聚类
一、距离的度量
几种常见的距离度量方式要了解,其中闵可夫斯基距离当p=2时候就是欧式距离,等于1时就是街区距离

二、K-means
步骤:
1、随机选择K个类别中心
2、计算每个样本与中心的距离,标记为距离最小的那个类
3、计算每个簇的平均值作为新的中心,然后重新重复第二步,直到两次样本中心的变化小于某个值就停止
注意:其实k_means算法也有目标函数,目标函数是平方和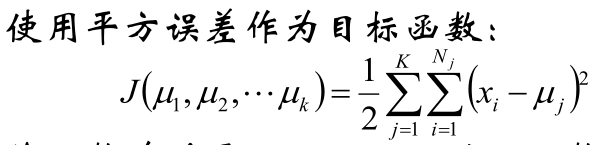 ,这里是运用了梯度下降算法来计算,这个目标函数取导数之后就是均值,也就是我们前面步骤中有做了个平均值作为新的中心的步骤,其实就是梯度下降算法!如果这里目标函数是绝对值,那就是k中值算法,k均值算法这里用了平方误差作为目标函数,与最小二乘法那里其实一样的,最小二乘法是通过高斯模型推导出来,所以这里也默认样本服从高斯分布,也就是k个高斯混合模型!
,这里是运用了梯度下降算法来计算,这个目标函数取导数之后就是均值,也就是我们前面步骤中有做了个平均值作为新的中心的步骤,其实就是梯度下降算法!如果这里目标函数是绝对值,那就是k中值算法,k均值算法这里用了平方误差作为目标函数,与最小二乘法那里其实一样的,最小二乘法是通过高斯模型推导出来,所以这里也默认样本服从高斯分布,也就是k个高斯混合模型!

三、K-means++算法
在k_means基础上增加对初始值的筛选

四、mini-batch k_means
在第三部计算均值过程中,如果样本量太多,会导致速度过慢,这时候如果不是选择所有样本计算均值,而是选择部分样本,这就引入了mini-batch k-means
五、canopy 算法


六、衡量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号