
SkipList跳表
1.1概述
最近看了一种数据结构叫做skipList,redis的zset用了它。Skip List是在有序链表的基础上进行了扩展,解决了有序链表结构查找特定值困难的问题,查找特定值的时间复杂度为O(logn),他是一种可以代替平衡树的数据结构。相对于红黑树等结构而言,实现也比较简单。
1.2详解
让我们回忆一下链表的确定,如果在一个有序链表进行插入和查询操作,我们需要从头遍历到尾。也就是o(n)的时间复杂度,那么我们有没有办法进行优化呢?比如在遍历过程中智能的跳过一些节点,快速的找到目标节点。这就引入了我们今天的主题--跳表了:
假如我们有这样一个有序链表

那么查询和插入(修改,删除)元素都只能在o(n)的时间复杂度中进行。但是如果我们在这上面再加一层用于定位的链表呢?
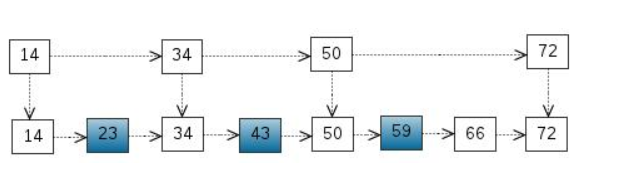
这个时候我们查询59号时,原先只能从头遍历到59,指针移动6次。但是加入一层用于定位的链表后,只需要14->34->50->50->59五次就可以了。这里只是数据量小,所以效果不明显。很显然,我们还可以再加一层:
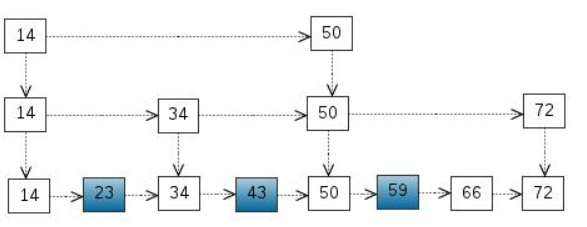
有没有感觉很像一棵树呢?这个时候进行的crud操作时间复杂度最好的情况下为o(logn)。当然这里和我们的每层设计相关。
这里的跳表具有以下几种性质。
- 由很多层结构组成
- 每一层都是一个有序的链表
- 最底层(Level 1)的链表包含所有元素
- 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
- 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
1.3代码实现
下面代码是网上最多的java实现版本。需要自己理解一下。
package skiplist;
import java.util.Random;
/**
* JavaTest
*
* @author : xgj
* @description : 跳表
* @date : 2020-08-06 09:41
**/
public class SkipList {
private static final int MAX_LEVEL = 16;
private int levelCount = 1;
private Node head = new Node();
private Random random = new Random();
public Node find(int value) {
//最后遍历出结果时,p其实指向的时所求节点的前一个节点。返回的是p.forwards[0],也就是p在第0层的下一个节点。
Node p = head;
for (int levelIndex = levelCount - 1; levelIndex >= 0; levelIndex--) {
while (p.forwards[levelIndex] != null && p.forwards[levelIndex].data < value) {
p = p.forwards[levelIndex];
}
}
if (p.forwards[0] != null && p.forwards[0].data == value) {
return p.forwards[0];
}
return null;
}
public void insert(int value) {
Node p = head;
//随机出节点层数
int level = randomLevel();
//新建节点
Node node = new Node();
node.data = value;
node.maxLevel = level;
//这个数组是加入value值后 0~level-1层对应的下一个节点引用。
Node update[] = new Node[level];
for (int i = level; i >= 0; i--) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
//更新该层节点指向下一个节点。
update[i] = p;
}
for (int i = 0; i < level; i++) {
//将节点值指向下一个节点。
node.forwards[i] = update[i].forwards[i];
//前一个节点指向该节点。
update[i].forwards[i] = node;
}
//更新高度
if (levelCount < level) {
levelCount = level;
}
}
public void delete(int value) {
//删除时需要一个节点数组作为中将桥梁。
Node[] deleteNode = new Node[MAX_LEVEL];
Node p = head;
for (int i = levelCount - 1; i >= 0; i--) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
deleteNode[i] = p;
}
if (p.forwards[0] != null && p.forwards[0].data == value) {
for (int i = levelCount - 1; i >= 0; i--) {
if (deleteNode[i] != null && deleteNode[i].forwards[i].data == value) {
deleteNode[i].forwards[i] = deleteNode[i].forwards[i].forwards[i];
}
}
}
}
public void printAll() {
Node p = head;
while (p.forwards[0] != null) {
System.out.print(p.forwards[0] + " ");
p = p.forwards[0];
}
System.out.println();
}
private int randomLevel() {
int level = 0;
for (int i = 0; i < MAX_LEVEL; i++) {
if (random.nextInt() % 2 == 1) {
level++;
}
}
return level;
}
class Node {
private int data;
/**
*功能描述 :forwards[i]表示该节点在 i 层的下一个节点。
*/
private Node[] forwards = new Node[MAX_LEVEL];
private int maxLevel;
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("{data: ");
sb.append(data);
sb.append("; level: ");
sb.append(maxLevel);
sb.append(" }");
return sb.toString();
}
}
}
代码实现和上面原理图最大的不同点在于每个节点的指针部分。原理图是只有两个指针:下一个和下一层。而代码实现规定了最大层数,然后每个节点拥有16个指针,分别指向节点在该层的下一个节点。就额是说实现代码中只有一类节点。从上一层到下一层的改变只是levelindex的改变。不是指针的改变。
在增加和删除环节都需要一个中间数组进行周转,其实只要想想链表的修改就知道了,一个链表修改需要一个节点指针进行修改,而我们需要修改level层的指针。所以需要长度为level的指针数组进行周转。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号