
HDFS词频统计功能实现
1、class:HDFSWordCountApp01.java
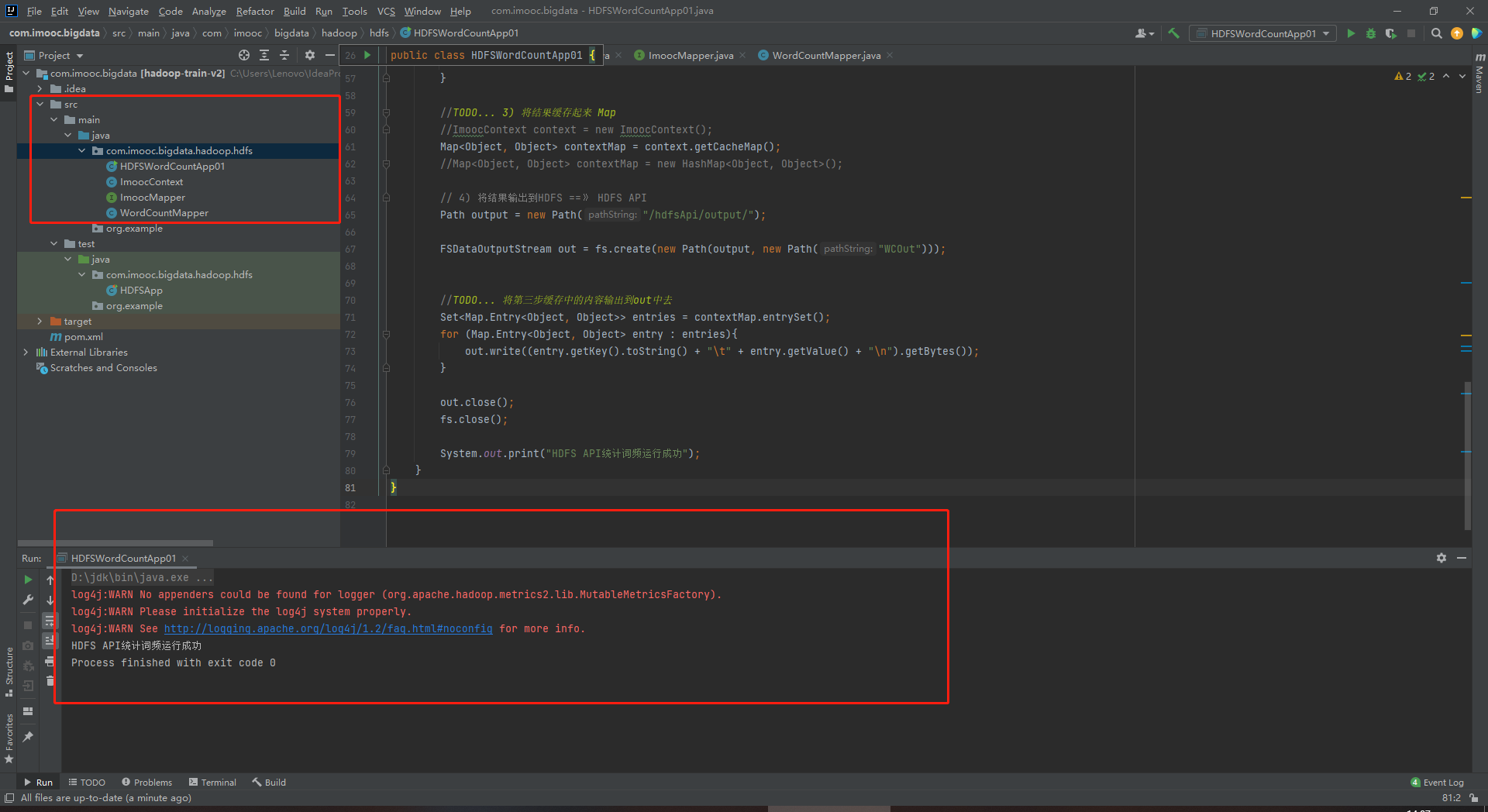
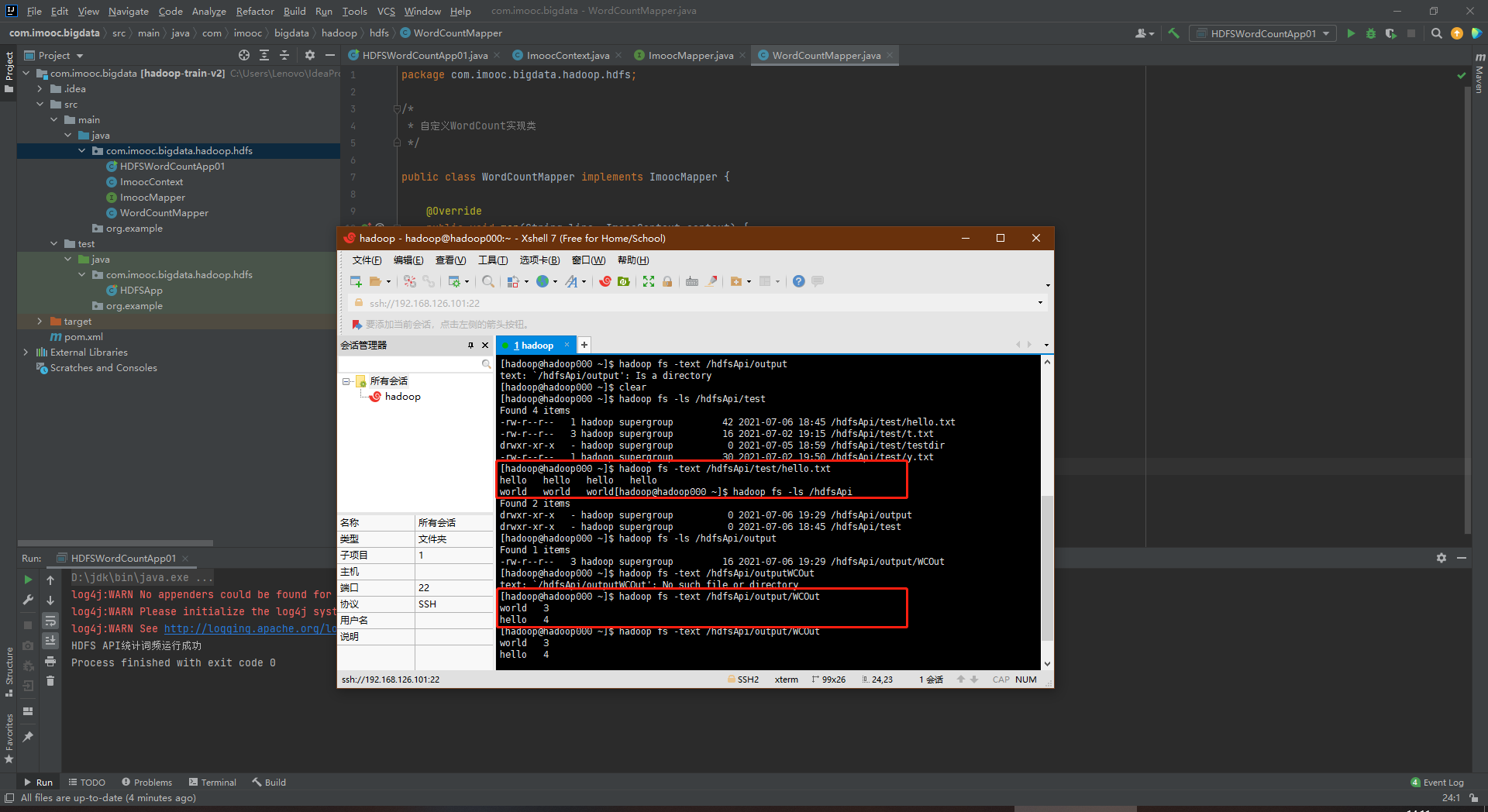
package com.imooc.bigdata.hadoop.hdfs; /* * 使用HDFS API完成WordCount统计 * * 需求:统计HDFS上的文件的词频统计,然后将统计结果输出到HDFS * * 功能拆解: * 1) 读取HDFS上的文件 ==》 HDFS API * 2) 业务处理(词频统计):对文件中的每一行数据都要进行业务处理(按照分隔符分割) ==》 Mapper(抽象类/接口) * 3) 将处理结果缓存起来 ==》 Context(抽象类/接口) * 4) 将结果输出到HDFS ==》 HDFS API * */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.URI; import java.util.HashMap; import java.util.Map; import java.util.Set; public class HDFSWordCountApp01 { public static void main(String[] args) throws Exception{ // 1) 读取HDFS上的文件 ==》 HDFS API Path input = new Path("/hdfsApi/test/hello.txt"); // 获取要操作的HDFS文件系统 FileSystem fs = FileSystem.get(new URI("hdfs://192.168.126.101:8020"), new Configuration(), "hadoop"); //将内容读取出来,此处不使用递归 RemoteIterator<LocatedFileStatus> iterator = fs.listFiles(input,false); //TODO... 自定义处理类 ImoocMapper mapper = new WordCountMapper(); ImoocContext context = new ImoocContext(); //迭代开始: while (iterator.hasNext()){ LocatedFileStatus file = iterator.next(); FSDataInputStream in = fs.open(file.getPath()); BufferedReader reader = new BufferedReader(new InputStreamReader(in)); String line = ""; while ((line = reader.readLine())!= null){ //TODO... 2) 词频处理 //TODO... 在业务逻辑处理之后,将结果写道Cache中 mapper.map(line, context); } reader.close(); in.close(); } //TODO... 3) 将结果缓存起来 Map //ImoocContext context = new ImoocContext(); //移至上方的自定义处理类中,否则迭代中调取不了。 Map<Object, Object> contextMap = context.getCacheMap(); //Map<Object, Object> contextMap = new HashMap<Object, Object>(); // 4) 将结果输出到HDFS ==》 HDFS API Path output = new Path("/hdfsApi/output/"); FSDataOutputStream out = fs.create(new Path(output, new Path("WCOut"))); //TODO... 将第三步缓存中的内容输出到out中去 Set<Map.Entry<Object, Object>> entries = contextMap.entrySet(); for (Map.Entry<Object, Object> entry : entries){ out.write((entry.getKey().toString() + "\t" + entry.getValue() + "\n").getBytes()); } out.close(); fs.close(); System.out.print("HDFS API统计词频运行成功"); } }
2、class:ImoocContext.java
package com.imooc.bigdata.hadoop.hdfs; /* * 自定义上下文,其实就是缓存 */ import java.util.HashMap; import java.util.Map; public class ImoocContext { //使用一个Map结构 private Map<Object, Object> cacheMap = new HashMap<Object, Object>(); //需要外部访问上述的私有Map public Map<Object, Object> getCacheMap(){ return cacheMap; } /* * 写数据到缓存中去 * key 单词 * value 次数 */ public void write(Object key, Object value){ cacheMap.put(key, value); } /* * 从缓存中获取值 * key 单词 * return 单词对应的词频 */ public Object get(Object key) { return cacheMap.get(key); } }
3、Interface:ImoocMapper.java
package com.imooc.bigdata.hadoop.hdfs; /* *自定义Mapper */ public interface ImoocMapper { /* * 先放一个接口 * line 读取到的每一行数据 * context 上下文/缓存 */ public void map(String line, ImoocContext context); }
4、class:WordCountMapper.java
package com.imooc.bigdata.hadoop.hdfs; /* * 自定义WordCount实现类 */ public class WordCountMapper implements ImoocMapper { @Override public void map(String line, ImoocContext context) { String[] words = line.split("\t"); for (String word : words){ Object value = context.get(word); if (value == null){ context.write(word, 1); } else { int v = Integer.parseInt(value.toString()); context.write(word, v+1);//去除单词对应的次数+1 } } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号