

文本分类 4labels TFIDF_naive_bayes_wy
2020-04-25
这篇文章是对一位博主文章的理解,转载内容较多。作者十分耐心引导读者,特意使用相对路径和生成大量中间文件,对学习帮助很大,其实完全可以省略生成的text文件,简洁版没有生成中间文件。
主要参考文章:
作者:懒骨头707
(已修改)机器学习之文本分类(附带训练集+数据集+所有代码)https://blog.csdn.net/qq_28626909/article/details/80382029
机器学习之文本分类(附带训练集+数据集+所有代码)https://blog.csdn.net/qq_28626909/article/details/80382029
原作者的数据集链接:https://pan.baidu.com/s/1NSRC33fvqwfMmyb_E85WGg 提取码:0uln
目录结构
运行前目录文件
4个分类名称
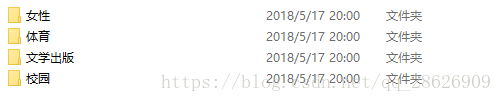
运行后生成文件


bunch的形式为{target_name, label, filename, tdm, vocabulary}
有些什么主要函数
训练
segText(①, ②)
bunchsave(②, a④)
getTFIDFMat(a④, ④, a①, b①,b②, b⑤) ps:红色输入,绿色输出,其他辅助,下同
测试
segText(⑤, ③)
bunchsave(③, a②)
getTestSpace(a②, a①, ④, a③, b⑦, b⑧, b⑥)
bayesAlgorithm(a①, a③ ,b③, b④, b⑨, b⑩)
普通函数
readFile
saveFile
readBunch
writeBunch
getStopWord
2020-05-01
用啰嗦的话讲每个函数
segText
遍历主目录下四个分类的txt文件,把分词结果txt放入结果目录中
content = readFile(eachPathFile) # 调用上面函数读取内容
result = (str(content)).replace("\r\n", "").strip() # 删除多余空行与空格
cutResult = jieba.cut(result) # 默认方式分词,分词结果用空格隔开
bunchSave
定义一个bunch。bunch = Bunch(target_name=[], label=[], filenames=[], contents=[])
把四个类别名、当前标签分类、当前文件全路径、文件词向量给到bunch,生成并保存dat文件
2020-05-02
getTFIDFMat(a④, ④, a①, b①,b②, b⑤)(求得TF-IDF向量)
1、读训练集分词后bunch,同时定义一个比刚刚多了tdm和vocabulary的bunch,即
tfidfspace = Bunch(target_name=bunch.target_name, label=bunch.label,
filenames=bunch.filenames, tdm=[],vocabulary={})
盲猜tdm是term-document matrix
2、str(tfidfspace),输出第一个辅助文件b①
3、# 初始化向量空间
vectorizer = TfidfVectorizer(stop_words=stopWordList, sublinear_tf=True, max_df=0.5)
4、transformer = TfidfTransformer() # 该类会统计每个词语的TF-IDF权值
5、# 文本转化为词频矩阵,单独保存字典文件
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
tfidfspace_arr = str(vectorizer.fit_transform(bunch.contents))
saveFile(tfidfspace_arr_path, tfidfspace_arr)
前两行乍一看是一样的,其实是生成了辅助文件b②
6、tfidfspace.vocabulary = vectorizer.vocabulary_ # 获取词汇
tfidfspace_vocabulary = str(vectorizer.vocabulary_)
saveFile(tfidfspace_vocabulary_path, tfidfspace_vocabulary)
前两行乍一看也是一样的,其实是生成了辅助文件b⑤
7、writeBunch 生成了文件a①,tfidfspace.dat,bunch是齐的
借一篇文章了解一下TfidfVectorizer()和TfidfTransformer()
原文链接:https://blog.csdn.net/TinToKAO/java/article/details/104593326
CountVectorizer()
输入:文档 corpus
输出:文档中各个单词的词频TF(即每个单词在文档中出现的次数)
TfidfTransformer()
输入:词频TF
输出:词频逆反文档频率TF-IDF(即词频TF与逆反文档频率IDF的乘积,IDF的标准计算公式为 :idf=log[n/(1+df)],其中n为文档总数,df为含有所计算单词的文档数量,df越小,idf值越大,也就是说出现频率越小的单词意义越大)
TfidfVectorizer()
输入:文档
输出:该文档的词频逆反文档频率TF-IDF
三个函数的关系:
TfidfVectorizer().fit_transform(corpus) = TfidfTransformer().fit_transform(CountVectorizer().fit_transform(corpus))
getTestSpace(a②, a①, ④, a③, b⑦, b⑧, b⑥)(构建测试集TF-IDF向量空间)
1、读测试集分词后bunch,同时定义一个比刚刚多了tdm和vocabulary的bunch,即
testSpace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[],vocabulary={})
2、str(testSpace),输出辅助文件b⑦
3、# 导入训练集的词袋
trainbunch = readBunch(trainSpacePath)
4、# 使用TfidfVectorizer初始化向量空间模型 使用训练集词袋向量
vectorizer = TfidfVectorizer(stop_words=stopWordList, sublinear_tf=True, max_df=0.5,
vocabulary=trainbunch.vocabulary)
5、transformer = TfidfTransformer() # 该类会统计每个词语的TF-IDF权值
6、# 文本转化为词频矩阵,单独保存字典文件
testSpace.tdm = vectorizer.fit_transform(bunch.contents)
testSpace_arr = str(testSpace.tdm)
saveFile(testSpace_arr_path, testSpace_arr)
前两行乍一看是一样的,其实是生成了辅助文件b⑧
7、testSpace.vocabulary = trainbunch.vocabulary
trainbunch_vocabulary = str(trainbunch.vocabulary)
saveFile(trainbunch_vocabulary_path, trainbunch_vocabulary)
前两行乍一看也是一样的,其实是生成了辅助文件b⑥,其内容跟训练集的vocabulary是一样的,就是因为它的词袋就是训练集的
8、writeBunch 生成了文件a③,testspace.dat,bunch也是齐的
bayesAlgorithm(a①, a③ ,b③, b④, b⑨, b⑩)
1、读出两个bunch
trainSet = readBunch(trainPath)
testSet = readBunch(testPath)
2、多项式贝叶斯的classifier
clf = MultinomialNB(alpha=0.001).fit(trainSet.tdm, trainSet.label)
# alpha:0.001 alpha 越小,迭代次数越多,精度越高
# print(shape(trainSet.tdm)) #输出单词矩阵的类型
# print(shape(testSet.tdm))
3、让你看看b③和b④
tfidfspace_out_arr = str(trainSet.tdm) # 处理
tfidfspace_out_word = str(trainSet)
saveFile(tfidfspace_out_arr_path, tfidfspace_out_arr) # 矩阵形式的train_set.txt
saveFile(tfidfspace_out_word_path, tfidfspace_out_word) # 文本形式的train_set.txt
4、让你看看b⑨, b⑩
testspace_out_arr = str(testSet)
testspace_out_word = str(testSet.label)
saveFile(testspace_out_arr_path, testspace_out_arr)
saveFile(testspace_out_word_apth, testspace_out_word)
5、用分类器预测,并列出错误预测项
predicted = clf.predict(testSet.tdm)
total = len(predicted)
rate = 0
for flabel, fileName, expct_cate in zip(testSet.label, testSet.filenames, predicted):
if flabel != expct_cate:
rate += 1
print(fileName, ":实际类别:", flabel, "-->预测类别:", expct_cate)
print("erroe rate:", float(rate) * 100 / float(total), "%")
有中间文件的全部代码
#!D:/workplace/python # -*- coding: utf-8 -*- # @File : TFIDF_naive_bayes_wy.py # @Author: WangYe # @Date : 2019/5/29 # @Software: PyCharm # 机器学习之文本分类(附带训练集+数据集+所有代码) # 博客链接:https://blog.csdn.net/qq_28626909/article/details/80382029 import jieba from numpy import * import pickle # 持久化 import os from sklearn.feature_extraction.text import TfidfTransformer # TF-IDF向量转换类 from sklearn.feature_extraction.text import TfidfVectorizer # TF_IDF向量生成类 from sklearn.datasets.base import Bunch from sklearn.naive_bayes import MultinomialNB # 多项式贝叶斯算法 def readFile(path): with open(path, 'r', errors='ignore') as file: # 文档中编码有些问题,所有用errors过滤错误 content = file.read() file.close() return content def saveFile(path, result): with open(path, 'w', errors='ignore') as file: file.write(result) file.close() def segText(inputPath, resultPath): fatherLists = os.listdir(inputPath) # 主目录 for eachDir in fatherLists: # 遍历主目录中各个文件夹 eachPath = inputPath + eachDir + "/" # 保存主目录中每个文件夹目录,便于遍历二级文件 each_resultPath = resultPath + eachDir + "/" # 分词结果文件存入的目录 if not os.path.exists(each_resultPath): os.makedirs(each_resultPath) childLists = os.listdir(eachPath) # 获取每个文件夹中的各个文件 for eachFile in childLists: # 遍历每个文件夹中的子文件 eachPathFile = eachPath + eachFile # 获得每个文件路径 # print(eachFile) content = readFile(eachPathFile) # 调用上面函数读取内容 # content = str(content) result = (str(content)).replace("\r\n", "").strip() # 删除多余空行与空格 # result = content.replace("\r\n","").strip() cutResult = jieba.cut(result) # 默认方式分词,分词结果用空格隔开 saveFile(each_resultPath + eachFile, " ".join(cutResult)) # 调用上面函数保存文件 def bunchSave(inputFile, outputFile): catelist = os.listdir(inputFile) bunch = Bunch(target_name=[], label=[], filenames=[], contents=[]) bunch.target_name.extend(catelist) # 将类别保存到Bunch对象中 for eachDir in catelist: eachPath = inputFile + eachDir + "/" fileList = os.listdir(eachPath) for eachFile in fileList: # 二级目录中的每个子文件 fullName = eachPath + eachFile # 二级目录子文件全路径 bunch.label.append(eachDir) # 当前分类标签 bunch.filenames.append(fullName) # 保存当前文件的路径 bunch.contents.append(readFile(fullName).strip()) # 保存文件词向量 with open(outputFile, 'wb') as file_obj: # 持久化必须用二进制访问模式打开 pickle.dump(bunch, file_obj) # pickle.dump(obj, file, [,protocol])函数的功能:将obj对象序列化存入已经打开的file中。 # obj:想要序列化的obj对象。 # file:文件名称。 # protocol:序列化使用的协议。如果该项省略,则默认为0。如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本 def readBunch(path): with open(path, 'rb') as file: bunch = pickle.load(file) # pickle.load(file) # 函数的功能:将file中的对象序列化读出。 return bunch def writeBunch(path, bunchFile): with open(path, 'wb') as file: pickle.dump(bunchFile, file) def getStopWord(inputFile): stopWordList = readFile(inputFile).splitlines() return stopWordList def getTFIDFMat(inputPath, stopWordList, outputPath, tftfidfspace_path,tfidfspace_arr_path,tfidfspace_vocabulary_path): # 求得TF-IDF向量 bunch = readBunch(inputPath) tfidfspace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[], vocabulary={}) '''读取tfidfspace''' tfidfspace_out = str(tfidfspace) saveFile(tftfidfspace_path, tfidfspace_out) # 初始化向量空间 vectorizer = TfidfVectorizer(stop_words=stopWordList, sublinear_tf=True, max_df=0.5) transformer = TfidfTransformer() # 该类会统计每个词语的TF-IDF权值 # 文本转化为词频矩阵,单独保存字典文件 tfidfspace.tdm = vectorizer.fit_transform(bunch.contents) tfidfspace_arr = str(vectorizer.fit_transform(bunch.contents)) saveFile(tfidfspace_arr_path, tfidfspace_arr) tfidfspace.vocabulary = vectorizer.vocabulary_ # 获取词汇 tfidfspace_vocabulary = str(vectorizer.vocabulary_) saveFile(tfidfspace_vocabulary_path, tfidfspace_vocabulary) '''over''' writeBunch(outputPath, tfidfspace) def getTestSpace(testSetPath, trainSpacePath, stopWordList, testSpacePath, testSpace_path,testSpace_arr_path,trainbunch_vocabulary_path): bunch = readBunch(testSetPath) # 构建测试集TF-IDF向量空间 testSpace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[], vocabulary={}) ''' 读取testSpace ''' testSpace_out = str(testSpace) saveFile(testSpace_path, testSpace_out) # 导入训练集的词袋 trainbunch = readBunch(trainSpacePath) # 使用TfidfVectorizer初始化向量空间模型 使用训练集词袋向量 vectorizer = TfidfVectorizer(stop_words=stopWordList, sublinear_tf=True, max_df=0.5, vocabulary=trainbunch.vocabulary) transformer = TfidfTransformer() testSpace.tdm = vectorizer.fit_transform(bunch.contents) testSpace.vocabulary = trainbunch.vocabulary testSpace_arr = str(testSpace.tdm) trainbunch_vocabulary = str(trainbunch.vocabulary) saveFile(testSpace_arr_path, testSpace_arr) saveFile(trainbunch_vocabulary_path, trainbunch_vocabulary) # 持久化 writeBunch(testSpacePath, testSpace) def bayesAlgorithm(trainPath, testPath,tfidfspace_out_arr_path, tfidfspace_out_word_path,testspace_out_arr_path, testspace_out_word_apth): trainSet = readBunch(trainPath) testSet = readBunch(testPath) clf = MultinomialNB(alpha=0.001).fit(trainSet.tdm, trainSet.label) # alpha:0.001 alpha 越小,迭代次数越多,精度越高 # print(shape(trainSet.tdm)) #输出单词矩阵的类型 # print(shape(testSet.tdm)) '''处理bat文件''' tfidfspace_out_arr = str(trainSet.tdm) # 处理 tfidfspace_out_word = str(trainSet) saveFile(tfidfspace_out_arr_path, tfidfspace_out_arr) # 矩阵形式的train_set.txt saveFile(tfidfspace_out_word_path, tfidfspace_out_word) # 文本形式的train_set.txt testspace_out_arr = str(testSet) testspace_out_word = str(testSet.label) saveFile(testspace_out_arr_path, testspace_out_arr) saveFile(testspace_out_word_apth, testspace_out_word) '''处理结束''' predicted = clf.predict(testSet.tdm) total = len(predicted) rate = 0 for flabel, fileName, expct_cate in zip(testSet.label, testSet.filenames, predicted): if flabel != expct_cate: rate += 1 print(fileName, ":实际类别:", flabel, "-->预测类别:", expct_cate) print("erroe rate:", float(rate) * 100 / float(total), "%") # 分词,第一个是分词输入,第二个参数是结果保存的路径 # if __name__ == '__main__': datapath = "./data/" #原始数据路径 stopWord_path = "./stop/stopword.txt"#停用词路径 test_path = "./test/" #测试集路径 ''' 以上三个文件路径是已存在的文件路径,下面的文件是运行代码之后生成的文件路径 dat文件是为了读取方便做的,txt文件是为了给大家展示做的,所以想查看分词,词频矩阵 词向量的详细信息请查看txt文件,dat文件是通过正常方式打不开的 ''' test_split_dat_path = "./test_set.dat" #测试集分词bat文件路径 testspace_dat_path ="./testspace.dat" #测试集输出空间矩阵dat文件 train_dat_path = "./train_set.dat" # 读取分词数据之后的词向量并保存为二进制文件 tfidfspace_dat_path = "./tfidfspace.dat" #tf-idf词频空间向量的dat文件 ''' 以上四个为dat文件路径,是为了存储信息做的,不要打开 ''' test_split_path = './split/test_split/' #测试集分词路径 split_datapath = "./split/split_data/" # 对原始数据分词之后的数据路径 ''' 以上两个路径是分词之后的文件路径,大家可以生成之后自行打开查阅学习 ''' tfidfspace_path = "./tfidfspace.txt" # 将TF-IDF词向量保存为txt,方便查看 tfidfspace_arr_path = "./tfidfspace_arr.txt" # 将TF-IDF词频矩阵保存为txt,方便查看 tfidfspace_vocabulary_path = "./tfidfspace_vocabulary.txt" # 将分词的词汇统计信息保存为txt,方便查看 testSpace_path = "./testSpace.txt" #测试集分词信息 testSpace_arr_path = "./testSpace_arr.txt" #测试集词频矩阵信息 trainbunch_vocabulary_path = "./trainbunch_vocabulary.txt" #所有分词词频信息 tfidfspace_out_arr_path = "./tfidfspace_out_arr.txt" #tfidf输出矩阵信息 tfidfspace_out_word_path = "./tfidfspace_out_word.txt" #单词形式的txt testspace_out_arr_path = "./testspace_out_arr.txt" #测试集输出矩阵信息 testspace_out_word_apth ="./testspace_out_word.txt" #测试界单词信息 ''' 以上10个文件是dat文件转化为txt文件,大家可以查询信息,这是NLP(自然语言处理)非常珍贵的资源 ''' #输入训练集 segText(datapath,#读入数据 split_datapath)#输出分词结果 bunchSave(split_datapath,#读入分词结果 train_dat_path) # 输出分词向量 stopWordList = getStopWord(stopWord_path) # 获取停用词表 getTFIDFMat(train_dat_path, #读入分词的词向量 stopWordList, #获取停用词表 tfidfspace_dat_path, #tf-idf词频空间向量的dat文件 tfidfspace_path, #输出词频信息txt文件 tfidfspace_arr_path,#输出词频矩阵txt文件 tfidfspace_vocabulary_path) #输出单词txt文件 ''' 测试集的每个函数的参数信息请对照上面的各个信息,是基本相同的 ''' #输入测试集 segText(test_path, test_split_path) # 对测试集读入文件,输出分词结果 bunchSave(test_split_path, test_split_dat_path) # getTestSpace(test_split_dat_path, tfidfspace_dat_path, stopWordList, testspace_dat_path, testSpace_path, testSpace_arr_path, trainbunch_vocabulary_path)# 输入分词文件,停用词,词向量,输出特征空间(txt,dat文件都有) bayesAlgorithm(tfidfspace_dat_path, testspace_dat_path, tfidfspace_out_arr_path, tfidfspace_out_word_path, testspace_out_arr_path, testspace_out_word_apth)
要改路径且没有辅助文件的全部代码
#!D:/workplace/python # -*- coding: utf-8 -*- # @File : homework3.py # @Author: WangYe # @Date : 2018/4/22 # @Software: PyCharm # 微博文字的性别识别 import jieba import os import pickle # 持久化 from numpy import * from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfTransformer # TF-IDF向量转换类 from sklearn.feature_extraction.text import TfidfVectorizer # TF_IDF向量生成类 from sklearn.datasets.base import Bunch from sklearn.naive_bayes import MultinomialNB # 多项式贝叶斯算法 def readFile(path): with open(path, 'r', errors='ignore') as file: # 文档中编码有些问题,所有用errors过滤错误 content = file.read() return content def saveFile(path, result): with open(path, 'w', errors='ignore') as file: file.write(result) def segText(inputPath, resultPath): fatherLists = os.listdir(inputPath) # 主目录 for eachDir in fatherLists: # 遍历主目录中各个文件夹 eachPath = inputPath + eachDir + "/" # 保存主目录中每个文件夹目录,便于遍历二级文件 each_resultPath = resultPath + eachDir + "/" # 分词结果文件存入的目录 if not os.path.exists(each_resultPath): os.makedirs(each_resultPath) childLists = os.listdir(eachPath) # 获取每个文件夹中的各个文件 for eachFile in childLists: # 遍历每个文件夹中的子文件 eachPathFile = eachPath + eachFile # 获得每个文件路径 # print(eachFile) content = readFile(eachPathFile) # 调用上面函数读取内容 # content = str(content) result = (str(content)).replace("\r\n", "").strip() # 删除多余空行与空格 # result = content.replace("\r\n","").strip() cutResult = jieba.cut(result) # 默认方式分词,分词结果用空格隔开 saveFile(each_resultPath + eachFile, " ".join(cutResult)) # 调用上面函数保存文件 def bunchSave(inputFile, outputFile): catelist = os.listdir(inputFile) bunch = Bunch(target_name=[], label=[], filenames=[], contents=[]) bunch.target_name.extend(catelist) # 将类别保存到Bunch对象中 for eachDir in catelist: eachPath = inputFile + eachDir + "/" fileList = os.listdir(eachPath) for eachFile in fileList: # 二级目录中的每个子文件 fullName = eachPath + eachFile # 二级目录子文件全路径 bunch.label.append(eachDir) # 当前分类标签 bunch.filenames.append(fullName) # 保存当前文件的路径 bunch.contents.append(readFile(fullName).strip()) # 保存文件词向量 with open(outputFile, 'wb') as file_obj: # 持久化必须用二进制访问模式打开 pickle.dump(bunch, file_obj) #pickle.dump(obj, file, [,protocol])函数的功能:将obj对象序列化存入已经打开的file中。 #obj:想要序列化的obj对象。 #file:文件名称。 #protocol:序列化使用的协议。如果该项省略,则默认为0。如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本 def readBunch(path): with open(path, 'rb') as file: bunch = pickle.load(file) #pickle.load(file) #函数的功能:将file中的对象序列化读出。 return bunch def writeBunch(path, bunchFile): with open(path, 'wb') as file: pickle.dump(bunchFile, file) def getStopWord(inputFile): stopWordList = readFile(inputFile).splitlines() return stopWordList def getTFIDFMat(inputPath, stopWordList, outputPath): # 求得TF-IDF向量 bunch = readBunch(inputPath) tfidfspace = Bunch(target_name=bunch.target_name,label=bunch.label, filenames=bunch.filenames, tdm=[], vocabulary={}) # 初始化向量空间 vectorizer = TfidfVectorizer(stop_words=stopWordList, sublinear_tf=True, max_df=0.5) transformer = TfidfTransformer() # 该类会统计每个词语的TF-IDF权值 # 文本转化为词频矩阵,单独保存字典文件 tfidfspace.tdm = vectorizer.fit_transform(bunch.contents) tfidfspace.vocabulary = vectorizer.vocabulary_ #获取词汇 writeBunch(outputPath, tfidfspace) def getTestSpace(testSetPath, trainSpacePath, stopWordList, testSpacePath): bunch = readBunch(testSetPath) # 构建测试集TF-IDF向量空间 testSpace = Bunch(target_name=bunch.target_name, label=bunch.label, filenames=bunch.filenames, tdm=[], vocabulary={}) # 导入训练集的词袋 trainbunch = readBunch(trainSpacePath) # 使用TfidfVectorizer初始化向量空间模型 使用训练集词袋向量 vectorizer = TfidfVectorizer(stop_words=stopWordList, sublinear_tf=True, max_df=0.5, vocabulary=trainbunch.vocabulary) transformer = TfidfTransformer() testSpace.tdm = vectorizer.fit_transform(bunch.contents) testSpace.vocabulary = trainbunch.vocabulary # 持久化 writeBunch(testSpacePath, testSpace) def bayesAlgorithm(trainPath, testPath): trainSet = readBunch(trainPath) testSet = readBunch(testPath) clf = MultinomialNB(alpha=0.001).fit(trainSet.tdm, trainSet.label) #alpha:0.001 alpha 越小,迭代次数越多,精度越高 #print(shape(trainSet.tdm)) #输出单词矩阵的类型 #print(shape(testSet.tdm)) predicted = clf.predict(testSet.tdm) total = len(predicted) rate = 0 for flabel, fileName, expct_cate in zip(testSet.label, testSet.filenames, predicted): if flabel != expct_cate: rate += 1 print(fileName, ":实际类别:", flabel, "-->预测类别:", expct_cate) print("erroe rate:", float(rate) * 100 / float(total), "%") # 分词,第一个是分词输入,第二个参数是结果保存的路径 segText("C:/Users/wy/Desktop/data/", "C:/Users/wy/Desktop/segResult/") bunchSave("C:/Users/wy/Desktop/segResult/", "C:/Users/wy/Desktop/train_set.dat") # 输入分词,输出分词向量 stopWordList = getStopWord("C:/Users/wy/Desktop/stop/stopword.txt") # 获取停用词 getTFIDFMat("C:/Users/wy/Desktop/train_set.dat", stopWordList, "C:/Users/wy/Desktop/tfidfspace.dat") # 输入词向量,输出特征空间 # 训练集 segText("C:/Users/wy/Desktop/test1/", "C:/Users/wy/Desktop/test_segResult/") # 分词 bunchSave("C:/Users/wy/Desktop/test_segResult/", "C:/Users/wy/Desktop/test_set.dat") getTestSpace("C:/Users/wy/Desktop/test_set.dat", "C:/Users/wy/Desktop/tfidfspace.dat", stopWordList, "C:/Users/wy/Desktop/testspace.dat") bayesAlgorithm("C:/Users/wy/Desktop/tfidfspace.dat", "C:/Users/wy/Desktop/testspace.dat")
------------------------------------------这是一条分割线2020-05-12------------------------------------------
PS:所有与这个数据集结构相同的数据集,都可以套进来用这个代码分类
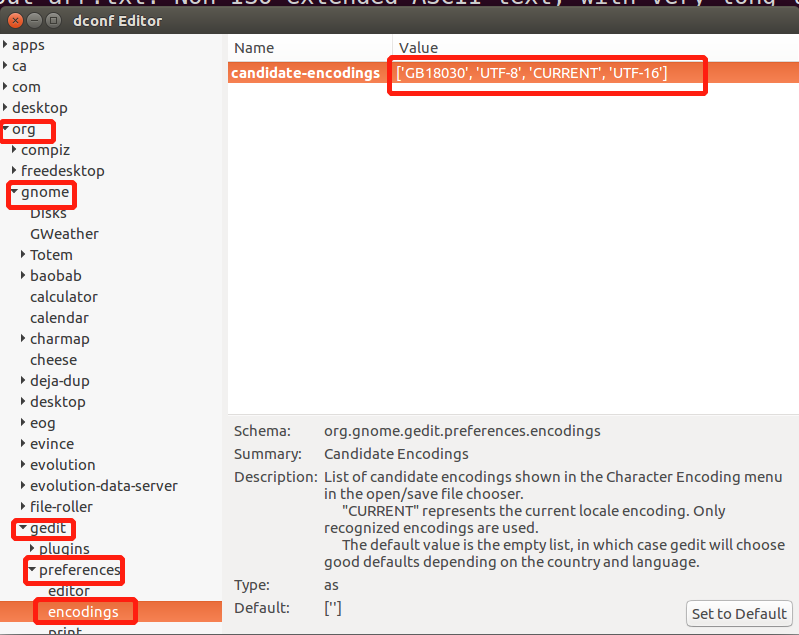
我是用ubantu的,原作者是用windows的,结果就发生了一件最烦人的事情,转码问题,大致意思就是windows上用的GBK编码,放到ubantu上默认UTF-8就行不通了,所以产生一个乌龙就是,我jieba分词后就是乱码了,乱码后再转成tfidf矩阵或者打开vocabulary的时候都是奇奇怪怪的英文和数字,错误率更是高达43%,作者只有9%。我意识到不对后一直找百度,都是叫我改auto-detected的值,但是到最后还是不能完全解决问题,所以不能贴上完美解决方案。我最后是改成了这样,然后代码也有所修改。
命令dconf-editor,现在改完以后是['GB18030', 'UTF-8', 'CURRENT', 'UTF-16']


 浙公网安备 33010602011771号
浙公网安备 33010602011771号