做容量规划:5000 万行 * N 个月 * 字段宽度 ≈ 裸数据量,再按 3 副本(默认)估算磁盘。
结论:把热数据留在 MySQL、冷数据进 Doris,接口层按时间自动路由,是目前最经济且性能最优的冷热分层方案之一,可以在生产环境落地。
2、MySQL和Doris数据量对比 :
MySQL大概500G 三个月的数据 Doris要存6个月 大概多少G ?
- 先算 MySQL 裸数据量
你现在 3 个月 500 GB,平均每月 500/3 ≈ 167 GB。 - Doris 6 个月裸数据量
167 GB × 6 ≈ 1 000 GB(1 TB)——这是未压缩、未副本的“逻辑数据量”。 - 加压缩 + 副本系数
• Doris 默认 LZ4 压缩,典型压缩比 3 : 1~5 : 1,取 4 : 1 ⇒ 1 TB / 4 ≈ 250 GB(单副本)。
• 默认 3 副本 ⇒ 250 GB × 3 ≈ 750 GB 磁盘占用。
因此,6 个月数据在 Doris 集群里大约需要 700~800 GB 物理磁盘(含 3 副本、已压缩)。
如果后续开启冷热分层(热 SSD、冷 HDD 或对象存储),热数据部分可再省一半以上。
3、单机方式使用Doris
重点: 把热数据留在 MySQL、冷数据进 Doris
业务场景是单机部署 Doris,且数据是通过脚本从MySQL导出后批量导入 Doris(而不是实时同步),这种场景可以更简化部署和成本:
单机部署 Doris 是完全可行的,尤其是当数据量和查询负载不是特别大时。单机部署可以大大简化运维复杂度。
硬件配置建议:
CPU:16 核(或更高,取决于查询复杂度和并发量)。
内存:64 GB(最低建议,如果查询复杂,可以考虑 128 GB)。
磁盘:2 TB SSD盘(阿里云盘、前期可以少买点、后期动态扩容)
网络:千兆网卡即可
4、集群方式Doris
实时同步的方式:
一、 结论
数据量:6 个月≈1 TB 裸数据,压缩+3 副本后磁盘≈750 GB。
查询并发:假设日常峰值 50 QPS、单次扫描 1000 万行以内,3 台 BE 16C/64G/2 TB SSD 就能稳稳兜住。
高可用:FE 至少 3 节点(1 Leader + 2 Follower),可与 BE 混布或独立部署。
网络:万兆网卡,否则容易在 Shuffle 阶段打满千兆。
二、推荐部署拓扑(最小生产规模)
| 角色 | 节点数 | 实例配置(每台) | 备注 |
|---|---|---|---|
| FE(Follower) | 3 | 16C 64G 100 GB SSD | 元数据高可用,可混布在 BE 节点 |
| BE | 3 | 16C 64G 2 TB NVMe SSD | 真正存储+计算,3 副本 |
| Broker(可选) | 0~1 | 与 FE/BE 复用 | 仅当需要 HDFS/S3 备份时启用 |
总物理机数:最少 3 台即可;若 FE 独立部署再加 2 台,共 5 台。
每台 BE 挂 1~2 块 SSD,磁盘 75 % 使用率警戒线时≈1.5 TB 有效空间,可存 6 个月数据。 (按照自己公司数据量评估)
三、CPU / 内存配比官方公式
官方建议:BE 内存 ≥ CPU 核数 × 4,最好 × 8 。
16 核 × 4 = 64 GB,正好符合上表;如果预算充足,上到 128 GB 可让聚合/排序更从容。
四、Doris 版本与系统前置
CentOS 7.9 / Ubuntu 20.04,JDK 1.8+,关闭 swap,文件句柄 65536+,时钟同步 chrony。
CPU 必须支持 AVX2(grep avx2 /proc/cpuinfo 有输出),否则用 no-avx2 构建包 。
五、扩展策略
数据量再翻倍:水平加 BE 即可,磁盘线性扩容。
查询并发突然增大:给 FE 增加 Observer 节点(无状态,秒级扩展)。
冷热再次分层:Doris里面只保留6个月的数据、超过六个月的历史数据归档压缩后导出到OSS存储。
5、MySQL数据导出:
学习文档:https://www.cnblogs.com/hahaha111122222/p/17480284.html
注意: 有些方式需要数据库中配置的允许导出文件保存的路径
#方式一:原始MySQL备份方式导出数据
mysqldump -u username -p --databases prod-database-a -tables table-a --where="begin_time >= '2024-06-01' AND begin_time < '2024-07-01'" --fields-terminated-by=',' --lines-terminated-by='\n' > data06.csv
#方式二:比mysqldump更快,因为是直接由MySQL服务器写入文件、需要FILE权限和服务器文件系统访问权限
SELECT * FROM table-a
WHERE begin_time >= '2024-06-01' AND begin_time < '2024-07-01'
INTO OUTFILE '/tmp/data06.csv'
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
#方式三:mydumper工具、并行导出工具,比mysqldump快很多
安装后使用:mydumper -u username -p password -B prod-database-a -T table-a -o /output/dir
#方式四:使用CSV存储引擎(-- 然后直接复制表文件)
ALTER TABLE table-a ENGINE=CSV;
然后去数据目录找出文件、直接导入到Doris
#方式五:根据插件方式同步
https://blog.csdn.net/luostudent/article/details/132662532
6、数据导入到doris:
Doris 提供了多种导入方式,推荐使用 Broker Load 或 Stream Load:
-
Broker Load:适合批量导入,支持从本地文件系统或 HDFS 导入。
#方式一: LOAD LABEL your_label ( DATA INFILE("file:///path/to/data.csv") INTO TABLE your_table COLUMNS TERMINATED BY ',' (col1, col2, col3) ); #方式二: -- 如果是CSV文件 LOAD LABEL db_name.label_202406 ( DATA INFILE("hdfs://path/to/table_a_202406.csv") INTO TABLE doris_table COLUMNS TERMINATED BY "," FORMAT AS "csv" (col1, col2, col3) ) WITH BROKER "broker_name" PROPERTIES ( "timeout" = "7200", "max_filter_ratio" = "0.1" ); -
Stream Load:适合实时或小批量导入,可以通过 HTTP API 接口直接推送数据。
#方式二: curl --location-trusted -u username:password -T data.csv http://doris-fe:8030/api/your_database/your_table/_stream_load使用mydumper工具导出后需要注意:
#由于 mydumper 输出的是 SQL 文件,直接导入 Doris 需额外处理: #mydumper导出命令: mydumper -u username -p password -B prod-database-a -T table-a -o /output/dir #导出内容: ls /output/dir/ prod-database-a.table-a.00000.sql prod-database-a.table-a.00001.sql #转换格式: # 提取 INSERT 语句中的数据部分(需根据实际格式调整) sed -e 's/INSERT INTO `.*` VALUES //g' -e 's/;//g' prod-database-a.table-a.*.sql > data.csv #再使用 Doris Stream Load: curl -T data.csv -u user:pass http://doris-fe:8030/api/db/table/_stream_load \ -H "column_separator:," -H "format:csv"
7、Doris 配置建议
- FE 和 BE 同机部署:在单机部署中,FE 和 BE 可以部署在同一台机器上,简化部署。
- 关闭不必要的服务:例如 Broker,如果不需要从 HDFS/S3 导入数据,可以不启用。
- 内存和 CPU 配置:
- BE 内存:建议分配 50% 的系统内存给 BE(例如 64 GB 系统内存,分配 32 GB 给 BE)。
- FE 内存:默认配置即可,占用内存较少。
8、优化
分区表设计:按时间分区(例如按月分区),方便管理和查询优化。
CREATE TABLE your_table
(
col1 INT,
col2 STRING,
date_column DATE
)
PARTITION BY RANGE(date_column)
(
PARTITION p202506 VALUES LESS THAN ('2025-07-01'),
PARTITION p202507 VALUES LESS THAN ('2025-08-01'),
...
);
- 索引优化:根据查询需求创建合适的索引(例如 Bitmap 索引、Bloom Filter 索引)。
ALTER TABLE your_table ADD INDEX idx_col1 ON (col1) USING BITMAP;
数据生命周期管理
-
定期清理:超过 6 个月的数据可以定期清理或归档到其他存储。
ALTER TABLE your_table DROP PARTITION p202505;
9、监控与备份
- 监控:使用 Prometheus + Grafana 监控 Doris 的性能指标。
- 备份:定期备份数据,可以通过
mysqldump备份元数据,通过hadoop fs -cp备份存储数据。
Doris处理数据脚本
分区并行导出导入
这个需要部署 Stream Load
# MySQL侧:按时间分片导出(例如按天)
for day in {01..30}; do
mysql -uuser -p -e "
SELECT * FROM table_a
WHERE begin_time LIKE '2024-06-${day}%'
INTO OUTFILE '/data/mysql_export/table_a_202406${day}.csv'
FIELDS TERMINATED BY ',';
"
done
# Doris侧:并行提交多个LOAD任务
for file in /data/doris_import/table_a_202406*.csv; do
cat <<EOF | mysql -h doris_fe -P 9030 -uuser -ppass
LOAD LABEL db_name.label_202406
(DATA INFILE("file://${file}") INTO TABLE doris_table)
WITH BROKER "broker_name";
EOF
done
如果你只在本机(单机 Doris,没有 S3),就不要用 BROKER 方式,直接用 Stream Load 即可:
curl --location-trusted -u root: \
-T /绝对路径/table_a_202406.csv.gz \
-H "compress_type:GZ" \
-H "column_separator:," \
-H "columns:col1,col2,col3,..." \
http://127.0.0.1:8030/api/db_name/doris_table/_stream_load
1、-T 后面是本机文件路径,不要写 file://,直接 /path/xxx.csv.gz。
2、compress_type:GZ 告诉 Doris 自动解压。
3、columns 按导出顺序写,对应 Doris 表字段。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号