package com.imooc.bigdata.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progress;
import org.apache.hadoop.util.Progressable;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.net.URI;
/**
* 使用Java API操作HDFS文件系统
*
* 因为是放在test下面,所以最好使用单元测试的方式
* 在pom中引入的jUnit单元测试的方式
* 单元测试有两个方法:(1)在单元测试之前进行;(2)在单元测试之后进行
*
* 关键点:
* 1)创建Configuration
* 2)获取FileSystem
* 3)剩下的是HDFS API的操作
*/
public class HDFSApp {
public static final String HDFS_PATH = "hdfs://hadoop000:8020";
//Configuration、FileSystem是每一个方法使用之前必须构建的
Configuration configuration = null;
FileSystem fileSystem = null;
@Before
public void setup() throws Exception{
System.out.println("-----setup-----");
configuration = new Configuration();
configuration.set("dfs.replication", "1");
/*
*构造一个访问指定HDFS系统的客户端对象
* 第一个参数:HDFS的URI
* 第二个参数:客户端指定的配置参数
* 第三个参数:客户的用户名
*/
fileSystem = FileSystem.get(new URI("hdfs://hadoop000:8020"), configuration, "hadoop");
}
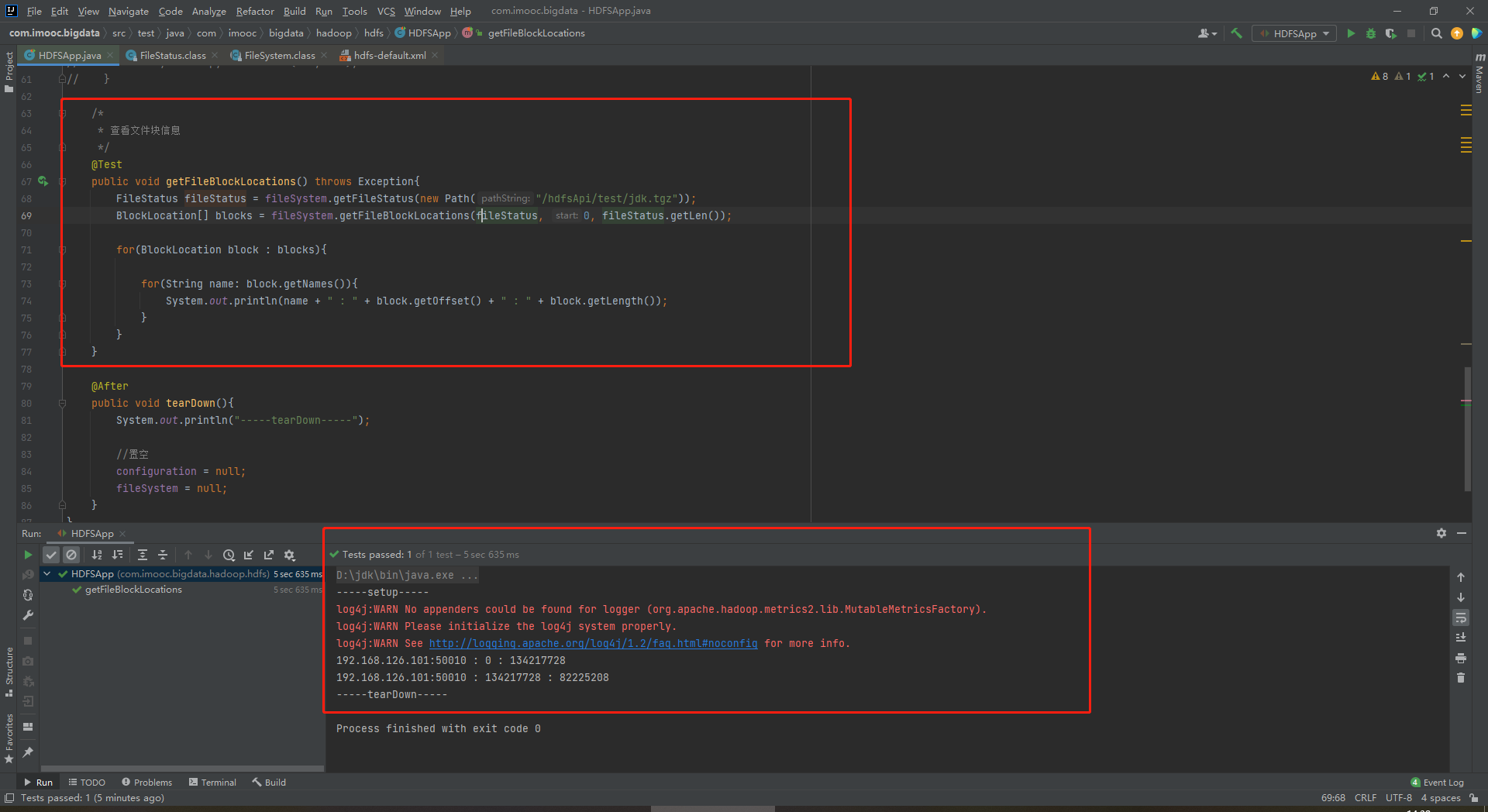
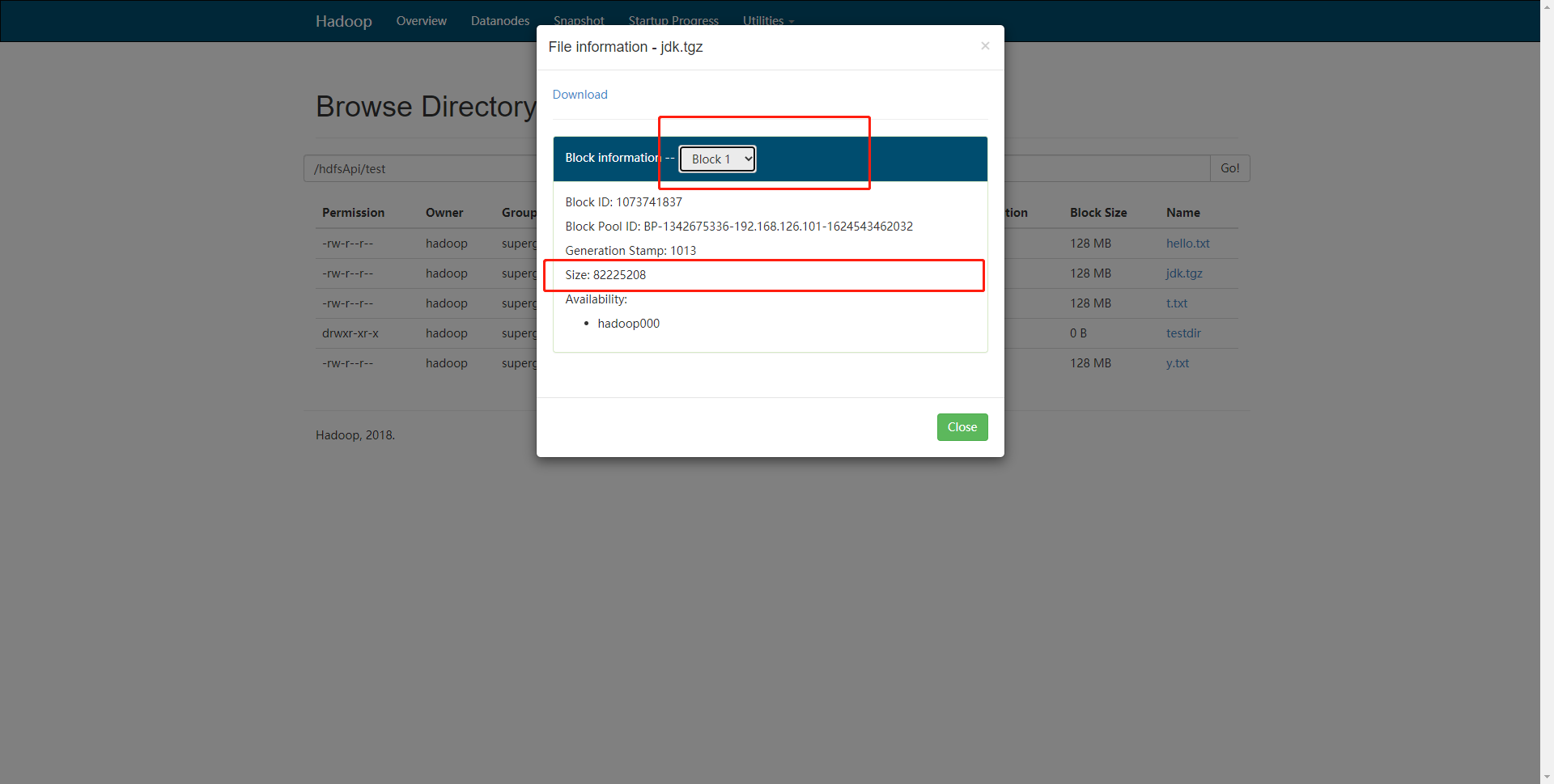
/*
* 查看文件块信息
*/
@Test
public void getFileBlockLocations() throws Exception{
FileStatus fileStatus = fileSystem.getFileStatus(new Path("/hdfsApi/test/jdk.tgz"));
BlockLocation[] blocks = fileSystem.getFileBlockLocations(fileStatus, 0, fileStatus.getLen());
for(BlockLocation block : blocks){
for(String name: block.getNames()){
System.out.println(name + " : " + block.getOffset() + " : " + block.getLength());
}
}
}
@After
public void tearDown(){
System.out.println("-----tearDown-----");
//置空
configuration = null;
fileSystem = null;
}
}
![]()
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号