OCR识别表格中的参数及参数值
一、需求
识别固定表格中的文字,输出表格中的参数字典
二、整体思路
- 找到一张含有表格的图片,利用mac自带的预览工具分析出图片每个单元格的对角线坐标,
- 使用程序根据图片文件和对角线坐标数组,分割图片为很多个小图片,
- 采用tesseract库识别单个单元格中的文字,并将识别出来的所有文字输出到同一个文本文件中。
三、开发环境准备
Mac上安装VSCode,VSCode中安装python扩展,使用venv这个python自带的虚拟环境,建立测试venv工作区后利用.venv/bin/pip3安装tesseract和pillow类库
.venv/bin/pip3 install pillow .venv/bin/pip3 install tesseract
.venv/bin/pip3 install pytesseract
.venv/bin/pip3 install opencv-python
.venv/bin/pip3 install numpy
.venv/bin/pip3 install scikit-image
四、开发步骤
建立根目录及相关功能目录,并使用VSCode打开根目录
编写图片分割程序
1 import os 2 from PIL import Image 3 4 img = "imgs2txt/imgs/合格证.jpg" 5 pix_a = [(20,3,428,20), (428,3,700,20), 6 (20,20+1,428,20*2),(428,20+1,700,20*2)] 7 8 def cut_by_pix_a(img, xys): 9 number_of_pic = len(xys) 10 image = Image.open(img) 11 print(f'这个图像是{image.width} x {image.height}') 12 name1, name2 = os.path.dirname(img) + "/splits/" ,os.path.basename(img).split(".")[-2]+"_cut_" 13 for p in xys: 14 name3 = name1+name2+str(p)+".jpg" 15 im2 = image.crop(p) 16 im2.save(name3) 17 print(f"一共完成了{len(xys)}个文件.") 18 19 cut_by_pix_a(img, pix_a)
编写图片增强处理器
分割后发现图片非常模糊识别时,汉子无法识别出来,所以编写图片锐化程序,提高图片识别精度
import cv2 import numpy as np from skimage import filters def preprocess_image_old(img_path): img = cv2.imread(img_path) # 1.灰度化 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 2.去操(中值滤波) denoised = cv2.medianBlur(gray, 3) # 3.自适应二值化 binary = cv2.adaptiveThreshold( denoised, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2 ) # 4.锐化处理(拉普拉斯算子) kernel = np.array([[0, -1, 0], [-1, 5,-1], [0, -1, 0]]) sharpened = cv2.filter2D(binary, -1, kernel) # 5.形态学操作(去除小噪点) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2,2)) cleaned = cv2.morphologyEx(sharpened, cv2.MORPH_OPEN, kernel) return cleaned def preprocess_image(img_path): img = cv2.imread(img_path) # 1.灰度化 # gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 1.去操(中值滤波) denoised = cv2.medianBlur(img, 3) # 2.自适应二值化 binary = cv2.adaptiveThreshold( denoised, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2 ) # 3.锐化处理(拉普拉斯算子) kernel = np.array([[0, -1, 0], [-1, 5,-1], [0, -1, 0]]) sharpened = cv2.filter2D(binary, -1, kernel) # 5.形态学操作(去除小噪点) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2,2)) cleaned = cv2.morphologyEx(sharpened, cv2.MORPH_OPEN, kernel) return cleaned img1_path = 'imgs2txt/imgs/splits/合格证_cut_(20, 3, 106, 20).jpg' r = preprocess_image(img1_path) cv2.imwrite('imgs2txt/imgs/cleaned/合格证_cut_(20, 3, 106, 20).jpg', r) print(r)
编写单个图片识别程序
import pytesseract from PIL import Image img1_path = 'imgs2txt/imgs/splits/合格证_cut_(20, 3, 106, 20).jpg' def basic_ocr(img_path): img = Image.open(img_path) text = pytesseract.image_to_string(img, lang='chi_sim') return text def advanced_ocr(img_path): custom_config = r'--oem 3 --psm 6 -c tessedit_char_whitelist=0123456789' text = pytesseract.image_to_string( Image.open(img_path), lang='chi_sim', config=custom_config ) return text print("基本识别结果" + basic_ocr(img1_path)) print("高级识别结果" + advanced_ocr(img1_path))
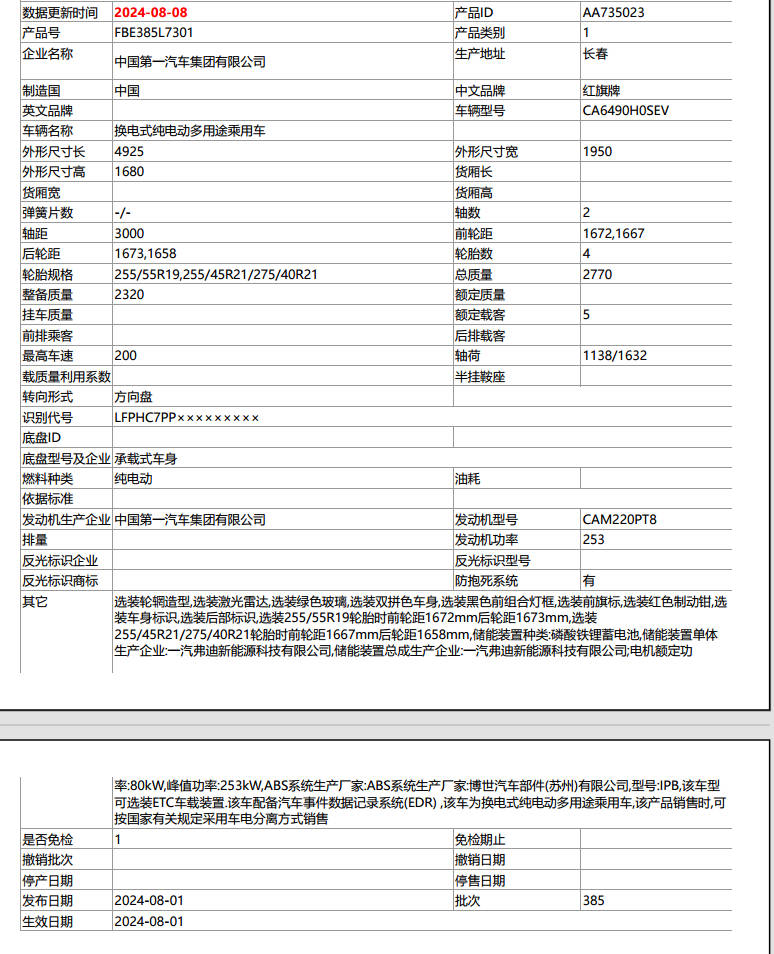
待处理的图片
......未完待续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号