速成正则表达式
1. 正则表达式(RE)
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
通俗来说就是 按照某种规则去匹配符合条件的字符串,并可以替换
2. 持续学习、练习
1.正则在线测试网站:https://regexr-cn.com/
2.正则练习:https://codejiaonang.com/
3. 入门
3.1 普通字符匹配
匹配所有为2020的数据
/2020/g

3.2 字符组
字符组:[]
允许匹配一组可能出现的字符。需要注意是匹配中括号内的单个字符
1.普通字符组
- 如果字符组后没有跟别的字符,则会选择所有字符组内出现过的字符
/[1234567890]/g
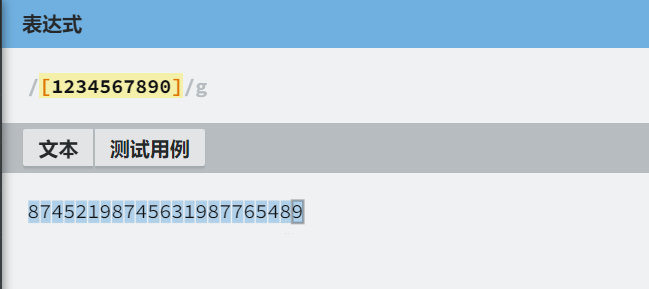
- 如果还有别的字符,则会选中中括号内的任意元素一次
/[jJ]ava/g

/[Rr]ub[ey]/g

2.区间
- 可以用
[ - ]来表示区间
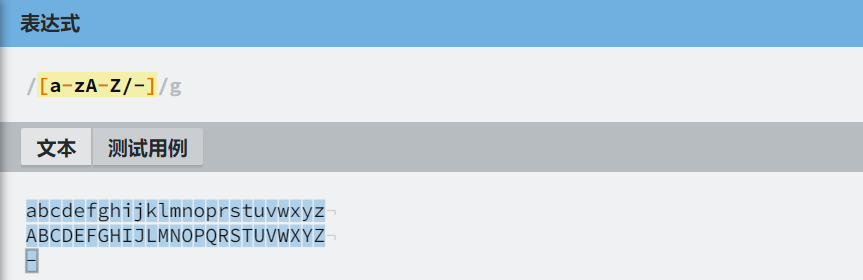
/[0-9]/g

/[a-zA-Z]/g

3.转义字符
- 在想匹配
-就要用到\转义字符
4. 取反
- 根据不会出现的字符定义字符组
[ ^ ]

3.3 快捷方式
1. 匹配数字和字母
-
\d匹配所有的数字 -
\w匹配所有的数字和大小写字母以及一些特殊字符
2. 匹配空白
\s匹配所有的空白 比如空格、换行、tab等
3. 单词边界
\b用来匹配单词的边界
4. 快捷方式取反
主要是将小写改为大写即可
-
\d匹配所有的非数字 -
\w匹配所有的非数字和大小写字母以及一些特殊字符
5. 匹配开头和结尾
^匹配开头$匹配结尾
6. 匹配任意字符
.表示匹配任何单个字符,如果有两个..就是任意两个字符,以此类推
注意,换行符不能匹配 、n
7. 可选字符
有时,我们可能想要匹配一个单词的不同写法,比如color和colour,或者honor与honour。
- 可以使用
?符号指定一个字符、字符组或其他基本单元可选,这意味着正则表达式引擎将会期望该字符出现零次或一次。
3.4 匹配多个数据
1. 重复次数
- 在一个字符后加上
{N}就可以表示它之前的字符串出现了N次
2. 重复区间
{M,N}表示重复的区间- 正则表达式默认是贪婪模式,就是会优先匹配多的边界,如
\d{3,4}当有4个数字的时候会优先匹配4个数字。这个时候就可以在表达式后面加上?来改为非贪婪模式
3. 开闭区间
-
开区间
{N,}表示N个到无数个 -
+等价于{1,} -
*等价于{0,}
4. 进阶
4.1 分组
分组可以从匹配的字符中捕获数据
1. 普通分组
- 使用
()进行分组
2. 或者条件
- 使用
|隔开
3. 非捕获分组
(?:表达式)代表使用分组功能,但是不捕获数据
4. 分组的回溯引用
- 正则表达式还提供了一种引用之前匹配分组的机制,有些时候,我们或许会寻找到一个子匹配,该匹配接下来会再次出现。

这里的\1就是代表回溯引用之前的第一个分组,计数是从1开始,以此类推

4.2 先行断言(环视)
先行断言就是从左往右看
1. 正向先行断言
怎么理解呢,不会匹配断言的内容,但是会匹配断言的条件
- 正向先行断言,从左往右看 表达式(?=表达式)

2. 反向先行断言
反向先行段断言,就是保证右边不能出现某字符
- 反向先行断言,(表达式?!表达式)
4.3 后行断言
先行断言就是从左往右看,后行断言就是从右往左看
1. 正向后行断言
- 要求左边出现的某字符 (?<=表达式)
2. 反向后行断言
- 保证左边不能出现某字符 (?<!表达式)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号