集成学习中的 stacking 以及python实现
集成学习
Ensemble learning 中文名叫做集成学习,它并不是一个单独的机器学习算法,而是将很多的机器学习算法结合在一起,我们把组成集成学习的算法叫做“个体学习器”。在集成学习器当中,个体学习器都相同,那么这些个体学习器可以叫做“基学习器”。
个体学习器组合在一起形成的集成学习,常常能够使得泛化性能提高,这对于“弱学习器”的提高尤为明显。弱学习器指的是比随机猜想要好一些的学习器。
在进行集成学习的时候,我们希望我们的基学习器应该是好而不同,这个思想在后面经常体现。 “好”就是说,你的基学习器不能太差,“不同”就是各个学习器尽量有差异。
集成学习有两个分类,一个是个体学习器存在强依赖关系、必须串行生成的序列化方法,以Boosting为代表。另外一种是个体学习器不存在强依赖关系、可同时生成的并行化方法,以Bagging和随机森林(Random Forest)为代表。
Stacking 的基本思想
将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。
上面说的投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。
在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
我们贴一张周志华老师《机器学习》一张图来说一下stacking学习算法。

过程1-3 是训练出来个体学习器,也就是初级学习器。
过程5-9是 使用训练出来的个体学习器来得预测的结果,这个预测的结果当做次级学习器的训练集。
过程11 是用初级学习器预测的结果训练出次级学习器,得到我们最后训练的模型。
如果想要预测一个数据的输出,只需要把这条数据用初级学习器预测,然后将预测后的结果用次级学习器预测便可。
Stacking的实现
最先想到的方法是这样的,
1:用数据集D来训练h1,h2,h3...,
2:用这些训练出来的初级学习器在数据集D上面进行预测得到次级训练集。
3:用次级训练集来训练次级学习器。
但是这样的实现是有很大的缺陷的。在原始数据集D上面训练的模型,然后用这些模型再D上面再进行预测得到的次级训练集肯定是非常好的。会出现过拟合的现象。
那么,我们换一种做法,我们用交叉验证的思想来实现stacking的模型,从这里拿来一张图
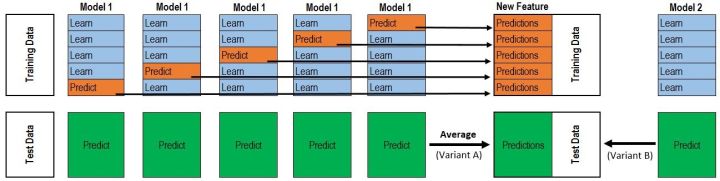
次级训练集的构成不是直接由模型在训练集D上面预测得到,而是使用交叉验证的方法,将训练集D分为k份,对于每一份,用剩余数据集训练模型,然后预测出这一份的结果。重复上面步骤,直到每一份都预测出来。这样就不会出现上面的过拟合这种情况。并且在构造次级训练集的过程当中,顺便把测试集的次级数据也给构造出来了。
对于我们所有的初级训练器,都要重复上面的步骤,才构造出来最终的次级训练集和次级测试集。
构造stacking方法
我们写一个stacking方法,下面是它的实现代码:
import numpy as np
from sklearn.model_selection import KFold
def get_stacking(clf, x_train, y_train, x_test, n_folds=10):
"""
这个函数是stacking的核心,使用交叉验证的方法得到次级训练集
x_train, y_train, x_test 的值应该为numpy里面的数组类型 numpy.ndarray .
如果输入为pandas的DataFrame类型则会把报错"""
train_num, test_num = x_train.shape[0], x_test.shape[0]
second_level_train_set = np.zeros((train_num,))
second_level_test_set = np.zeros((test_num,))
test_nfolds_sets = np.zeros((test_num, n_folds))
kf = KFold(n_splits=n_folds)
for i,(train_index, test_index) in enumerate(kf.split(x_train)):
x_tra, y_tra = x_train[train_index], y_train[train_index]
x_tst, y_tst = x_train[test_index], y_train[test_index]
clf.fit(x_tra, y_tra)
second_level_train_set[test_index] = clf.predict(x_tst)
test_nfolds_sets[:,i] = clf.predict(x_test)
second_level_test_set[:] = test_nfolds_sets.mean(axis=1)
return second_level_train_set, second_level_test_set
#我们这里使用5个分类算法,为了体现stacking的思想,就不加参数了
from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier,
GradientBoostingClassifier, ExtraTreesClassifier)
from sklearn.svm import SVC
rf_model = RandomForestClassifier()
adb_model = AdaBoostClassifier()
gdbc_model = GradientBoostingClassifier()
et_model = ExtraTreesClassifier()
svc_model = SVC()
#在这里我们使用train_test_split来人为的制造一些数据
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
train_x, test_x, train_y, test_y = train_test_split(iris.data, iris.target, test_size=0.2)
train_sets = []
test_sets = []
for clf in [rf_model, adb_model, gdbc_model, et_model, svc_model]:
train_set, test_set = get_stacking(clf, train_x, train_y, test_x)
train_sets.append(train_set)
test_sets.append(test_set)
meta_train = np.concatenate([result_set.reshape(-1,1) for result_set in train_sets], axis=1)
meta_test = np.concatenate([y_test_set.reshape(-1,1) for y_test_set in test_sets], axis=1)
#使用决策树作为我们的次级分类器
from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier()
dt_model.fit(meta_train, train_y)
df_predict = dt_model.predict(meta_test)
print(df_predict)
输出结果如下(因为是随机划分的,所以每次运行结果可能不一样):
[1 0 1 1 1 2 1 2 2 2 0 0 1 2 2 1 0 2 1 0 0 1 1 0 0 2 0 2 1 2]
构造stacking类
事实上还可以构造一个stacking的类,它拥有fit和predict方法
from sklearn.model_selection import KFold from sklearn.base import BaseEstimator, RegressorMixin, TransformerMixin, clone import numpy as np #对于分类问题可以使用 ClassifierMixin class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin): def __init__(self, base_models, meta_model, n_folds=5): self.base_models = base_models self.meta_model = meta_model self.n_folds = n_folds # 我们将原来的模型clone出来,并且进行实现fit功能 def fit(self, X, y): self.base_models_ = [list() for x in self.base_models] self.meta_model_ = clone(self.meta_model) kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156) #对于每个模型,使用交叉验证的方法来训练初级学习器,并且得到次级训练集 out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models))) for i, model in enumerate(self.base_models): for train_index, holdout_index in kfold.split(X, y): self.base_models_[i].append(instance) instance = clone(model) instance.fit(X[train_index], y[train_index]) y_pred = instance.predict(X[holdout_index]) out_of_fold_predictions[holdout_index, i] = y_pred # 使用次级训练集来训练次级学习器 self.meta_model_.fit(out_of_fold_predictions, y) return self #在上面的fit方法当中,我们已经将我们训练出来的初级学习器和次级学习器保存下来了 #predict的时候只需要用这些学习器构造我们的次级预测数据集并且进行预测就可以了 def predict(self, X): meta_features = np.column_stack([ np.column_stack([model.predict(X) for model in base_models]).mean(axis=1) for base_models in self.base_models_ ]) return self.meta_model_.predict(meta_features)
参考
Introduction to Ensembling/Stacking in Python

 浙公网安备 33010602011771号
浙公网安备 33010602011771号