

《spark内核 架构设计与实现原理》 读书笔记4-----Scheduler
1 架构
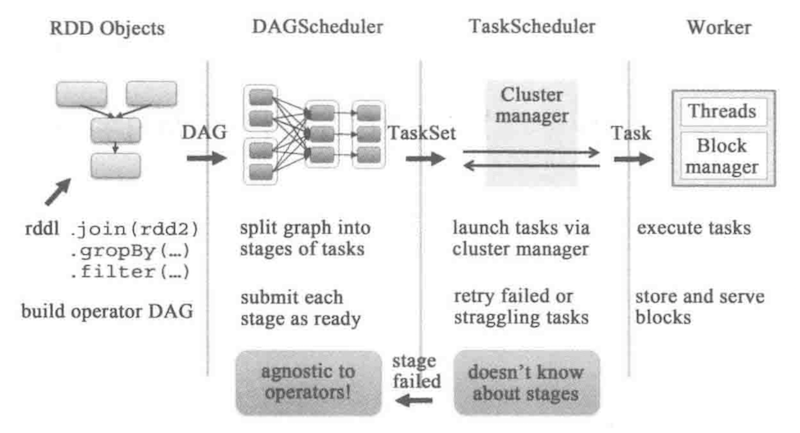
scheduler 模块主要包括两个类:DAGScheduler 和 TaskScheduler
DAGScheduler 的主要作用是根据job建立DAG,将DAG划分为不同的Stage,再将每个Stage划分成一组task,最后将task分配给TaskScheduler,
TaskScheduler 会将这些task分配到Executor上运行。任务调度的流程图如下图所示:
一个workNode上运行着一个Executor,一个Executor对应一个taskSet, 一个taskSet包含多个task,一个task对应一个partition进行运行。
2 DAGScheduler的详细实现
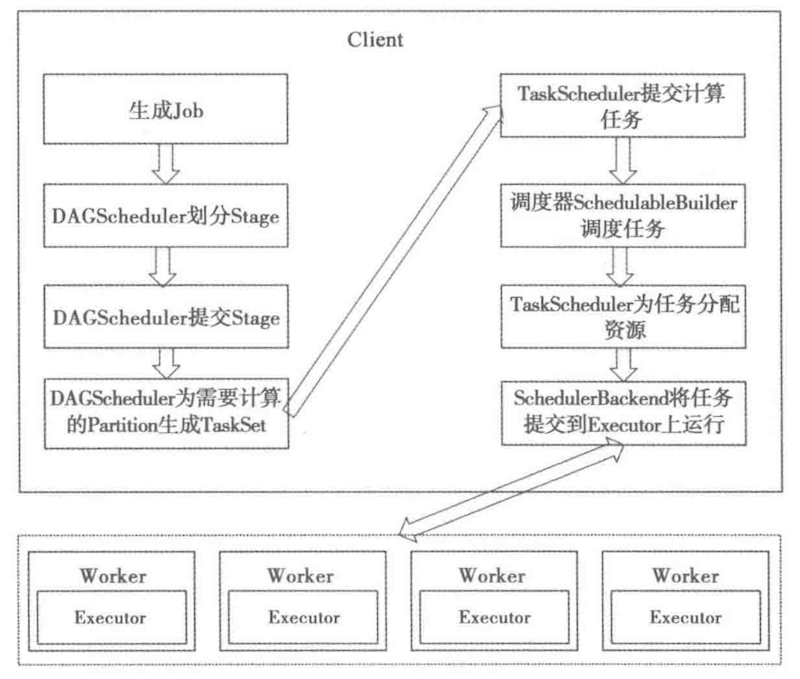
RDD的action函数会调用SparkContext中的runJob函数,然后调用DAGScheduler中的runJob函数,然后调用submitJob。
SparkContext.runJob -> DAGScheduler.runJob() -> DAGScheduler.submitJob()
submitJob 会生成一个JobID 和 一个JobWaiter, JobWaiter对job中的所有task进行监听,只有所有的task都运行成功才会返回Success。
Shuffle 逻辑的存在限制了rdd的并行执行,如果rdd1->rdd2的依赖是shuffle类型的,那么需要rdd1中所有partition都计算出来,才能开始shuffle计算下一步的rdd2.
宽依赖就是需要shuffle的依赖,窄依赖就是不需要shuffle的依赖,所以shuffle就成为了划分stage的依据。
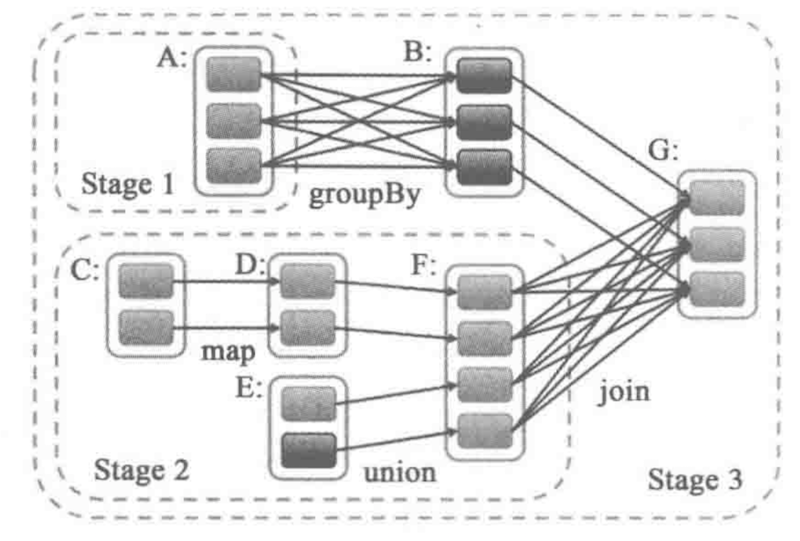
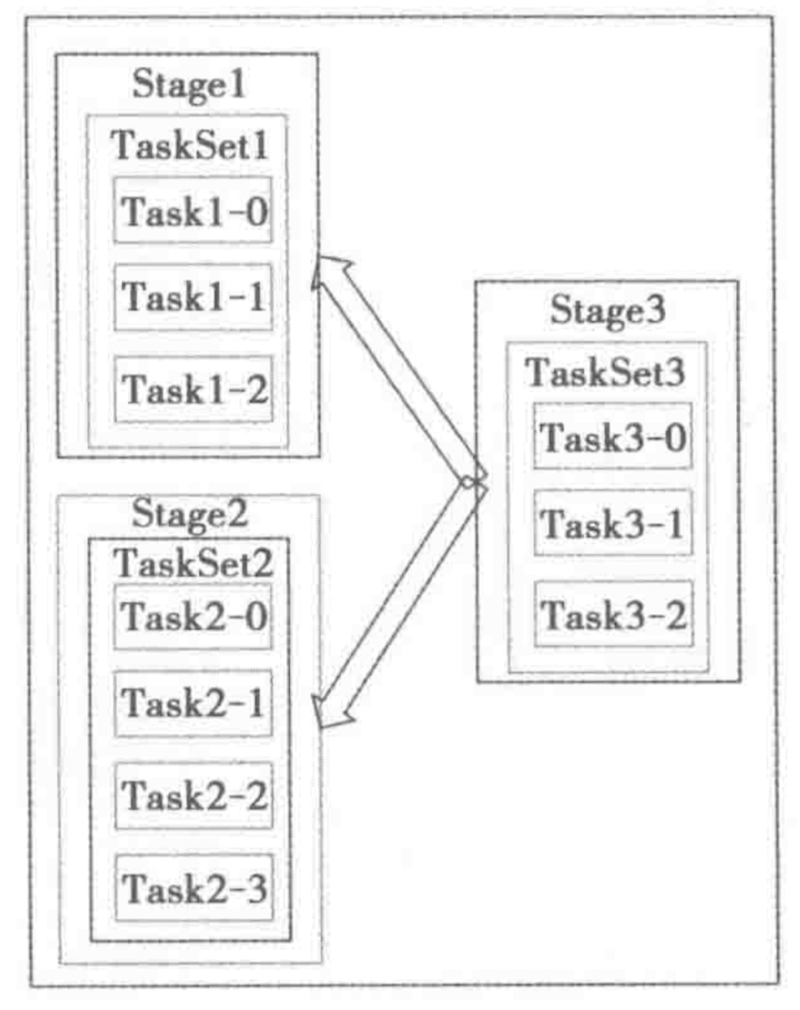
如上图中的rdd依赖图DAG所示,被划分成为3个stage, stage1 与stage2是可以并行的,stage1中的RDDA包含三个partitions,因此会产生3个ShuffleMapTask, 同样stage3中会产生3个ResultTask。
完成stage的划分以后,进行staging的提交:
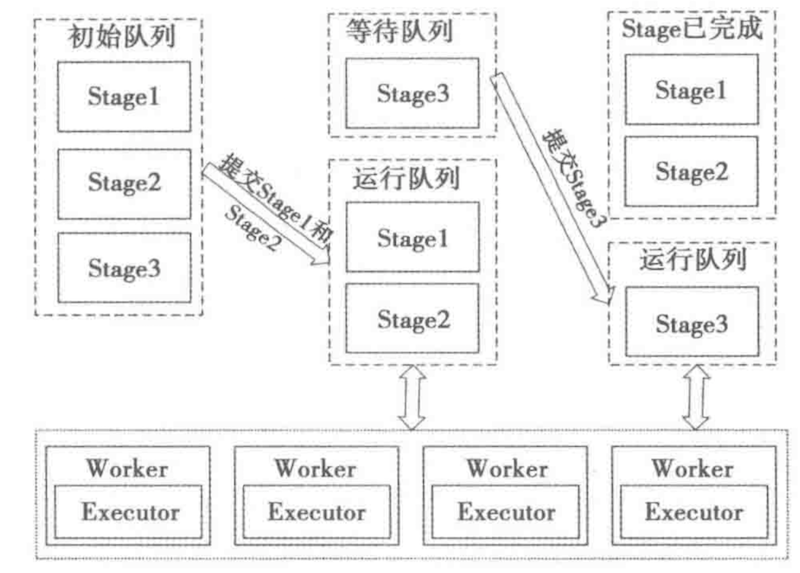
stage 划分好之后会将stage划分成不同的task,task会存储在taskSet中
3 taskScheduler的详细实现
taskScheduler 的主要任务是将DAGScheduloer分配给自己的task再分配给executor上去运行,在taskScheduler中会创建一个TaskSetManager,管理者采用就近的原则(locality aware)分配task到不同的executor
因为移动数据带来的网络通讯复杂度是非常大的,所以要让task去找数据,而不是固定task所在的机器去移动数据,TaskSetManager中定义了一个变量叫做SchedulableBuilder,该变量确定了task的调度原则,常用的调度原则有两种:FIFO 和 FAIR, 下面是两种调度逻辑的示意图:
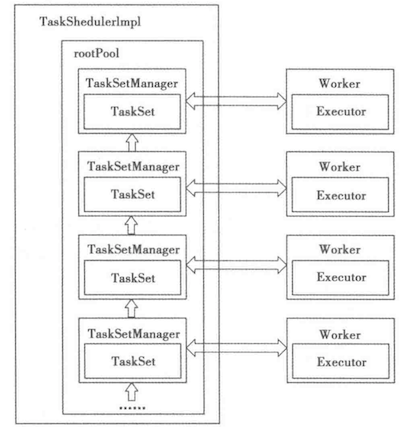
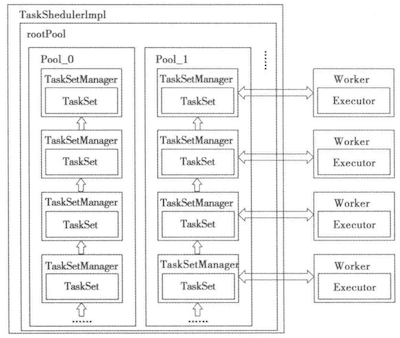
FIFO是按照JobID和StageID进行调度的, FAIR是按照task挂载的pool进行调度的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号