

《spark内核 架构设计与实现原理》 读书笔记5-----Shuffle
Shuffle是性能调优的一个重点,它的定义是:
计算过程中,要将某种具有共同特征的一类数据汇聚到一个计算节点上,例如在wordCount中要将相同的单词汇聚到同一个节点才能计算出单词的个数,这种把数据重新打乱然后汇聚到不同节点的过程就是shuffle。
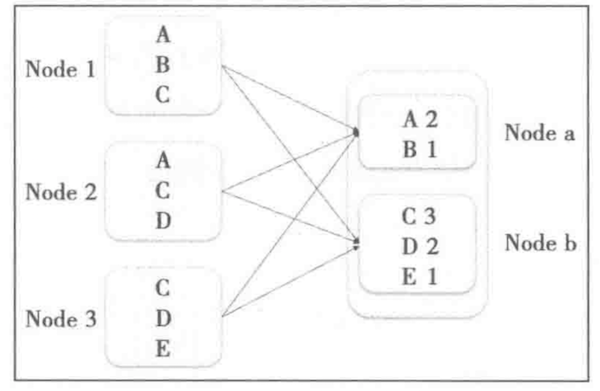
在shuffle过程中,要进行中间结果的持久化,因此shuffle过程是一个既耗费时间又耗费存储的过程。
1 Hash Based Shuffle
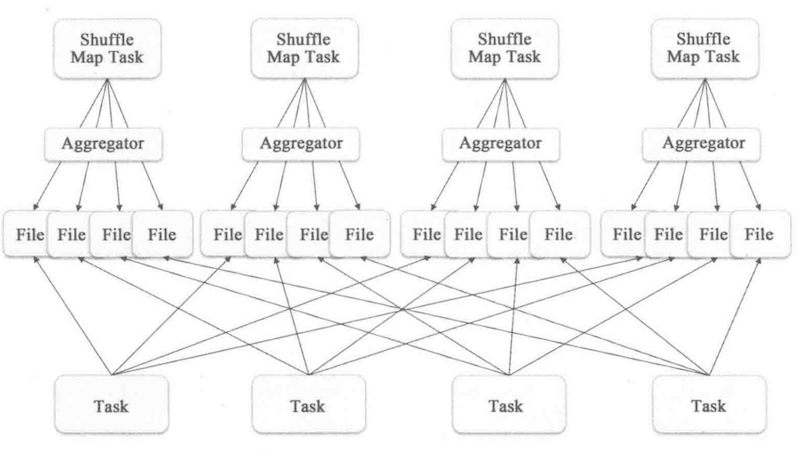
基于hash的shuffle,最大的问题是会生成过多的中间小文件,例如上图所示,上游的文件分片数量为4个,下游的文件分片数量也是4个,那么中间小文件数量就是4*4=16个
中间文件的命名格式为:shuffle + shuffleId + mapId + reduceId, mapId为上游task的id,reduceId为下游task处理数据的id。这种方式处理有一定的问题:
1. 小文件过多,每个文件的文件句柄占据一定的内存,累计起来占据太多内存
2.小文件过多,意味着有很多的随机读写,随机读写带来的性能开销也是很大的
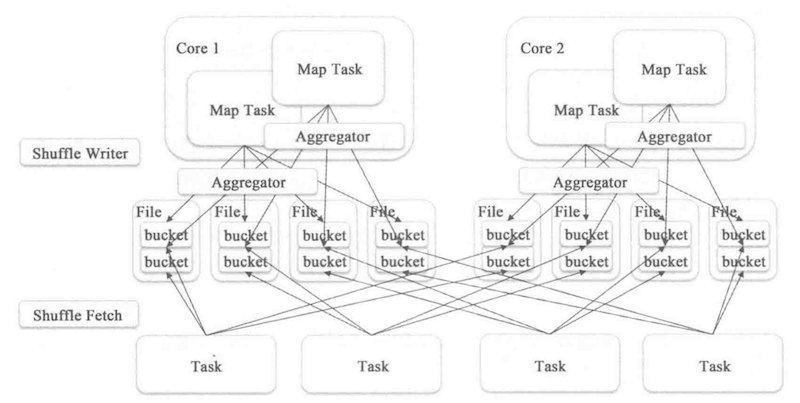
为了解决上述问题,spark引入了consolidate 的文件处理机制,这种机制是说由原来没个task创建一个下游文件改为每个core创建一个文件,对于运行在同一个core上的task,文件会被追加到之前task上的末尾
如果task的数量少于core的数量,那么这种方式能够显著减少中间文件的生成数量。
2 Sort Based Shuffle
如前面所所说,基于hash的shuffle性能受到小文件太多问题的困扰,sort based shuffle 基于排序的原理实现,每个shuffle task只产生出一个文件,同时产生一个index文件,作为文件的索引标记
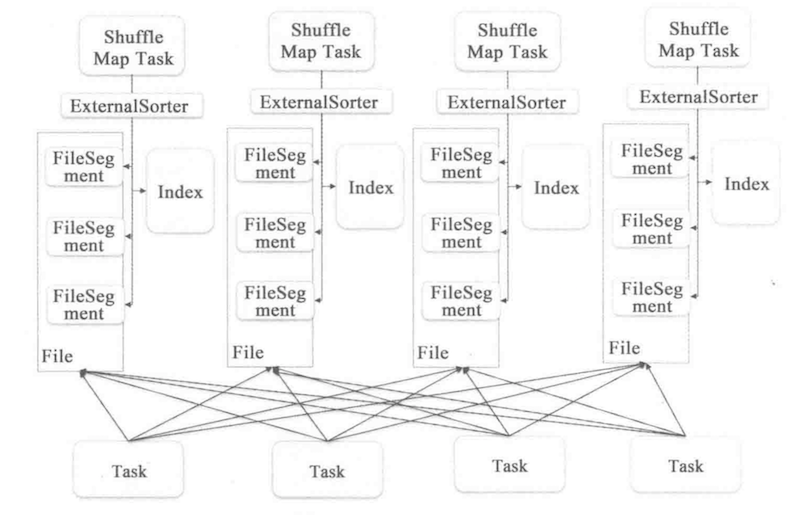
排序使用的字段为 partitionID,在这里的排序实际上是一个类似于桶排序的算法,以partitionID为key,value是一个list,包含了每个记录


 浙公网安备 33010602011771号
浙公网安备 33010602011771号