urls 视图层
urls.py 路由层
路由与视图函数对应关系 >>> 路由层
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表。
你就是以这种方式告诉Django,对于这个URL调用这段代码,对于那个URL调用那段代码。
URLconf配置
基本格式:
from django.conf.urls import url
urlpatterns = [
url(正则表达式, views视图函数,参数,别名),
]
注意:
Django 2.0版本中的路由系统已经替换成下面的写法(官方文档):
from django.urls import path
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<int:year>/', views.year_archive),
path('articles/<int:year>/<int:month>/', views.month_archive),
path('articles/<int:year>/<int:month>/<slug:slug>/', views.article_detail),
]
举例:
from django.conf.urls import url
from django.contrib import admin
from app02 import views
urlpatterns = [
url(r'^book_list/', views.book_list),
url(r'test', views.test),
url(r'test_add', views.test_add),
]
url内部的规则
参数说明
- url第一个参数是一个正则表达式
- 一旦匹配上了 会立刻执行对应的视图函数 不再往下匹配了
- 正则表达式:一个正则表达式字符串
- views视图函数:一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
- 参数:可选的要传递给视图函数的默认参数(字典形式)
- 别名:一个可选的name参数
注意
- 若要从URL 中捕获一个值,只需要在它周围放置一对圆括号。
- 不需要添加一个前导的反斜杠,因为每个URL 都有。例如,应该是
^articles而不是^/articles。 - 每个正则表达式前面的'r' 是可选的但是建议加上。它告诉Python 这个字符串是“原始的” —— 字符串中任何字符都不应该转义
- urlpatterns中的元素按照书写顺序从上往下逐一匹配正则表达式,一旦匹配成功则不再继续
示例:
'''
一些请求的例子:
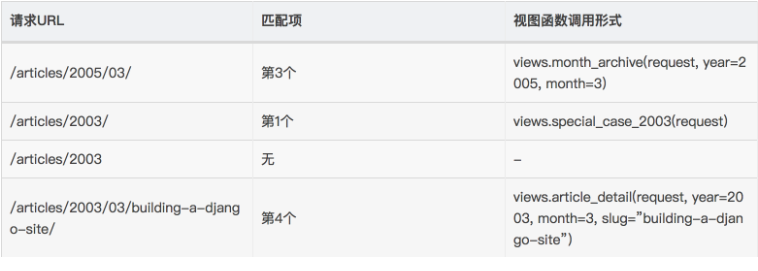
/articles/2005/03/ 请求将匹配列表中的第三个模式。Django 将调用函数views.month_archive(request, '2005', '03')。
/articles/2005/3/ 不匹配任何URL 模式,因为列表中的第三个模式要求月份应该是两个数字。
/articles/2003/ 将匹配列表中的第一个模式不是第二个,因为模式按顺序匹配,第一个会首先测试是否匹配。请像这样自由插入一些特殊的情况来探测匹配的次序。
/articles/2003 不匹配任何一个模式,因为每个模式要求URL 以一个反斜线结尾。
/articles/2003/03/03/ 将匹配最后一个模式。Django 将调用函数views.article_detail(request, '2003', '03', '03')。
'''
APPEND_SLASH
APPEND_SLASH:是否开启URL访问地址后面不为/跳转至带有/的路径的配置项
# 是否开启URL访问地址后面不为/跳转至带有/的路径的配置项
APPEND_SLASH=True
Django settings.py配置文件中默认没有 APPEND_SLASH 这个参数,但 Django 默认这个参数为 APPEND_SLASH = True。 其作用就是自动在网址结尾加'/'。
其效果就是:
我们定义了urls.py:
from django.conf.urls import url
from app01 import views
urlpatterns = [
url(r'^blog/$', views.blog),
]
访问 http://www.example.com/blog 时,默认将网址自动转换为 http://www.example/com/blog/ 。
如果在settings.py中设置了 APPEND_SLASH=False,此时我们再请求 http://www.example.com/blog 时就会提示找不到页面。
无名分组与有名分组
分组:给某一段正则表达式加括号
在使用Django 项目时,一个常见的需求是获得URL的最终形式,以用于嵌入到生成的内容中(视图中和显示给用户的URL等)或者用于处理服务器端的导航(重定向等)。
人们强烈希望不要硬编码这些URL(费力、不可扩展且容易产生错误)或者设计一种与URLconf 毫不相关的专门的URL 生成机制,因为这样容易导致一定程度上产生过期的URL。
换句话讲,需要的是一个DRY 机制。除了其它有点,它还允许设计的URL 可以自动更新而不用遍历项目的源代码来搜索并替换过期的URL。
获取一个URL 最开始想到的信息是处理它视图的标识(例如名字),查找正确的URL 的其它必要的信息有视图参数的类型(位置参数、关键字参数)和值。
Django 提供一个办法是让URL 映射是URL 设计唯一的地方。你填充你的URLconf,然后可以双向使用它:
- 根据用户/浏览器发起的URL 请求,它调用正确的Django 视图,并从URL 中提取它的参数需要的值。
- 根据Django 视图的标识和将要传递给它的参数的值,获取与之关联的URL。
第一种方式是我们在前面的章节中一直讨论的用法。第二种方式叫做反向解析URL、反向URL 匹配、反向URL 查询或者简单的URL 反查。
在需要URL 的地方,对于不同层级,Django 提供不同的工具用于URL 反查:
- 在模板中:使用url模板标签。
- 在Python 代码中:使用django.core.urlresolvers.reverse() 函数。
- 在更高层的与处理Django 模型实例相关的代码中:使用get_absolute_url() 方法。
上面说了一大堆,你可能并没有看懂。(那是官方文档的生硬翻译)。
咱们简单来说就是可以给我们的URL匹配规则起个名字,一个URL匹配模式起一个名字。
这样我们以后就不需要写死URL代码了,只需要通过名字来调用当前的URL。
举个简单的例子:
url(r'^home', views.home, name='home'), # 给我的url匹配模式起名为 home
url(r'^index/(\d*)', views.index, name='index'), # 给我的url匹配模式起名为index
这样:
在模板里面可以这样引用:
{% url 'home' %}
在views函数中可以这样引用:
from django.urls import reverse
reverse("index", args=("2018", ))
例子:
考虑下面的URLconf:
from django.conf.urls import url
from . import views
urlpatterns = [
# ...
url(r'^articles/([0-9]{4})/$', views.year_archive, name='news-year-archive'),
# ...
]
根据这里的设计,某一年nnnn对应的归档的URL是/articles/nnnn/。
你可以在模板的代码中使用下面的方法获得它们:
<a href="{% url 'news-year-archive' 2012 %}">2012 Archive</a>
<ul>
{% for yearvar in year_list %}
<li><a href="{% url 'news-year-archive' yearvar %}">{{ yearvar }} Archive</a></li>
{% endfor %}
</ul>
在Python 代码中,这样使用:
from django.urls import reverse
from django.shortcuts import redirect
def redirect_to_year(request):
# ...
year = 2006
# ...
return redirect(reverse('news-year-archive', args=(year,)))
如果出于某种原因决定按年归档文章发布的URL应该调整一下,那么你将只需要修改URLconf 中的内容。
在某些场景中,一个视图是通用的,所以在URL 和视图之间存在多对一的关系。对于这些情况,当反查URL 时,只有视图的名字还不够。
注意:
为了完成上面例子中的URL 反查,你将需要使用命名的URL 模式。URL 的名称使用的字符串可以包含任何你喜欢的字符。不只限制在合法的Python 名称。
当命名你的URL 模式时,请确保使用的名称不会与其它应用中名称冲突。如果你的URL 模式叫做comment,而另外一个应用中也有一个同样的名称,当你在模板中使用这个名称的时候不能保证将插入哪个URL。
在URL 名称中加上一个前缀,比如应用的名称,将减少冲突的可能。我们建议使用myapp-comment 而不是comment。
无名分组
urlpatterns = [
url(r'^test/(\d+)', views.test),
]
会将括号内匹配到的内容当做 位置参数 传递给后面的视图函数
def test(request,args):
print(args)
return HttpResponse('test')
有名分组:给正则表达式起别名
urlpatterns = [
url(r'^test/(?P<year>\d+)', views.test),
]
会将括号内匹配到的内容当做 关键字参数 传递给后面的视图函数
方式1
# def test(request,**kwargs):
# print(kwargs)
# return HttpResponse('test')
方式2
def test(request,year):
print(year,1)
return HttpResponse('test')
-
无名和有名能否结合使用
不能结合使用,但是无名和有名 可以使用多次 -
有名无名单独使用的情况下 可以用多个
url(r'^test/(\d+)/(\d+)/', views.test),
url(r'^test/(?P<xxx>\d+)/(?P<month>\d+)/', views.test),
反向解析
在使用Django 项目时,一个常见的需求是获得URL 的最终形式,以用于嵌入到生成的内容中(视图中和显示给用户的URL等)或者用于处理服务器端的导航(重定向等)。人们强烈希望不要硬编码这些URL(费力、不可扩展且容易产生错误)或者设计一种与URLconf 毫不相关的专门的URL 生成机制,因为这样容易导致一定程度上产生过期的URL。
在需要URL 的地方,对于不同层级,Django 提供不同的工具用于URL 反查:
- 在模板中:使用url 模板标签。
- 在Python 代码中:使用
from django.urls import reverse()函数
根据某一个东西 动态解析出一个结果 该结果可以直接访问对应的url
url(r'^test_add/', views.testadd,name='xxx')
前端解析
{% url 'xxx' %}
后端解析
from django.shortcuts import render,HttpResponse,redirect,reverse
url = reverse('xxx')
无名分组反向解析
url(r'^test_addsajdsjkahdkjasjkdh/(\d+)/', views.testadd,name='xxx'),
前端解析
<a href="{% url 'xxx' 1 %}">222</a>
后端解析
url = reverse('xxx',args=(1,))
有名分组反向解析
url(r'^test_addsajdsjkahdkjasjkdh/(?P<year>\d+)/', views.testadd,name='xxx')
前端解析
<a href="{% url 'xxx' 1 %}">222</a>
<a href="{% url 'xxx' year=1 %}">222</a>
后端解析
url = reverse('xxx',args=(1,))
url = reverse('xxx',kwargs={'year':123})
**注意 反向解析的别名 一定不要重复 **
路由分发(******)
django里面的app可以有自己的static文件,templates文件夹,urls.py(******)
项目名下面的urls.py不再做路由与视图函数对应关系
而是做一个中转站 只负责将请求分发到不同的app中
然后在app的urls.py完成路由与视图函数的对应关系
from django.conf.urls import url,include
url(r'^app01/',include(app01_urls)),
url(r'^app02/',include(app02_urls))
名称空间
命名空间(英语:Namespace)是表示标识符的可见范围。一个标识符可在多个命名空间中定义,它在不同命名空间中的含义是互不相干的。这样,在一个新的命名空间中可定义任何标识符,它们不会与任何已有的标识符发生冲突,因为已有的定义都处于其它命名空间中。
由于name没有作用域,Django在反解URL时,会在项目全局顺序搜索,当查找到第一个name指定URL时,立即返回
我们在开发项目时,会经常使用name属性反解出URL,当不小心在不同的app的urls中定义相同的name时,可能会导致URL反解错误,为了避免这种事情发生,引入了命名空间。
解决各个app之间命名的重复 ,django是分不清楚。
总路由
url(r'^app01/',include('app01.urls',namespace='app01'))
url(r'^app02/',include('app02.urls',namespace='app02'))
print(reverse('app01:index'))
print(reverse('app02:index'))
通常情况下 起别名的时候 前面可以加上你的应用名
创建一个app02:python manage.py startapp app02
总urls.py
from django.urls import path,re_path,include
urlpatterns = [
path('app01/', include('app01.urls')),
path('app02/', include('app02.urls'))
]
app01 的urls.py
from django.urls import path,re_path
from app01 import views
urlpatterns = [
re_path(r'index/',views.index,name='index'),
]
app02 的urls.py
from django.urls import path, re_path, include
from app02 import views
urlpatterns = [
re_path(r'index/', views.index,name='index'),
]
app01的视图函数
def index(request):
url=reverse('index')
print(url)
return HttpResponse('index app01')
app02的视图函数
def index(request):
url=reverse('index')
print(url)
return HttpResponse('index app02')
这样都找index,app01和app02找到的都是app02的index
如何处理?在路由分发的时候指定名称空间
总urls.py在路由分发时,指定名称空间
path('app01/', include(('app01.urls','app01'))),
path('app02/', include(('app02.urls','app02')))
url(r'app01/',include('app01.urls',namespace='app01')),
url(r'app02/',include('app02.urls',namespace='app02'))
url(r'app01/',include(('app01.urls','app01'))),
url(r'app02/',include(('app02.urls','app02')))
在视图函数反向解析的时候,指定是那个名称空间下的
url=reverse('app02:index')
print(url)
url2=reverse('app01:index')
print(url2)
在模版里:
<a href="{% url 'app02:index'%}">哈哈</a>
伪静态
- 将动态网页假装成是静态的(看起来是html页面)
- 这样做的目的是为了提高搜索引擎的SEO查询优先级
- 搜索在收录网站的时候 会优先收录看上去像是静态文件的资源
- 但是无论你怎么使用伪静态进行优化 你也干不过RMB玩家
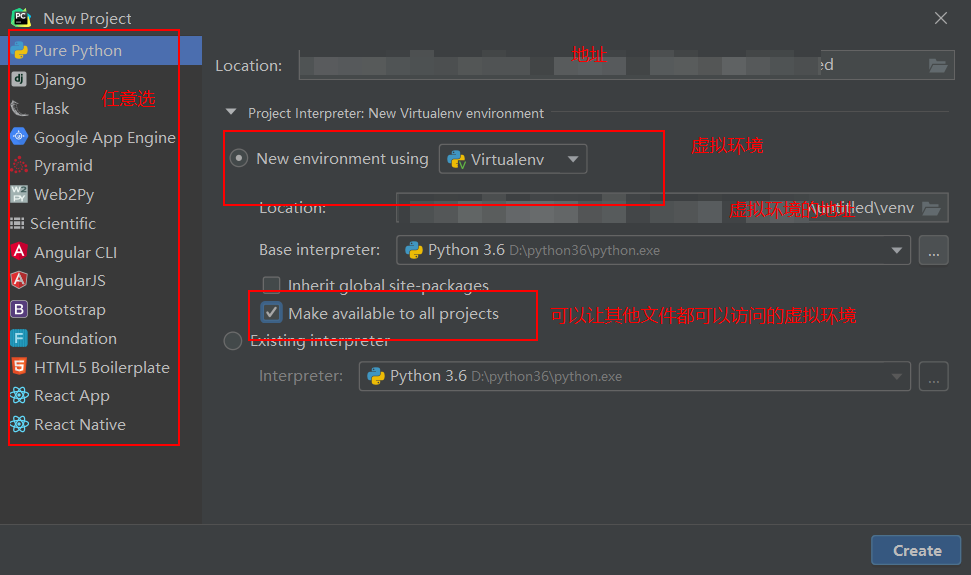
虚拟环境
通常针对不同的项目 只会安装该项目所用的模块 用不到的一概不装
虚拟环境
-
不同的项目应该有各自独立的解释器环境 最大化节省资源
-
实际功能中针对不同的项目 会有一个叫requestsments.txt文件
-
该文件中列出来是一个个该项目需要用的到模块名和版本号
eg:
django = 1.11.11
nginx = 1.21 -
后期通过命令直接会去下载该文件内所有的模块及对应版本
不同的项目有专门的解释器环境与之对应
每创建一个虚拟环境 就类似于重新下载了一个纯净的python解释器
虚拟环境不要创建太多个
建议 你的机器上不要有态多的虚拟环境
当前我们这个阶段 建议你所有的模块全部都安装在本机环境中
虚拟环境的后期用法(了解)
python中通过requirements.txt来记录项目所有的依赖包及其版本号,以便在其他的环境中部署
(venv) $ pip freeze >requirements.txt
如果在开发的时候升级了依赖包,记得更新此文件!
在其他环境部署项目之前先通过如下命令安装依赖包,也就是当需要创建这个虚拟环境的完全副本,可以创建一个新的虚拟环境,并在其上运行以下命令:
(venv) $ pip install -r requirements.txt
pip的freeze命令保存了保存当前Python环境下所有类库包,其它包括那些你没有在当前项目中使用的类库。 (如果你没有的virtualenv)。
pip的freeze命令只保存与安装在您的环境python所有软件包。
但有时你只想将当前项目使用的类库导出生成为 requirements.txt;
使用方法:
$ pip install pipreqs $ pipreqs /path/to/project
django版本区别
django1.x
django2.x
区别1:
urls.py中1.x用的是url,而2.x用的是path
并且2.x中的path第一个不支持正则表达式,写什么就匹配什么
如果你觉得不好用,2.x里面还有re_path 这个re_path就是你1.x里面的url
django2.0的re_path和1.0的url一样
思考情况如下:
urlpatterns = [
re_path('articles/(?P<year>[0-9]{4})/', year_archive),
re_path('article/(?P<article_id>[a-zA-Z0-9]+)/detail/', detail_view),
re_path('articles/(?P<article_id>[a-zA-Z0-9]+)/edit/', edit_view),
re_path('articles/(?P<article_id>[a-zA-Z0-9]+)/delete/', delete_view),
]
考虑下这样的两个问题:
第一个问题,函数 year_archive 中year参数是字符串类型的,因此需要先转化为整数类型的变量值,当然year=int(year) 不会有诸如如TypeError或者ValueError的异常。那么有没有一种方法,在url中,使得这一转化步骤可以由Django自动完成?
第二个问题,三个路由中article_id都是同样的正则表达式,但是你需要写三遍,当之后article_id规则改变后,需要同时修改三处代码,那么有没有一种方法,只需修改一处即可?
在Django2.0中,可以使用 path 解决以上的两个问题。
基本示例
这是一个简单的例子:
from django.urls import path
from . import views
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<int:year>/', views.year_archive),
path('articles/<int:year>/<int:month>/', views.month_archive),
path('articles/<int:year>/<int:month>/<slug>/', views.article_detail),
# path才支持,re_path不支持 path('order/<int:year>',views.order),
]
基本规则:
- 使用尖括号(
<>)从url中捕获值。 - 捕获值中可以包含一个转化器类型(converter type),比如使用
<int:name>捕获一个整数变量。若果没有转化器,将匹配任何字符串,当然也包括了/字符。 - 无需添加前导斜杠。
以下是根据 2.0官方文档 而整理的示例分析表:(跟上面url的匹配关系)
path转化器
文档原文是Path converters,暂且翻译为转化器。
Django默认支持以下5个转化器:
- str,匹配除了路径分隔符(
/)之外的非空字符串,这是默认的形式 - int,匹配正整数,包含0。
- slug,匹配字母、数字以及横杠、下划线组成的字符串。
- uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
- path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
注册自定义转化器
对于一些复杂或者复用的需要,可以定义自己的转化器。转化器是一个类或接口,它的要求有三点:
-
regex类属性,字符串类型 -
to_python(self, value)方法,value是由类属性regex所匹配到的字符串,返回具体的Python变量值,以供Django传递到对应的视图函数中。 -
to_url(self, value)方法,和to_python相反,value是一个具体的Python变量值,返回其字符串,通常用于url反向引用。
例子:
class FourDigitYearConverter:
regex = '[0-9]{4}'
def to_python(self, value):
return int(value)
def to_url(self, value):
return '%04d' % value
使用register_converter 将其注册到URL配置中:
from django.urls import register_converter, path
from . import converters, views
register_converter(converters.FourDigitYearConverter, 'yyyy')
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<yyyy:year>/', views.year_archive),
...
]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号