- 正式开始:基于spark流处理框架的学习
- 使用Flume+Kafka+SparkStreaming进行实时日志分析:如何实时地(准实时,每分钟分析一次)收集日志,处理日志,把处理后的记录存入Hive中。
- Flume会实时监控写入日志的磁盘,只要有新的日志写入,Flume就会将日志以消息的形式传递给Kafka,然后Spark Streaming实时消费消息传入Hive。即Spark是一个实时处理的框架。
- Flume是什么呢,它为什么可以监控一个磁盘文件呢?简而言之,Flume是用来收集、汇聚并且移动大量日志文件的开源框架,所以很适合这种实时收集日志并且传递日志的场景。
- Kafka是一个消息系统,Flume收集的日志可以移动到Kafka消息队列中,然后就可以被多处消费了,而且可以保证不丢失数据。
- 通过这套架构,收集到的日志可以及时被Flume发现传到Kafka,通过Kafka我们可以把日志用到各个地方,同一份日志可以存入Hdfs中,也可以离线进行分析,还可以实时计算,而且可以保证安全性,基本可以达到实时的要求。
- 初识Spark Streaming
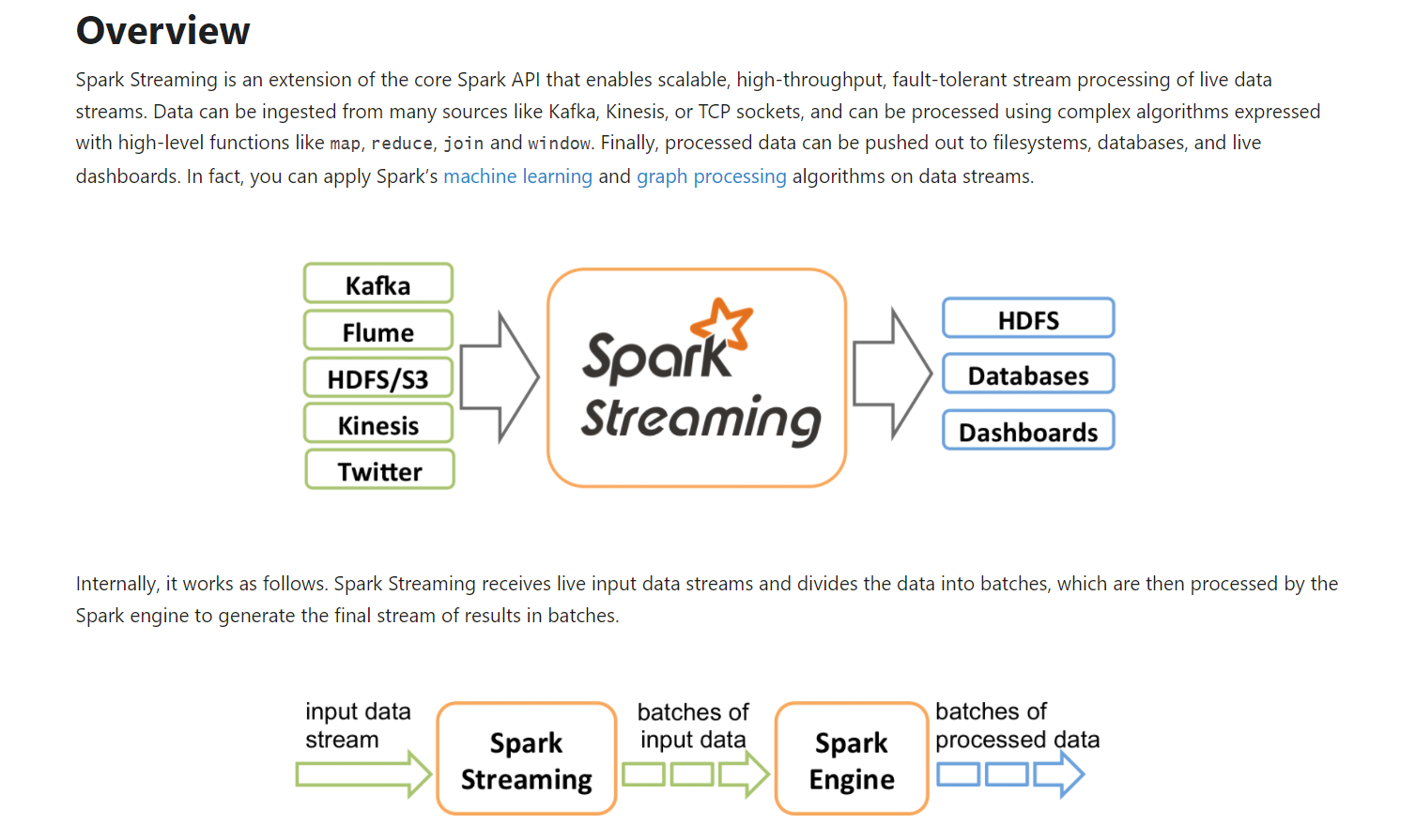
- 一、Spark Streaming概述
- 1)官网:Spark Streaming | Apache Spark ----->Libraries----->Spark Streaming
- 是一个实时的流处理框架:(特点:并易于扩展,容错性)
- 是基于Spark之上的一个流处理框架。
2)想想之前的Flume框架
- 虽然Flume是一个数据收集的框架,但进来的数据也相当于是一个流式的。
- 只要source对接的源端有数据进来,就可以把数据以一个event作为传输单元,将数据收集到目的地。
- 3)到现在为止,我们要有一个认识
- 大数据处理,不论是离线处理/批计算,还是实时处理/流计算,通常情况下,都是比较类似的几个阶段
- 大致情况下,都分成了三阶段
- ① 源端数据的输入:source
- ② 数据的处理:transformation
- ③ 数据的输出:sink
- 二、Spark Streaming宏观角度了解
- 1)官网Spark Streaming - Spark 3.2.0 Documentation (apache.org)----->Programming Guides ----->Spark Streaming(DStreams)
- Spark Streaming底层是基于Spark core的
![]()
- 快速开发第一个应用程序(Spark Streaming的词频统计)
- 一、基于IDEA+Maven构建第一个流处理应用程序(本地开发模型)
1)示例:Spark Streaming的词频统计案例,对接网络数据。
- 感受一下Spark Streaming的编程风格,即套路编程。
- 2)在主pom文件中添加spark streaming的依赖
- 路径:C:\Users\jieqiong\IdeaProjects\spark-log4j\pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<!-- <version>${spark.version}</version>-->
<version>3.0.0</version>
</dependency>
- 3)构建log-ss子工程
- 左击项目----->new----->Module----->Maven----->next
- Artifactld:log-ss
- Module name:log-ss
- 4)修改log-ss的子pom的依赖
- 路径:C:\Users\jieqiong\IdeaProjects\spark-log4j\log-ss\pom.xml
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
</dependency>
</dependencies>
- 5)在这里,更改了本地Maven的指定路径
- ① File--->Settings--->Maven
- ② 将Maven路径改为本地路径
- ③ Maven home path:D:/maven_3.5.0/apache-maven-3.5.0/apache-maven-3.5.0
- ④ User settings file:C:\Users\jieqiong\.m2\settings.xml
- ⑤ 勾选:Always update snapshots
- 6)新建scala文件夹
- 路径:C:\Users\jieqiong\IdeaProjects\spark-log4j\log-ss\src\main----->右键----->new----->directory----->scala
- 原本在C:\Users\jieqiong\IdeaProjects\spark-log4j\log-ss\src\main下是一个java文件夹。
- 7)安装scala插件
- File----->Settings----->Plugins----->搜素scala----->install----->重启idea
- 8)调整scala文件夹
- 右键scala----->mark directory as----->sources root
- 9)新建package
- 路径:C:\Users\jieqiong\IdeaProjects\spark-log4j\log-ss\src\main\scala
- new----->package----->com.imooc.bigdata.ss
- 10)添加scala支持
- 右击log-ss----->add framework support----->选择scala----->选择scala2.12版本
- 11)新建scala class
- C:\Users\jieqiong\IdeaProjects\spark-log4j\log-ss\src\main\scala\com.imooc.bigdata.ss----->new----->scala.class----->NetworkWordCount.object
package com.imooc.bigdata.ss
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*
* object NetworkWordCount作用:完成词频统计分析
* 数据源:是基于端口、网络即nc的方式,造数据
*
* ss的编程范式
* 1)main方法
* 2)找入口点:new StreamingContext().var
* 3)添加SparkConf的构造器:new SparkConf().var
* 4)参数1:sparkConf放入new StreamingContext()
* 5)参数2:Seconds(5)放入new StreamingContext()
* 6)生成ssc:new StreamingContext(sparkConf,Seconds(5)).var
* 7)对接网络数据
* ssc.socketTextStream("spark000",9527).var
* 8)开始业务逻辑处理
* 启动流作业:ssc.start()
* 输入数据以逗号分隔开:map是给每个单词赋值1,,然后两两相加。
lines.flatMap(_.split(",")).map((_,1))
.reduceBykey(_+_).var
* 结果打印:
* 终止流作业:ssc.awaitTermination()
* 9)运行报错,添加val sparkConf = new SparkConf()参数
*/
object NetworkWordCount {
// *****第1步
/*
对于NetworkWordCount这种Spark Streaming编程来讲,也是通过main方法
输入main,回车
*/
def main(args: Array[String]): Unit = {
// *****第2步
/*
和kafka相同,找入口点
官网:https://spark.apache.org/docs/latest/streaming-programming-guide.html
要开发Spark Streaming应用程序,入口点就是:拿到一个streamingContext:new StreamingContext()
看源码:按ctrl,进入StreamingContext.scala
* 关于StreamingContext.scala的描述
Main entry point for Spark Streaming functionality. It provides methods used to create DStream:
[[org.apache.spark.streaming.dstream.DStream]
那 DStream是什么呢?
* 目前,鼠标放在StreamingContext(),报错:不能解析构造器,所以这里缺少构造器
Cannot resolve overloaded constructor `StreamingContext`
在scala里是有构造器的,主构造器、副主构造器。
* 以下就是构造器要传的三个参数
* class StreamingContext private[streaming] (
_sc: SparkContext,
_cp: Checkpoint,
_batchDur: Duration
)
* 这个是副主构造器1:传的是sparkContext
* batchDuration是时间间隔
* def this(sparkContext: SparkContext, batchDuration: Duration) = {
this(sparkContext, null, batchDuration)
}
* 这个是副主构造器2:传的是SparkConf
* def this(conf: SparkConf, batchDuration: Duration) = {
this(StreamingContext.createNewSparkContext(conf), null, batchDuration)
}
*/
// *****第3步
/* 添加SparkConf的构造器
new SparkConf().var
然后选择sparkConf。不建议加类型
*/
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
// *****第2步
/*
new StreamingContext()
*/
// *****第4步
/*
将第3步中新生成的sparkConf,放入new StreamingContext()括号中。
*/
// *****第5步
/*
* 添加时间间隔Duration(毫秒),可以看一下源码
* 使用
* object Seconds {
def apply(seconds: Long): Duration = new Duration(seconds * 1000)
}
* 并导入org.apache的包,往Seconds()放5
* 意味着指定间隔5秒为一个批次
*/
// *****第6步
/*
new StreamingContext(sparkConf,Seconds(5)).var
输入ssc
*/
val ssc = new StreamingContext(sparkConf, Seconds(5))
// TODO... 对接业务数据
// *****第7步:先调用start启动
/*
Creates an input stream from TCP source hostname:port. Data is received using
a TCP socket and the receive bytes is interpreted as UTF8 encoded `\n` delimited
*/
val lines = ssc.socketTextStream("spark000", 9527)
// TODO... 业务逻辑处理
// *****第9步:输入数据以逗号分隔,并打印结果
val result = lines.flatMap(_.split(",")).map((_,1))
.reduceByKey(_+_)
result.print()
// *****第8步:先调用start启动\终止
ssc.start()
ssc.awaitTermination()
}
}
- 二、本地功能测试
- 1)启动端口9527
- 即object NetworkWordCount代码中:val lines = ssc.socketTextStream("spark000", 9527)
[hadoop@spark000 ~]$ nc -lk 9527
- 2)此时运行NetworkWordCount,会报错。是因为 val sparkConf = new SparkConf()参数为空。
- 报错原因分析:
- 报错提示是:SparkContext初始化错误。
- 严格意义,从代码的层面上来看,传递的是SparkConf()进来的,并没有构建SparkContext。
- 来看一下构造器的方法:进入StreamingContext的源码。
- 源码中,我们的确是传递了一个conf和间隔进来的,然后调用副主构造器(通过StreamingContext创建一个新的SparkContext,并将conf传进去),所以看到的是一个SparkContext异常。
- 对于StreamingContext里面几个构造器,它们之间是相互调用的。同一个def中,上面的this调用下面的this。
def this(conf: SparkConf, batchDuration: Duration) = {
this(StreamingContext.createNewSparkContext(conf), null, batchDuration)
}
- 3)添加完参数后,重新运行:5s输出一个时间值。
- 4)在虚拟机的连接器中输入值:a,a,a,b,b,b,c
- 在IDEA中,直接输出词频统计结果:
-------------------------------------------
Time: 1639358875000 ms
-------------------------------------------
(b,3)
(a,3)
(c,1)
- 5)注意:流处理和批处理的开发方式是一样的,只不过对于接数据、输出可能不一样。在core中,是使用connect输出的。
- 6)单拿出以下代码,分析是流处理,还是批处理?是看不出来的。
- 这就是所谓的在流处理和批处理里面,对于业务逻辑处理是可以单独抽象出来的,所以流处理和批处理都可以调用。这样的话,业务逻辑处理就可以统一了。
lines.flatMap(_.split(",")).map((_,1))
.reduceByKey(_+_)
- 7)在生产里面,将两个最后加的参数注解掉,然后就可以将代码提交上去了。
- 8)注意,在本地测试时,一定要先将对接网络数据的端口启起来。
- Spark部署
- 一、Spark部署及服务器端测试
- 1)环境部署
[hadoop@spark000 source]$ tar -zxvf spark-3.0.0.tar.gz
[hadoop@spark000 source]$ ls
spark-3.0.0 spark-3.0.0.tar.gz
-
- ④开始编译Building a Runnable Distribution:
Building Spark - Spark 3.2.0 Documentation (apache.org)
- 已提供编译好的版本了:在app文件中的spark-3.0.0-bin-2.6.0-cdh5.16.2
- 环境版本:The Maven-based build is the build of reference for Apache Spark. Building Spark using Maven requires Maven 3.6.3 and Java 8. Spark requires Scala 2.12; support for Scala 2.11 was removed in Spark 3.0.0.
- 查看HADOOP_HOME版本:
[hadoop@spark000 ~]$ echo $HADOOP_HOME
/home/hadoop/app/hadoop-2.6.0-cdh5.16.2
-
- ⑤在source目录下的spark-3.0.0中,执行编译(时间较长)
./dev/make-distribution.sh \
--name 2.6.0-cdh5.16.2 \
--tgz -Phive -Phive-thriftserver \
-Pyarn
-
- ⑥编译好了之后spark-3.0.0-bin-2.6.0-cdh5.16.2.tgz,直接tar -zxvf解压到app目录。
- ⑦如何提交一个作业?
- 官网的示例:Running Spark on YARN - Spark 3.2.0 Documentation (apache.org)
- ⑧进入spark主目录中,执行
- 执行过程中去浏览器界面看一下spark000
- 在执行界面,查看结果为Pi is roughly 3.14005.....
- 此处报错:INFO Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 6 time(s); retry policy is RetryUpToMaximumCoISECONDS)
- 原因:启动hadoop中的dfs和yarn的脚本即可。
[hadoop@spark000 spark-3.0.0-bin-2.6.0-cdh5.16.2]$ bin/spark-submit --class org.apache.spark.examples.SparkPi \
> --master yarn \
> examples/jars/spark-examples*.jar \
> 2
-
- ⑨开始打包本地代码包
- 注意将AppName和Master两个参数注释掉,一会儿是通过脚本提交的。
- 到C:\Users\jieqiong\IdeaProjects\spark-log4j\log-ss\target下找到log-ss-1.0
- 上传至lib路径下
[hadoop@spark000 lib]$ pwd
/home/hadoop/lib
[hadoop@spark000 lib]$ ls
log-ss-1.0.jar
-
- ⑩再次注意:启动hdf、yarn、Zookeeper、单个Master进程
- /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/sbin
- [hadoop@hadoop000 sbin]$ ./start-dfs.sh
- /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/sbin
- [hadoop@hadoop000 sbin]$ ./start-yarn.sh
- /home/hadoop/app/zookeeper-3.4.5-cdh5.16.2/bin
- zkServer.sh start
- /home/hadoop/app/spark-3.0.0-bin-2.6.0-cdh5.16.2/sbin
- ./start-master.sh
- ⑪脚本启动
spark-submit \
--name jieqiong-network-wc \
--class com.imooc.bigdata.ss.NetworkWordCount \
--master yarn \
/home/hadoop/lib/log-ss-1.0.jar
-
- ⑫启动端口:
- [hadoop@spark000 ~]$ nc -lk 9527
- 输入单词。会在另一个界面进行词频统计。
- 总结:目前来说spark对于我们只是一个客户端。不需要启动本地的spark集群
- 二、StreamingContext编程注意事项
- 1)官网:Spark Streaming - Spark 3.2.0 Documentation (apache.org)
- 2)Initializing StreamingContext
- 这样理解,Context是一个上下文的框,什么东西都可以放到里面。
- 对于SparkStreaming应用程序来说,StreamingContext是一个入口点,所以一定要创建。
- 在StreamingContext或者Streaming core启动过程中,一定要检查conf里的两个参数:spark.master、spark.app.name
- 3)After a context is defined, you have to do the following.(看官网)
- 输入流式通过ssc接收socket话,就是一个hostname+ip。即input DStreams。
- 4)Points to remember.(看官网)
- 一旦ssc.start()启动,就不要再进行其他计算了(result.map等),是无效的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号