
MHA实现数据库的高可用
MHA实现数据库的高可用
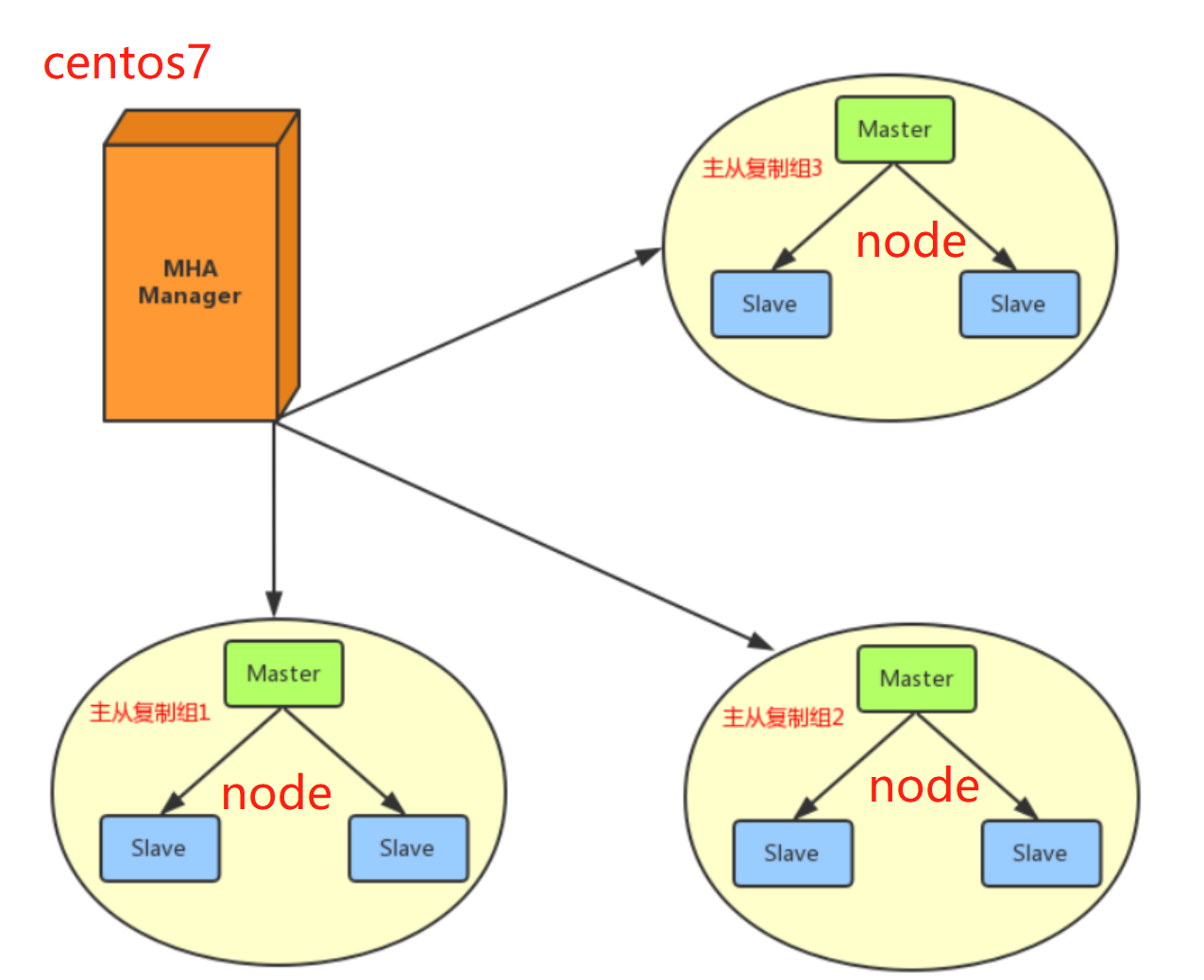
1、MHA是一个基于触发器、复制和VIP(虚拟IP)的高可用解决方案
2、主从复制
MySQL的MHA基于MySQL的主从复制机制。在MySQL中,主节点(Master)将数据库的写操作同步到备用节点(Slave),备用节点则可以提供只读操作的服务,从而确保了数据库的高可用性。MHA将利用主从复制机制进行数据同步和故障转移。
3、触发器
MHA会在监控到主节点失效时,通过触发器快速启动切换操作。触发器会检测主节点的状态信息来判断主节点是否故障,如果监控数据出现故障,则触发器会自动启动故障转移操作。
4、VIP(虚拟IP)
为了实现透明的故障转移,MHA使用了VIP(虚拟IP)功能,将多个节点组成一个集群,并将VIP绑定到主节点。应用程序只需要连接VIP,而无需关心实际运行的数据库节点。当发生故障转移时,MHA会自动将VIP移动到新的主节点。
5、操作原子性
MHA操作具有原子性,以确保故障转移时数据的一致性。例如,当主节点故障转移时,MHA会先将备份节点恢复到与主节点同步的最新状态,然后将VIP绑定到新的主节点,并更新应用程序的配置,以确保数据的一致性。
注意:只是一个高可用的解决方案、不能保证数据一点不丢失(配置一台半同步保证数据完整性)
数据库集群中主节点出了故障会自动提升一个从节点为新主
可以设置权重(优先当主节点的)
日志落后100M要加check_repl_delay=0 日志内容落后再多也可以当主节点
MHA的vip转移功能是一次性的
MHA原理
主节点加多个从节点
1、MHA不断的发送信息SELECT 1 As Value指令判断master服务器的健康性、(查看日志信息)
2、一旦master挂机、从挂机崩溃的master保存二进制日志事件(binlog events)
3、前提MHA和master之间的网络是正常的(ssh服务和网络是通的)(单纯得服务挂了)
4、识别从节点的日志(那一台是最最新最全的)
5、应用差异的中继日志到其他的slave(把数据多的从节点的差异数据复制到其他从节点)
6、应用从master保存的二进制日志事件(binlog events) 到所有的slave节点
7、提升一个slave为新的master
部署要求:
1、管理节点(只支持centos7)
2、node节点(centos7、8 ubuntu、都支持、都可以)
3、管理机器安装两个包manager和node包
4、所有节点必须打通ssh key验证
5、管理节点建立配置文件
6、脚本(发邮件告警脚本)(VIP的切换)
打通ssh key验证
ssh-keygen
ssh-copy-id 127.0.0.1
ls .ssh
rsync -av .ssh 10.0.0.8:/root/
rsync -av .ssh 10.0.0.9:/root/
注意:
重点:具体实现详细过程
1、所有节点统一创建账号、修改权限、连接数据库、同步日志(发送select 1 测试)
2、从节点read-only关闭(可能会被提升成新主)
3、ssh方法连接
4、主从复制账号
5、探测健康检查ping_interval=1
6 vip漂移脚本
7、发邮件脚本(故障邮件报警)
8、指定二进制日志的位置
在 mha-manager 节点创建相关配置文件
mkdir /etc/mastermha
vim /etc/mastermha/app1.cnf
[server default]
user=mhauser #mha-manager节点连接远程mysql使用的账户,需要有管理员的权限
password=123456 #mha-manager节点连接远程mysql使用的账户密码
manager_workdir=/data/mastermha/app1/ #mha-manager对于当前集群的工作目录
manager_log=/data/mastermha/app1/manager.log #mha-manager对于当前集群的日志
remote_workdir=/data/mastermha/app1/ #mysql 节点mha 工作目录,会自动创建
ssh_user=root #各节点间的SSH连接账号,提前做好基于key 的登录验证,用于访问二进制日志
repl_user=repluser #mysql节点主从复制用户名
repl_password=123456 #mysql节点主从复制密码
ping_interval=1 #mha-manager节点对于master节点的心跳检测时间间隔
master_ip_failover_script=/usr/local/bin/master_ip_failover
#切换VIP的perl脚本,不支持跨网络,也可用Keepalived实现
report_script=/usr/local/bin/sendmail.sh #发送告警信息脚本
check_repl_delay=0 #默认值为1,表示如果 slave 中从库落后主库 relay log 超过 100M,主库不会选择这个从库为新的 master,因为这个从库进行恢复需要很长的时间.通过设置参数 check_repl_delay=0,mha 触发主从切换时会忽略复制的延时,对于设置candidate_master=1 的从库非常有用,这样确保这个从库一定能成为最新的 master
master_binlog_dir=/data/mysql/logbin/
#指定二进制日志存放的目录,mha4mysqlmanager-0.58必须指定,之前版本不需要指定
[server1]
hostname=10.0.0.8
candidate_master=1 #优先候选master,即使不是集群中事件最新的slave,也会优先当master
[server2]
hostname=10.0.0.9
candidate_master=1 #优先候选master,即使不是集群中事件最新的slave,也会优先当master
[server3]
hostname=10.0.0.10
邮箱配置脚本
vim /usr/local/bin/sendmail.sh
#!/bin/bash
echo 'MHA is failover!' | mail -s 'MHA Warning' jigaobo@163.com
脚本配置
触发器、实现VIP漂移脚本
1、virtually IP,此IP会 在不同的MySQL节点漂移
添加虚拟ip
ifconfig ens160:1 10.0.0.100/24
2、在网卡上添加IP,确保每 台 MySQL 节点网卡名一样
#!/usr/bin/env perl
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
my (
$command, $ssh_user, $orig_master_host,
$orig_master_ip, $orig_master_port, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password
);
my $vip = '10.0.0.100/24';
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
);
exit &main();
sub main {
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
# updating global catalog, etc
$exit_code = 0;
};
99 lines yanked
主从配置
搭建主从
1、serverid唯一
2、指定mysql二进制日志的位置 (创建文件夹、修改属性)
3、搭建主从关系
4、授权all权限
先记录二进制·日志位置
create user jigaobo@'10.0.0.%' identified by '123456'
grant replication slave on *.* to jigaobo@'10.0.0.%';
如果主从出错:
1、停止线程 stop slave;
2、先清空主从规则 reset slave all;
3、再重新配置主从关系
检查MHA的环境
#检查环境
masterha_check_ssh --conf=/etc/mastermha/app1.cnf #检查MHA
masterha_check_repl --conf=/etc/mastermha/app1.cnf #检查主从复制
#查看状态
masterha_check_status --conf=/etc/mastermha/app1.cnf
#后台执行
nohup masterha_check_ssh --conf=/etc/mastermha/app1.cnf &> /dev/null
#后台执行(删除配置文件)
nohup masterha_manager --conf=/etc/mastermha/app1.cnf --remove_dead_master_conf --ignore_last_failover &> /dev/null
#测试启动
masterha_manager --conf=/etc/mastermha/app1.cnf --remove_dead_master_conf --ignore_last_failover
查看主节点状态
#开启通用日志
set global general_log=1;
#查看日志
tail -f /var/lib/mysql/master.log
详细执行过程
#安装数据库(一主多从)
tail -n 100 /var/log/mysqld.log | grep password #MySQL安装好之后查看密码
alter user root@'localhost' identified by 'AAbb-123.'; #修改数据库密码
1、下载包
#管理包
wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
#节点包
wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm
mkdir /etc/mastermha
mkdir /etc/mastermha
vim /etc/mastermha/app1.cnf
[server default]
user=mhauser
password="!!AAbb123"
manager_workdir=/data/mastermha/app1/
manager_log=/data/mastermha/app1/manager.log
remote_workdir=/data/mastermha/app1/
ssh_user=root
repl_user=repluser
repl_password="!!AAbb123"
ping_interval=1
master_ip_failover_script=/usr/local/bin/master_ip_failover
report_script=/usr/local/bin/sendmail.sh
check_repl_delay=0
master_binlog_dir=/data/mysql/logbin/
[server1]
hostname=10.0.0.8
candidate_master=1
[server2]
hostname=10.0.0.9
candidate_master=1
[server3]
hostname=10.0.0.10
二进制日志(根据MHA配置路径)
mkdir /data/mysql/logbin/ -p
chown -R mysql.mysql /data/mysql/logbin/
vim /etc/my.cnf
[mysqld]
server_id=9
log-bin=/data/mysql/logbin/mysql-bin
systemctl restart mysqld
#注意:
#mv移动目录脚本到位置/usr/local/bin/master_ip_failover
MySQL主节点添加虚拟ip
ifconfig ens160:1 10.0.0.100/24
记录二进制日志位置
flush binary logs; #刷新二进制日志位置
show master status; #查看位置
主从授权
主节点
create user repluser@'10.0.0.%' identified by '!!AAbb123'; #创建
grant replication slave on *.* to repluser@'10.0.0.%'; #授权
FLUSH PRIVILEGES; #刷新权限(不刷新后面可能会遇到问题)
从节点
CHANGE MASTER TO
MASTER_HOST='10.0.0.8',
MASTER_USER='repluser',
MASTER_PASSWORD='!!AAbb123',
MASTER_PORT=3306,
MASTER_LOG_FILE='mysql-bin.000008',
MASTER_LOG_POS=157,
MASTER_CONNECT_RETRY=2;
创建MHA授权账号
create user mhauser@'10.0.0.%' identified by '!!AAbb123';
grant all on *.* to mhauser@'10.0.0.%';
检查环境
检查ssh连接验证是正常
masterha_check_ssh --conf=/etc/mastermha/app1.cnf
检查主从复制是否正常
masterha_check_repl --conf=/etc/mastermha/app1.cnf
下面开始启动服务
masterha_check_status --conf=/etc/mastermha/app1.cnf #提前查看MHA状态
cat /data/mastermha/app1/manager.log #查看日志(启动后会自动创建)
nohup masterha_manager --conf=/etc/mastermha/app1.cnf --remove_dead_master_conf --ignore_last_failover &> /dev/null #启动(生产环境后台执行)
masterha_stop --conf=/etc/mastermha/app1.cnf #如果想停止后台的 manager, 使用此命令
masterha_manager --conf=/etc/mastermha/app1.cnf --remove_dead_master_conf --ignore_last_failover #启动(前台执行、测试环境)
查看日志状态()
tail -f /data/mastermha/app1/manager.log
注意:一直发送(SELECT 1) 检测主节点状态
主节点开启通用日志
SHOW VARIABLES LIKE 'general_log'; #查看
set global general_log=1; #开启
每秒发送(SELECT 1)检测主节点状态
tail -f /var/lib/mysql/master.log
注意:在从节点开启是没有(SELECT 1)探测指令
注意:后续把应用服务指定数据库ip 10.0.0.10
模拟演练:
注意;断电不行(前提MHA和master之间的网络是正常的)
systemctl stop mysqld.service
注意:MHA只能使用一次、VIP的漂移
当 master 节点出现宕机,mha-manager 节点上的 masterha_manager 程序会退出
经过手动处理,原来的 master 节点上线后,应该将该节点设置成 slave 节点,让其从新的 master 节点处同步数据
对于前端用户来讲,此过程是无感知的,因为前端用户是通过连接VIP来操作数据库的,而VIP一直可用,只是转移到另一台机器而己
MHA 只能解决一次 master 节点故障,VIP 只能漂移一次, 再次启动之前需要删除相关文件,否则无法工作
后续如果再次恢复MHA
[root@mha-manager ~]# cat /etc/mastermha/app1.cnf
....
manager_workdir=/data/mastermha/app1/
manager_log=/data/mastermha/app1/manager.log
remote_workdir=/data/mastermha/app1/
#MHA 再次使用之前,需要先删除 manager_workdir 指向的目录和 remote_workdir 指向的目录
#manager_workdir 指向的目录在 mha-manager 节点上
#remote_workdir 指向的目录在 mysql 节点上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号