
MapReduce之通过Debug的方式了解偏移量及重构代码
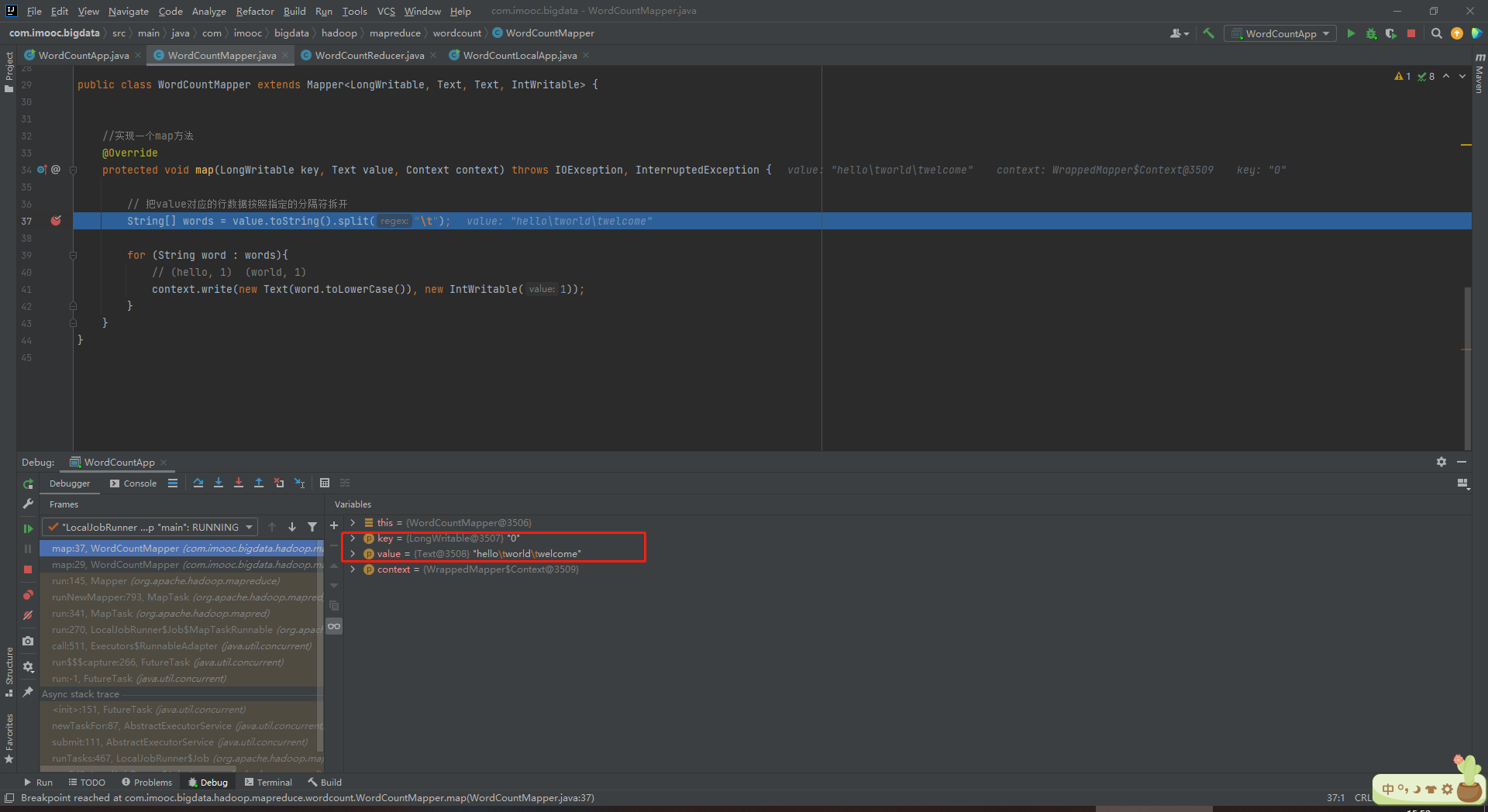
1、在WordCountMapper.java中打断点
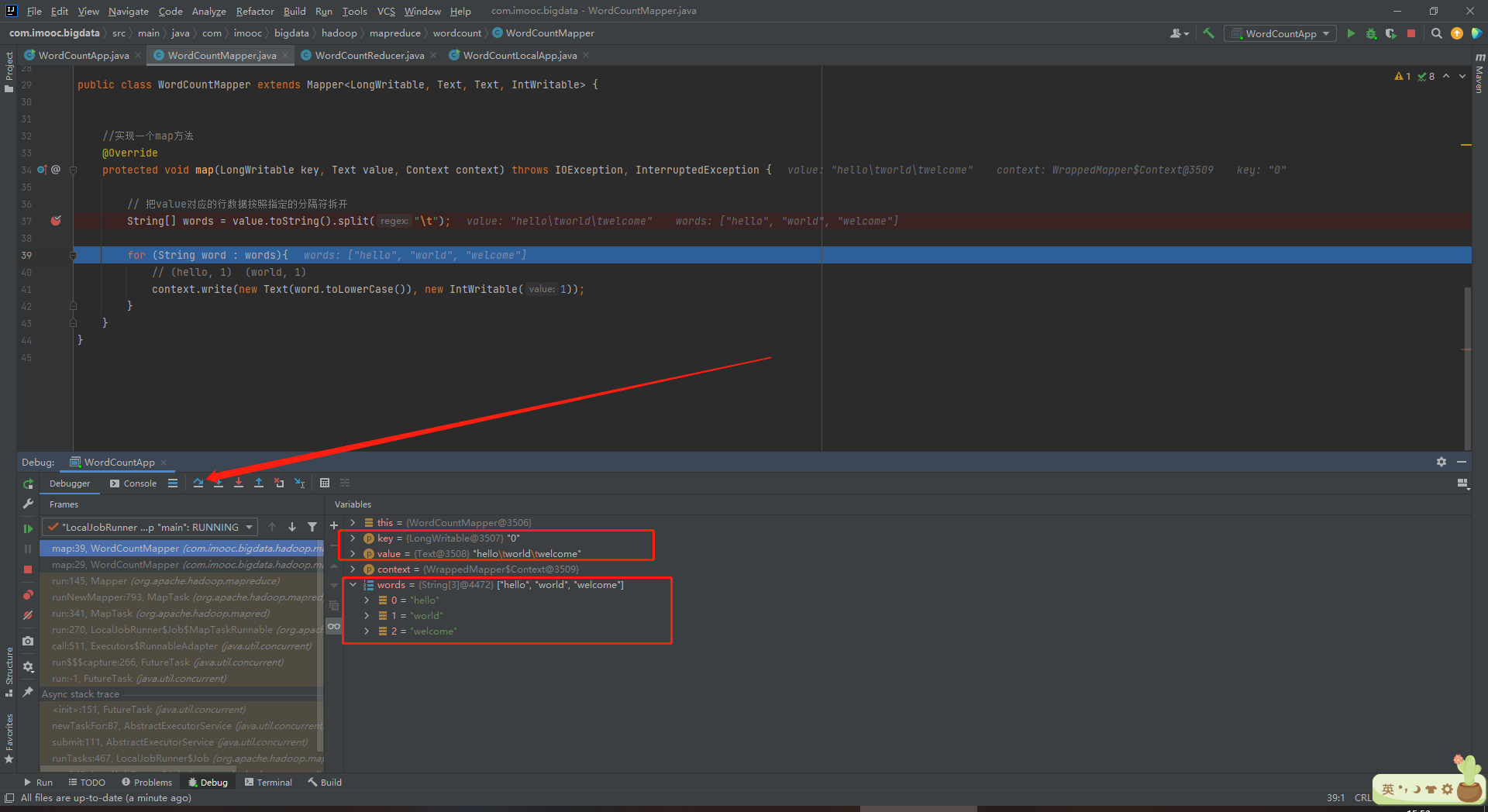
String[] words = value.toString().split("\t");
2、在WordCountApp.java中,以Debug“WordCountApp.main()”方式运行程序
map(LongWritable key, Text value, Context context)
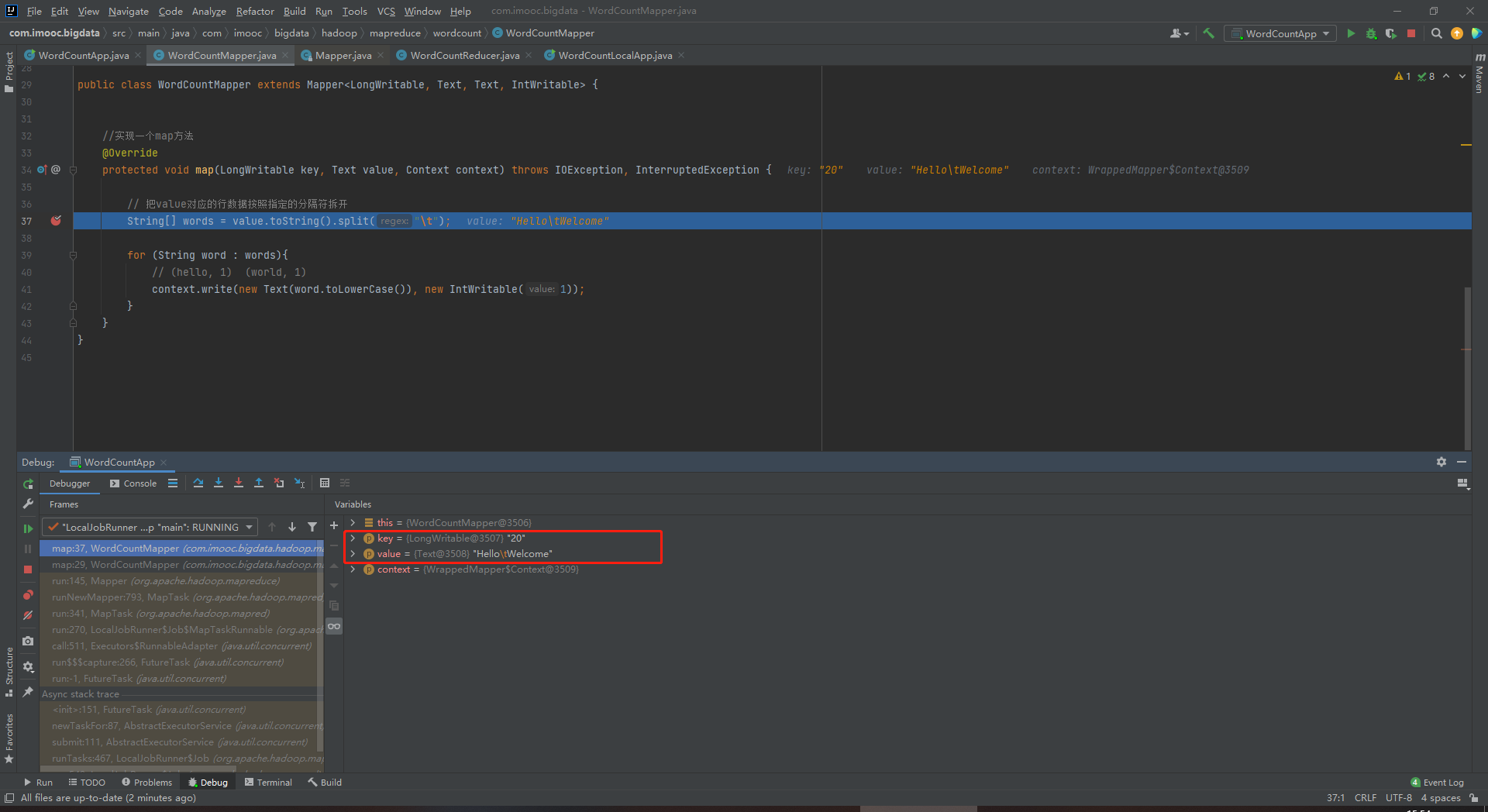
(1)key是每一行起始位置的偏移量。第一行为0,第二行为20
(2)value是每一行的内容值
3、代码重构
(1)主要任务是:删除在HDFS中重复性生成的output文件夹
(2)WordCountApp.java
package com.imooc.bigdata.hadoop.mapreduce.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.net.URI; /* * Driver类:配置Mapper和Reducer的相关属性 * 通过WordCountApp.java将Mapper和Reducer关联起来 * 使用MapReduce统计HDFS上的文件对应的词频 * * 提交到本地运行:开发过程中使用 */ public class WordCountApp { public static void main(String[] args) throws Exception{ //设置权限 System.setProperty("HADOOP_USER_NAME", "hadoop"); Configuration configuration = new Configuration(); //在configuration里设置一些东西: configuration.set("fs.defaultFS", "hdfs://192.168.126.101:8020"); //创建一个Job //将configuration传进来 Job job = Job.getInstance(configuration); //设置Job对应的参数:主类 job.setJarByClass(WordCountApp.class); //设置Job对应的参数:设置自定义的Mapper和Reducer处理类 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); //设置Job对应的参数:Mapper输出key和value的类型 //不需要关注Mapper输入 //Mapper<LongWritable, Text, Text, IntWritable> job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置Job对应的参数:Reducer输出key和value的类型 //不需要关注Reducer输入 //Reducer<Text, IntWritable, Text, IntWritable> job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //如果输出目录已经存在,则先删除 FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.126.101:8020"), configuration, "hadoop"); Path outputPath = new Path("/wordcount/output"); if(fileSystem.exists(outputPath)) { fileSystem.delete(outputPath, true); } //设置Job对应的参数:Mapper输出key和value的类型:作业输入和输出的路径 FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); FileOutputFormat.setOutputPath(job, outputPath); //提交job boolean result = job.waitForCompletion(true); System.exit(result ? 0 : -1); } //若输出失败,添加以下代码 static { try { //G:\BaiduNetdiskDownload\hadoop2.7.6\bin\hadoop.dll System.load("G:\\BaiduNetdiskDownload\\hadoop2.7.6\\bin\\hadoop.dll"); } catch (UnsatisfiedLinkError e) { System.err.println("Native code library failed to load.\n" + e); System.exit(1); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号