
Flink概念及数据流编程模型
1、基本概念
- Flink程序的基础构建模块是流Stream(指输入) 和转换Transformations(对输入的数据进行操作,比如map操作、reduce操作)。
- 每一个数据流起始于一个或多个source,并终止于一个或多个sink。
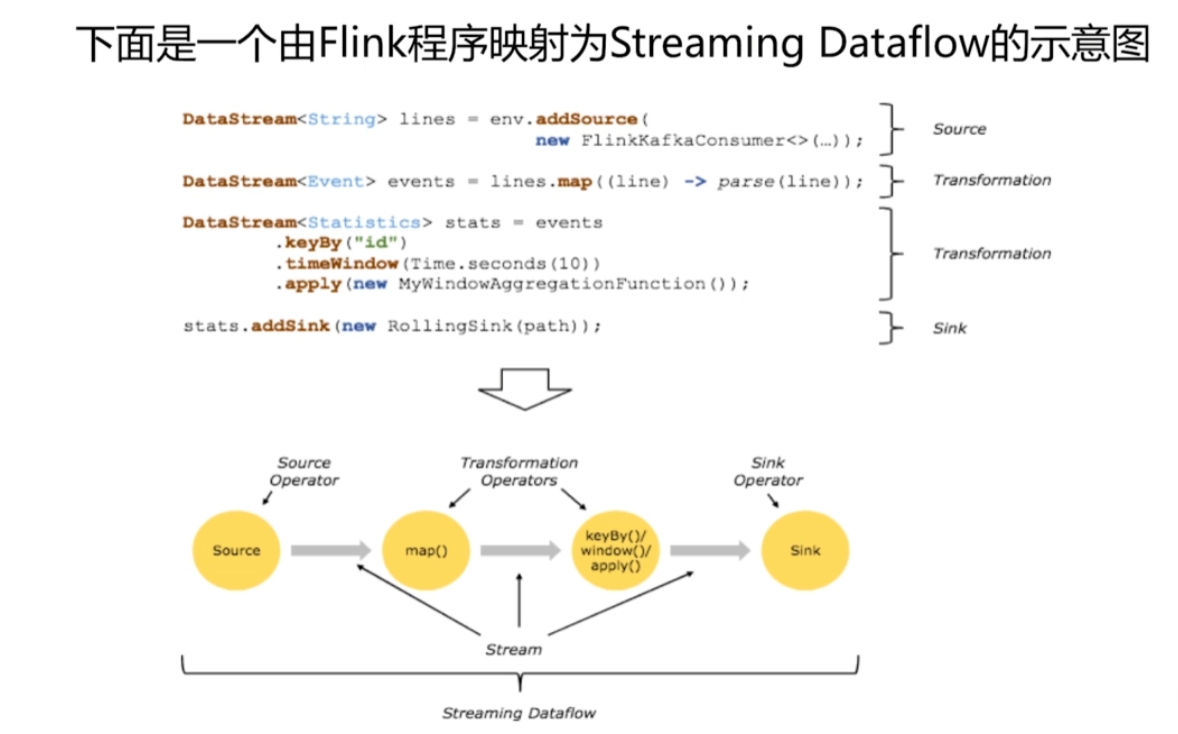
- Flink程序映射为streaming dataflow的示意图。
- env指的是Flink的运行环境或者是上下文。
- addsource new FlinkkafkaConsumer 是通过Flink消费kafka,作为数据输入,即source
- 将输入的数据进行转换,首先是map映射,对每一条数据进行parse解析。假如输入的数据是一个一个的json,那么要把json映射为代码中的实体类。
- 继续进行transformation,进行id聚合、时间窗口的操作、时间窗口函数(等自定义函数)。
- addsink,将处理好的数据进行落地。比如写入数据库。
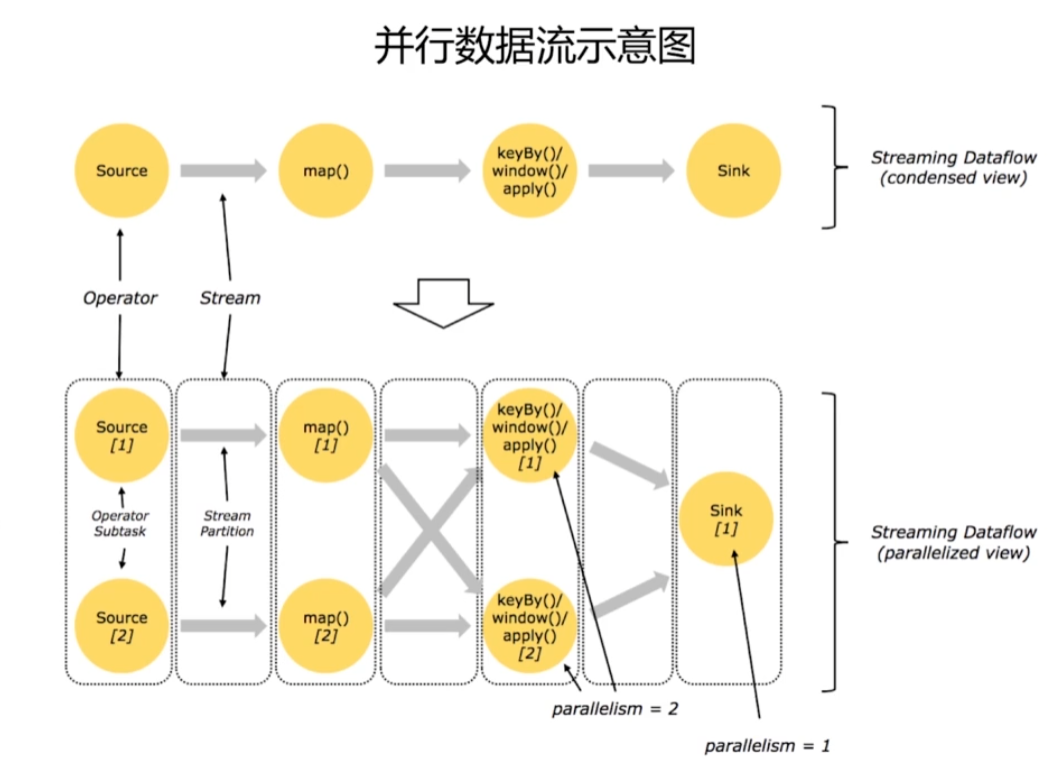
- 并行数据流示意图:
- 数据的输入、转换、输出是可以并行的。
- Flink天生是支持并行的。
- source可以进行分区,将一个source分成多个子任务。对每一个子任务进行map。map后是一个shuffling的过程,然后根据key进行聚合、窗口操作等。
- 最后sink出去。
- 这里设置的并行度为2。即原本一个source拆分为两个并行的source,同时进行计算。
- 时间窗口
- 流上的聚合,需要窗口来划定范围,因为流是无界的。比如 “计算过去的5分钟” 或者 “最后100个元素的和” 。
- 窗口通常被区分为不同的类型,比如滚动窗口(窗口和窗口之间没有数据重叠),滑动窗口(会出现数据重叠),会话窗口(由不活动的间隙所打断)。
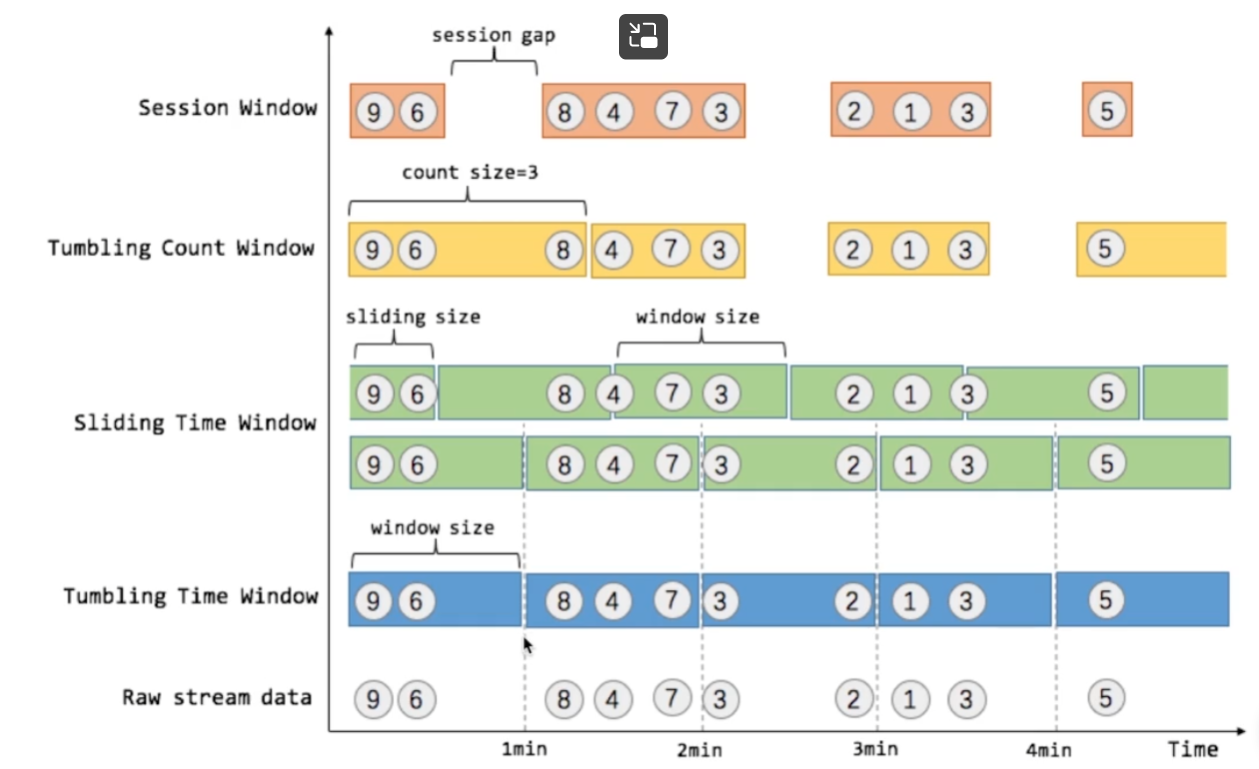
- Flink支持的窗口示意图
- 最后一行为时间线。
- raw stream data 原始数据流:输入的是一个一个的数字。
- tumbling time window 滚动时间窗口:划定1min为一个窗口,即窗口大小为1min。
- sliding time window 滑动时间窗口:需要指定一个sliding size。会出现同一个数字会属于上一个窗口,也会属于下一个窗口,会出现数据的重复。
- trubling count window 滚动数量窗口:需要指定每一个窗口的数据数量。表示一个滚动窗口内需要3调数据。每当窗口里的三条数据抵达后,就开始进行下一个窗口的计算。
- session window 会话窗口:规定假如用户访问10s内,没有操作,则认定一次会话结束。等待下一次会话开始,再进行计算,以此类推。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号