极简transformer,仅供理解原理
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class PositionalEncoding(nn.Module):
"""位置编码:为输入序列添加位置信息"""
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
(-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置用sin
pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置用cos
pe = pe.unsqueeze(0) # [1, max_len, d_model]
self.register_buffer('pe', pe) # 不参与训练
def forward(self, x):
# x: [batch_size, seq_len, d_model]
return x + self.pe[:, :x.size(1)]
class MultiHeadAttention(nn.Module):
"""多头注意力机制"""
def __init__(self, d_model, num_heads, dropout=0.1):
super().__init__()
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 每个头的维度
# 线性变换层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# Q, K, V: [batch_size, num_heads, seq_len, d_k]
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
attn_probs = F.softmax(attn_scores, dim=-1)
attn_probs = self.dropout(attn_probs)
output = torch.matmul(attn_probs, V)
return output, attn_probs
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# 1. 线性变换并分头
Q = self.W_q(Q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(K).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(V).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 2. 缩放点积注意力
attn_output, attn_probs = self.scaled_dot_product_attention(Q, K, V, mask)
# 3. 合并多头
attn_output = attn_output.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model)
# 4. 最终线性变换
output = self.W_o(attn_output)
return output, attn_probs
class FeedForward(nn.Module):
"""前馈神经网络(每个位置独立处理)"""
def __init__(self, d_model, d_ff=2048, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear2(self.dropout(F.relu(self.linear1(x))))
class EncoderLayer(nn.Module):
"""单个编码器层"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# 1. 多头自注意力 + 残差连接 + 层归一化
attn_output, _ = self.self_attn(x, x, x, mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
# 2. 前馈网络 + 残差连接 + 层归一化
ffn_output = self.ffn(x)
x = x + self.dropout(ffn_output)
x = self.norm2(x)
return x
class DecoderLayer(nn.Module):
"""单个解码器层"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
# 1. 掩码多头自注意力
attn_output, _ = self.self_attn(x, x, x, tgt_mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
# 2. 交叉注意力
attn_output, _ = self.cross_attn(x, encoder_output, encoder_output, src_mask)
x = x + self.dropout(attn_output)
x = self.norm2(x)
# 3. 前馈网络
ffn_output = self.ffn(x)
x = x + self.dropout(ffn_output)
x = self.norm3(x)
return x
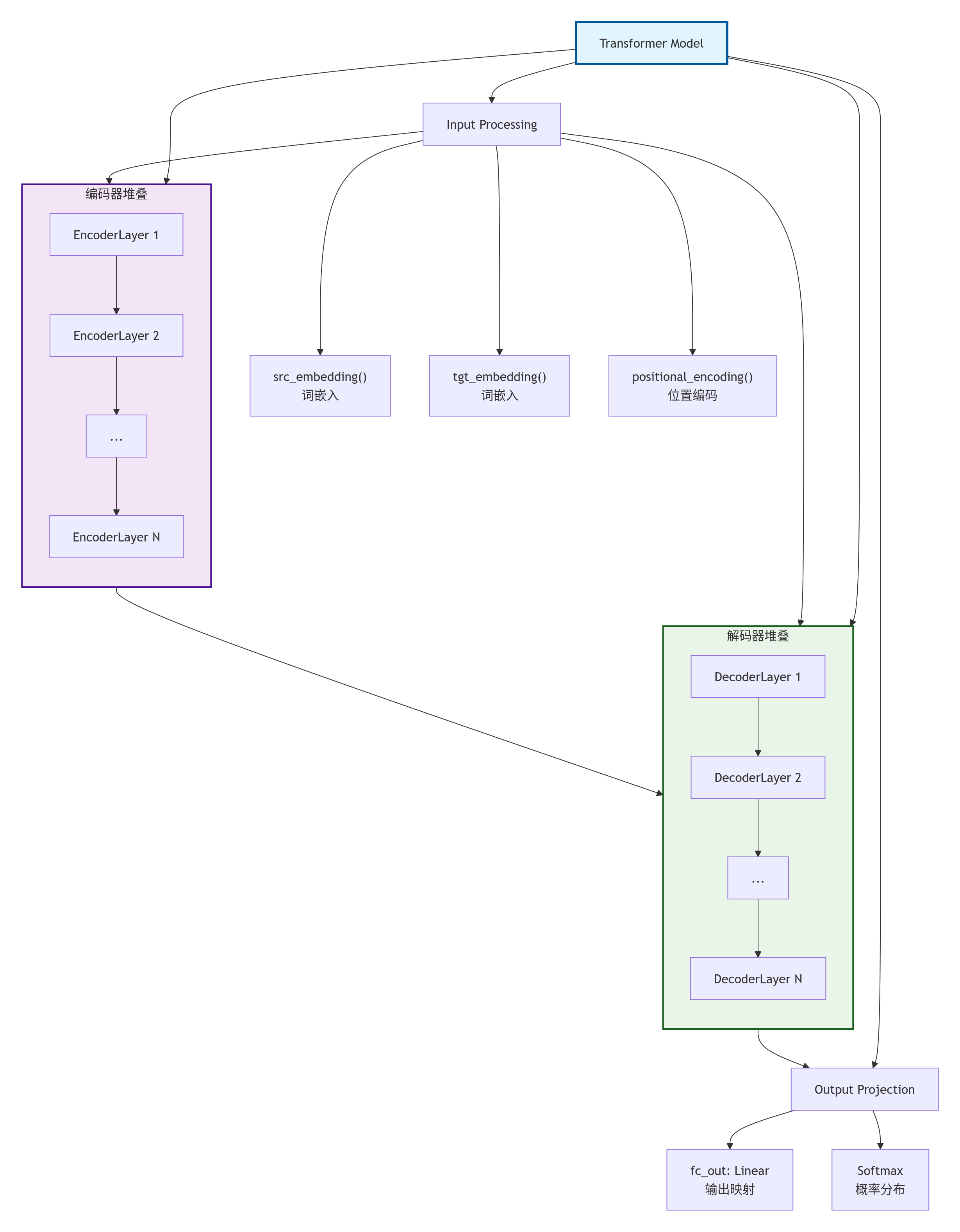
class Transformer(nn.Module):
"""完整的 Transformer 模型"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, num_heads=8,
num_layers=6, d_ff=2048, max_seq_len=100, dropout=0.1):
super().__init__()
# 词嵌入
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
# 位置编码
self.positional_encoding = PositionalEncoding(d_model, max_seq_len)
# 编码器堆叠
self.encoder_layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
# 解码器堆叠
self.decoder_layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
# 输出层
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
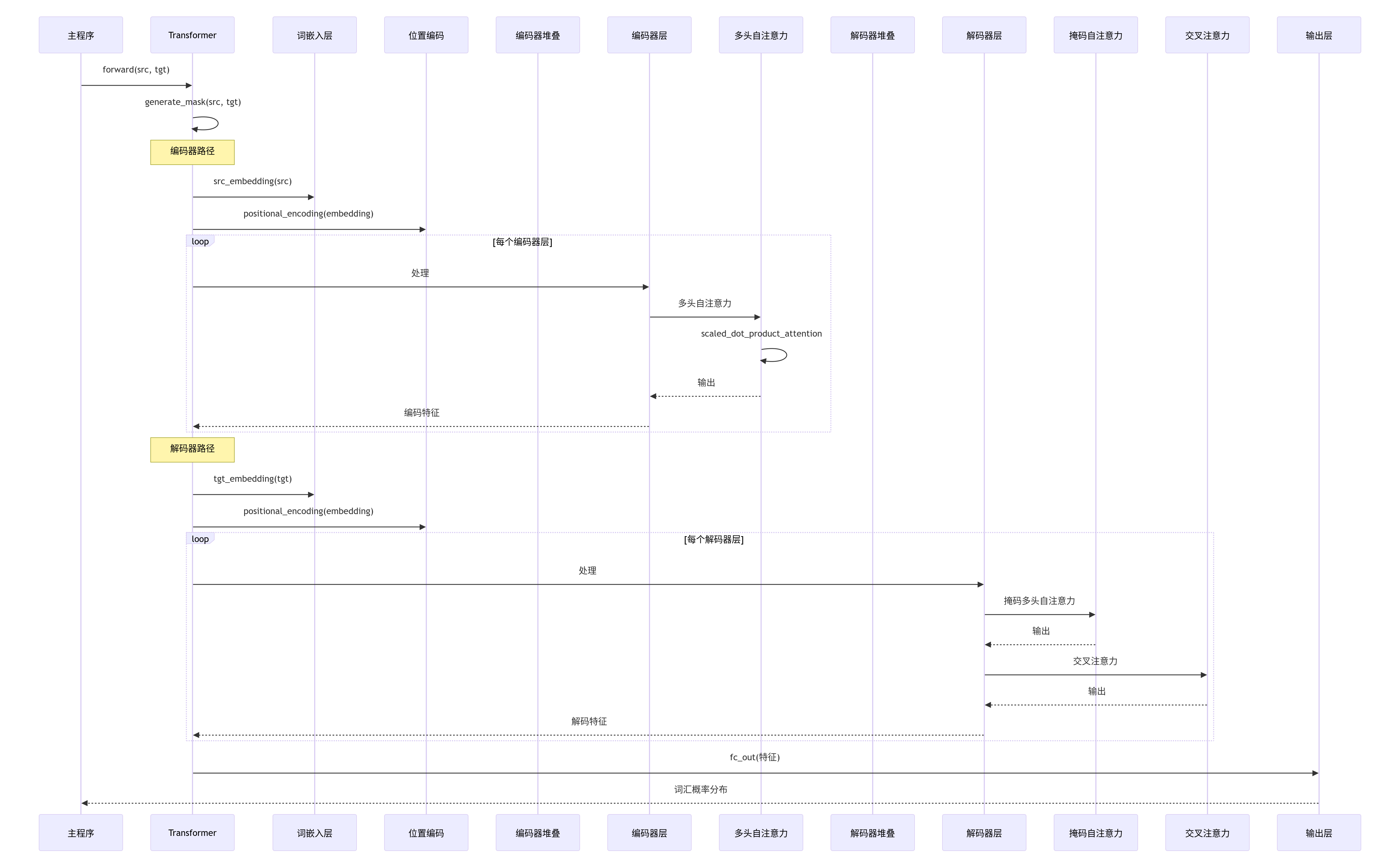
def generate_mask(self, src, tgt):
"""生成源掩码和目标掩码"""
# 源序列掩码(填充部分)
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
# 目标序列掩码(防止看到未来信息 + 填充部分)
tgt_pad_mask = (tgt != 0).unsqueeze(1).unsqueeze(2)
tgt_len = tgt.size(1)
tgt_sub_mask = torch.tril(torch.ones(tgt_len, tgt_len)).type(torch.bool)
tgt_mask = tgt_pad_mask & tgt_sub_mask
return src_mask, tgt_mask
def encode(self, src, src_mask):
"""编码器前向传播"""
x = self.src_embedding(src)
x = self.positional_encoding(x)
x = self.dropout(x)
for layer in self.encoder_layers:
x = layer(x, src_mask)
return x
def decode(self, tgt, encoder_output, src_mask, tgt_mask):
"""解码器前向传播"""
x = self.tgt_embedding(tgt)
x = self.positional_encoding(x)
x = self.dropout(x)
for layer in self.decoder_layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return x
def forward(self, src, tgt):
# 生成掩码
src_mask, tgt_mask = self.generate_mask(src, tgt[:, :-1])
# 编码器
encoder_output = self.encode(src, src_mask)
# 解码器(输入偏移一位)
decoder_output = self.decode(tgt[:, :-1], encoder_output, src_mask, tgt_mask)
# 输出投影
output = self.fc_out(decoder_output)
return output
def test_transformer():
"""测试函数"""
# 超参数
src_vocab_size = 100
tgt_vocab_size = 100
batch_size = 4
src_len = 10
tgt_len = 10
# 创建模型
model = Transformer(
src_vocab_size=src_vocab_size,
tgt_vocab_size=tgt_vocab_size,
d_model=128, # 减小维度以便快速测试
num_heads=4,
num_layers=2,
d_ff=512,
max_seq_len=20
)
# 创建随机输入
src = torch.randint(1, src_vocab_size, (batch_size, src_len))
tgt = torch.randint(1, tgt_vocab_size, (batch_size, tgt_len))
# 前向传播
output = model(src, tgt)
print("模型结构测试通过!")
print(f"输入源序列形状: {src.shape}")
print(f"输入目标序列形状: {tgt.shape}")
print(f"输出形状: {output.shape}") # 应该是 [batch_size, tgt_len-1, tgt_vocab_size]
print(f"参数数量: {sum(p.numel() for p in model.parameters()):,}")
return model, output
def generate_square_subsequent_mask(sz):
"""生成后续掩码(用于推理时)"""
mask = torch.triu(torch.ones(sz, sz) * float('-inf'), diagonal=1)
return mask
def greedy_decode(model, src, max_len, start_token, end_token, device):
"""贪心解码(简化推理过程)"""
model.eval()
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
with torch.no_grad():
# 编码
memory = model.encode(src, src_mask)
# 初始化目标序列
ys = torch.ones(1, 1).fill_(start_token).type(torch.long).to(device)
for i in range(max_len-1):
# 生成目标掩码
tgt_mask = generate_square_subsequent_mask(ys.size(1)).to(device)
# 解码
out = model.decode(ys, memory, src_mask, tgt_mask)
prob = model.fc_out(out[:, -1])
next_word = prob.argmax(dim=-1, keepdim=True)
ys = torch.cat([ys, next_word], dim=1)
if next_word.item() == end_token:
break
return ys
# 运行测试
if __name__ == "__main__":
# 1. 测试模型
model, output = test_transformer()
# 2. 查看注意力权重示例
print("\n=== 注意力机制测试 ===")
# 创建一个小型多头注意力
d_model = 64
num_heads = 4
attn = MultiHeadAttention(d_model, num_heads)
# 测试输入
batch_size = 2
seq_len = 5
Q = torch.randn(batch_size, seq_len, d_model)
K = torch.randn(batch_size, seq_len, d_model)
V = torch.randn(batch_size, seq_len, d_model)
# 前向传播
output, attn_weights = attn(Q, K, V)
print(f"注意力输出形状: {output.shape}")
print(f"注意力权重形状: {attn_weights.shape}")
print(f"注意力权重(第一个头,第一个批次):")
print(attn_weights[0, 0].detach().numpy().round(3))
# 3. 位置编码可视化
print("\n=== 位置编码示例 ===")
pe = PositionalEncoding(d_model=16, max_len=20)
sample_input = torch.zeros(1, 10, 16)
encoded = pe(sample_input)
print(f"位置编码后形状: {encoded.shape}")
print("前5个位置的前4个维度的正弦值:",
encoded[0, :5, :4].detach().numpy())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号