
读取数据集的范本(自TextLevelGNN的源码)
TextLevelGNN的源码地址
https://github.com/yenhao/text-level-gnn
不一样的数据集,不一样的摆放,至今都不会处理orz,找别人的轮子,
dataset2folder:dict = {'R8':'R8', 'R52':'R52', '20ng':'20ng', 'Ohsumed':'ohsumed_single_23', 'MR':'mr'}
数据集结构如下:
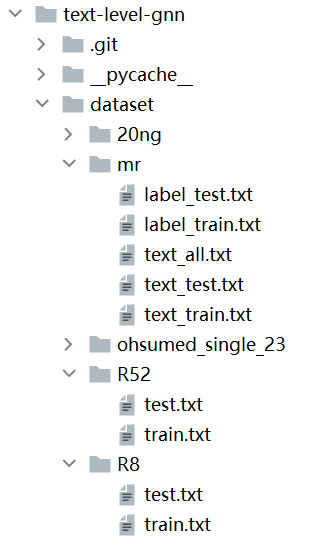
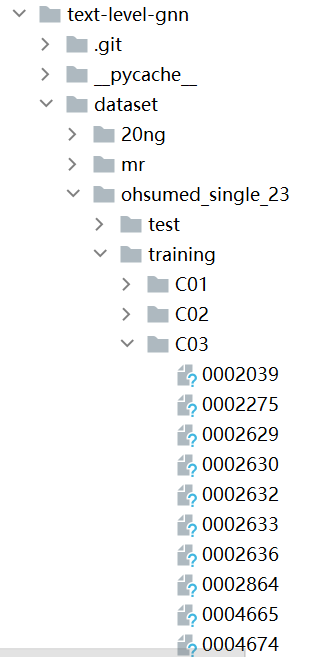
R8 R52

import os import pandas as pd import numpy as np from collections import Counter, defaultdict from nltk.tokenize import TweetTokenizer import multiprocessing as mp def read_data(exp_dataset : str, data_path:str = 'dataset', dataset2folder:dict = {'R8':'R8', 'R52':'R52', '20ng':'20ng', 'Ohsumed':'ohsumed_single_23', 'MR':'mr'}): """Read the dataset by handling multiple datasets' structure for each experiment and return in pandas DataFrame format. Args: exp_dataset (str): The experiment dataset to conduct. data_path (str, optional): The folders that store the dataset. Defaults to 'dataset'. dataset2folder (dict, optional): The dictionary mapping for the name and folder_name of the dataset. Defaults to {'R8':'R8', 'R52':'R52', '20ng':'20ng', 'Ohsumed':'ohsumed_single_23', 'MR':'mr'}. Returns: pandas.DataFrame: The DataFrame is constructed with columns: 1.target - Specify the each row of data is for train or test purpose. 2.label - The label for each row 3.text - The textual content for each row """ print("\nLoading dataset..") dataset = [] # R20 if exp_dataset=='R8' or exp_dataset =='R52': targets = ['train.txt', 'test.txt'] for target in targets: text_data_path = os.path.join(data_path, dataset2folder[exp_dataset], target) with open(text_data_path) as f: lines = f.readlines() for line in lines: label, text = line.strip().split('\t') # add doc dataset.append((target[:-4], label, text)) # ohsumed_single_23 elif exp_dataset == 'Ohsumed': targets = {'training':'train', 'test':'test'} for target in targets: trainind_data_path = os.path.join(data_path, dataset2folder[exp_dataset], target) for label in os.listdir(trainind_data_path): for doc in os.listdir(os.path.join(trainind_data_path, label)): with open(os.path.join(trainind_data_path, label, doc)) as f: lines = f.readlines() text = " ".join([line.strip() for line in lines]) # add doc dataset.append((targets[target], label, text)) # 20 ng elif exp_dataset =='20ng': from sklearn.datasets import fetch_20newsgroups for target in ['train', 'test']: data = fetch_20newsgroups(subset=target, shuffle=True, random_state=42, remove = ('headers', 'footers', 'quotes')) dataset += list(map(lambda sample: (target, data['target_names'][sample[0]], sample[1].replace("\n", " ")), zip(data['target'], data['data']))) # movie review elif exp_dataset == 'MR': for target in ['train', 'test']: text_data_path = os.path.join(data_path, dataset2folder[exp_dataset], "text_{}.txt".format(target)) with open(text_data_path, 'rb') as f: text_lines = f.readlines() label_data_path = os.path.join(data_path, dataset2folder[exp_dataset], "label_{}.txt".format(target)) with open(label_data_path, 'rb') as f: label_lines = f.readlines() dataset += [(target, str(label.strip()), str(text.strip())) for (text, label) in zip(text_lines, label_lines)] else: print("Wrong dataset!") exit() print("\tDataset Loaded! Total:", len(dataset)) return pd.DataFrame(dataset, columns=["target", "label", "text"])
dataset.append((target[:-4], label, text))出来后是这个样子('train', 'earn', 'text')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号