Selenium元素定位、WebDriver浏览器


1 from selenium import webdriver 2 import time 3 4 # 对webdriver进行实例化,指定测试用的浏览器 5 driver=webdriver.Chrome() 6 # 导航到被测试的网址 7 driver.get("https://www.baidu.com/") 8 #休眠 9 time.sleep(3) 10 #退出浏览器 11 driver.quit() 12 13 '''id元素属性''' 14 # driver=webdriver.Chrome() 15 # driver.get("https://www.baidu.com") 16 # #send_keys---→输入的意思 17 # driver.find_element_by_id("kw").send_keys("软件测试") 18 # time.sleep(2) 19 # driver.quit() 20 21 '''name元素属性''' 22 # driver=webdriver.Chrome() 23 # driver.get("https://www.baidu.com") 24 # #send_keys---→输入的意思 25 # driver.find_element_by_name("wd").send_keys("软件测试") 26 # time.sleep(3) 27 # driver.quit() 28 29 '''class_name元素属性''' 30 # driver=webdriver.Chrome() 31 # driver.get("https://www.baidu.com") 32 # #send_keys---→输入的意思 33 # driver.find_element_by_class_name("s_ipt").send_keys("软件测试") 34 # time.sleep(3) 35 # driver.quit() 36 37 '''css和xpath: 38 当你使用id、name、class_name都定位不到的时候,这个时候考虑使用css或xpath''' 39 40 '''xpath''' 41 # driver=webdriver.Chrome() 42 # driver.get("https://www.baidu.com") 43 # #send_keys---→输入的意思 44 # driver.find_element_by_xpath("/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input").send_keys("软件测试") 45 # time.sleep(3) 46 # driver.quit() 47 48 # '''css''' 49 # driver=webdriver.Chrome() 50 # driver.get("https://www.baidu.com") 51 # #send_keys---→输入的意思 52 # driver.find_element_by_css_selector('#kw').send_keys("软件测试") 53 # time.sleep(3) 54 # driver.quit() 55 56 '''LINK_TEXT:超链接 57 PARTIAL_LINK_TEXT:也是处理超链接,但是是模糊搜索''' 58 # driver=webdriver.Chrome() 59 # driver.get("https://www.baidu.com") 60 # #click:点击 61 # # driver.find_element_by_link_text('新闻').click() #超链接 62 # driver.find_element_by_partial_link_text('新闻').click() #模糊搜索超链接 63 # time.sleep(3) 64 # driver.quit() 65 66 ''' 67 元素定位的分类 68 1、单个元素定位 69 2、多个元素定位,多个元素定位指的是元素的属性都一致,那么这个时候它返回的是列表, 70 可以根据列表的索引来定位元素属性 71 3、不管是单个元素定位还是多个元素定位,它的方法都是8种 72 ''' 73 74 '''tagName''' 75 driver=webdriver.Chrome() 76 driver.get("https://www.baidu.com") 77 # send_key()--→输入的意思 78 # driver.find_element_by_tag_name("input").send_keys("软件测试") 79 tags=driver.find_elements_by_tag_name("input") 80 # print(type(tags)) 81 # for item in tags: 82 # print(item) 83 tags[7].send_keys("软件测试") 84 time.sleep(2) 85 driver.quit() 86 87 '''实战''' 88 # driver=webdriver.Chrome() 89 # driver.get("https://mail.sina.com.cn/") 90 # driver.find_element_by_id("freename").send_keys("jrq") #用户名输入框 91 # time.sleep(2) 92 # driver.find_element_by_id("freepassword").send_keys("123456") #密码输入框 93 # time.sleep(2) 94 # driver.find_element_by_class_name("loginBtn").click() #登录 95 # time.sleep(3) 96 # driver.quit() 97 98 '''获取测试的地址''' 99 # driver=webdriver.Chrome() 100 # driver.get("https://mail.sina.com.cn/") 101 # print(driver.current_url) #当前地址 102 # assert driver.current_url.endswith("sina.com.cn/") 103 # driver.quit() 104 105 '''获取当前页面代码''' 106 # driver=webdriver.Chrome() 107 # driver.get("https://mail.sina.com.cn/") 108 # print(driver.page_source) 109 # driver.quit() 110 111 '''获取页面的title''' 112 # driver=webdriver.Chrome() 113 # driver.get("https://www.baidu.com/") 114 # print(driver.title) 115 # assert driver.title=="百度一下,你就知道" #判断title是否是这个 116 # driver.quit() 117 118 '''页面的前进与后退''' 119 # driver=webdriver.Chrome() 120 # #浏览器最大化 121 # driver.maximize_window() 122 # driver.get("https://www.bing.com/") 123 # time.sleep(3) 124 # driver.get("https://www.baidu.com/") 125 # time.sleep(3) 126 # #后退 127 # driver.back() 128 # print("当前地址:",driver.current_url) 129 # time.sleep(3) 130 # #前进 131 # driver.forward() 132 # print("当前地址:",driver.current_url) 133 # time.sleep(3) 134 # driver.quit() 135 136 '''多窗口解决问题思路''' 137 # driver=webdriver.Chrome() 138 # driver.maximize_window() #浏览器最大化 139 # driver.get("https://mail.sina.com.cn/") 140 # #然后获取当前页面放在一个变量中 141 # nowHandle=driver.current_window_handle 142 # time.sleep(3) 143 # driver.find_element_by_link_text("注册").click() 144 # time.sleep(3) 145 # #获取所有页面并且放在一个变量中 146 # allHandlers=driver.window_handles 147 # #循环所有页面,判断如果不是当前页面,那么就是在新的页面 148 # for handler in allHandlers: 149 # if handler!=nowHandle: 150 # #从当前页面切换到新的页面 151 # driver.switch_to.window(handler) 152 # driver.find_element_by_name("email").send_keys("123456") 153 # time.sleep(3) 154 # #关闭新的浏览器 close关闭当前窗口,quit退出驱动并关闭所有关联的窗口 155 # driver.close() 156 # #切换到原来的页面 157 # driver.switch_to.window(nowHandle) 158 # time.sleep(5) 159 # driver.find_element_by_id("freename").send_keys("qwhytr") 160 # time.sleep(3) 161 # driver.quit() 162 163 '''clear():清空''' 164 # driver=webdriver.Chrome() 165 # driver.maximize_window() 166 # driver.get("https://www.baidu.com/") 167 # so=driver.find_element_by_id("kw") #把输入框定义为一个变量,方便进行输入和清空 168 # so.send_keys("很百度") 169 # time.sleep(3) 170 # so.clear() 171 # time.sleep(3) 172 # driver.quit() 173 174 '''get_attribute()的方法是获取元素属性的值''' 175 # driver=webdriver.Chrome() 176 # driver.maximize_window() 177 # driver.get("https://www.baidu.com/") 178 # so=driver.find_element_by_id("kw") 179 # so.send_keys("很百度") 180 # time.sleep(3) 181 # print(so.get_attribute("value")) #获取输入框的值(有输入才能获取) 182 # driver.quit()
selenium
开源web自动化测试工具,提供了丰富的测试函数,Selenium测试直接运行于浏览器中,真实模拟用户的业务行为。
支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。
这个工具的主要功能包括:
测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。
测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
自动化测试
优点:快速回归 脚本重用 代替人的重复活动,无需大量手动重复执行测试用例,极大提高了工作效率。
缺点:只能检查一些比较主要的问题(崩溃、死机),脚本编写的工作量大。
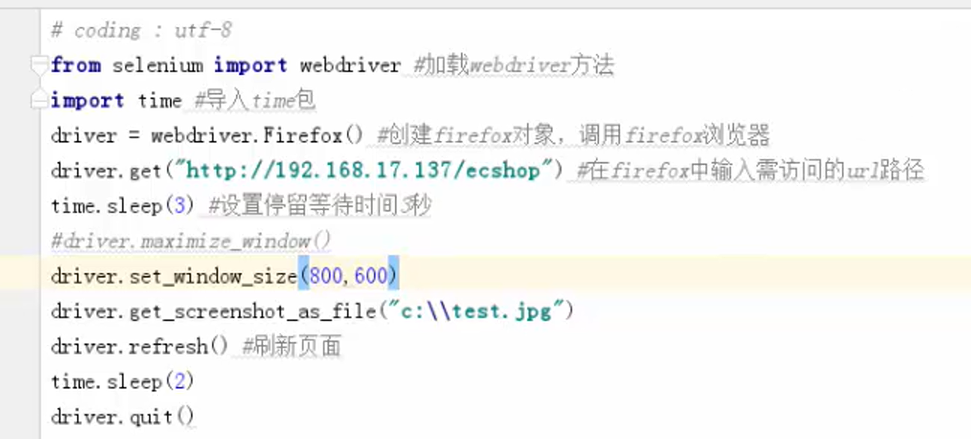
设置窗口大小:
driver.maximize_window() 设置全屏
driver.set_window_size( , ) 设置为固定分辨率大小
页面截屏:
get_screenshot_as_file( "路径和名称")
页面刷新:
driver.refresh()
关闭当前窗口:
driver.close()
关闭所有与当前操作有关联的窗口,并推出驱动。需释放资源时可使用此方法:
driver.quit()
一、元素定位方法
webdriver之所以能够操作浏览器,是因为它首先需要定位到被操作的元素属性,然后就可以对浏览器做各种操作。(通过元素定位到被操作的位置)
1.1元素定位方法(八个方法背下来)
(这八个方法的作用是一样的,都是用来定位元素的。)
ID = "id" (是唯一的,动态的)
NAME = "name"
CLASS_NAME = "class name"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
TAG_NAME = "tag name"
CSS_SELECTOR = "css selector"
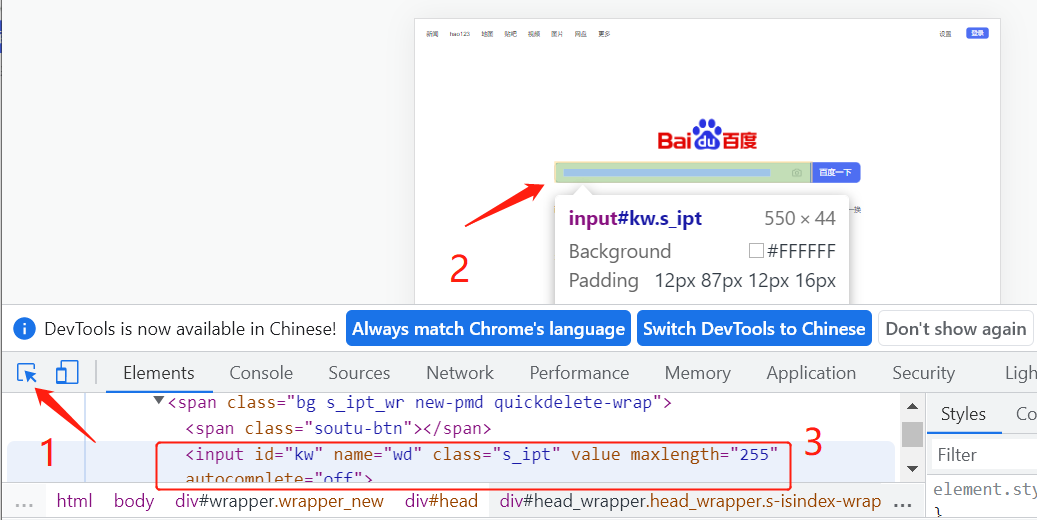
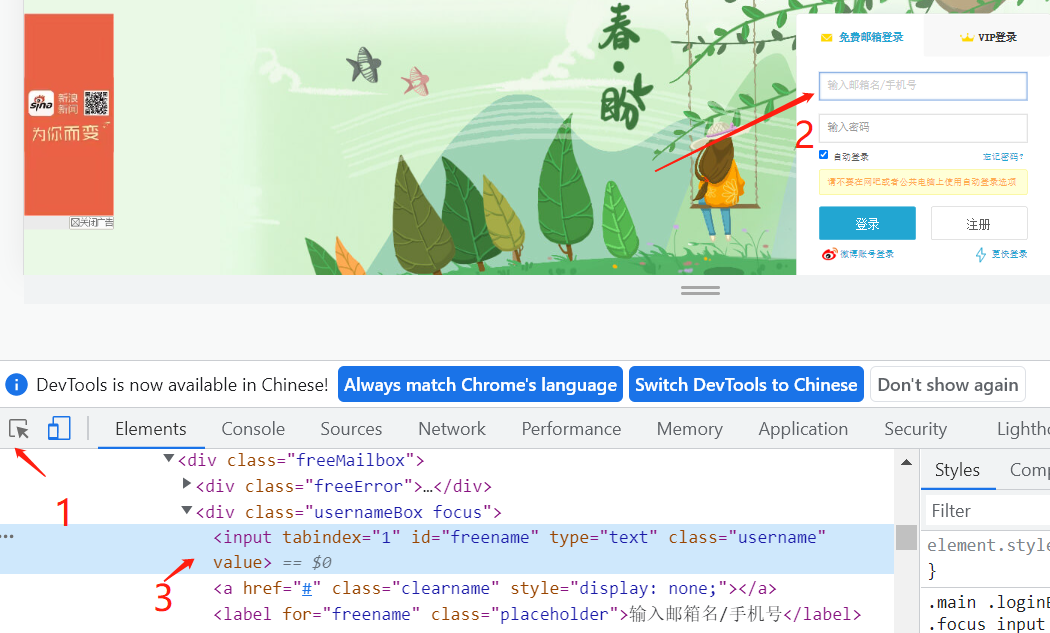
1.2以百度搜索输入框为例:获取源码
1、在百度首页右键、选择检查
(百度搜索输入框的input输入框的源代码部分,其中的id、name、class...这些是百度输入框的属性。操作时要用到这些。
技巧:如果在代码里找不到要找的元素,就用ctrl+f搜索出来。或者直接在要找的元素上面右键检查)
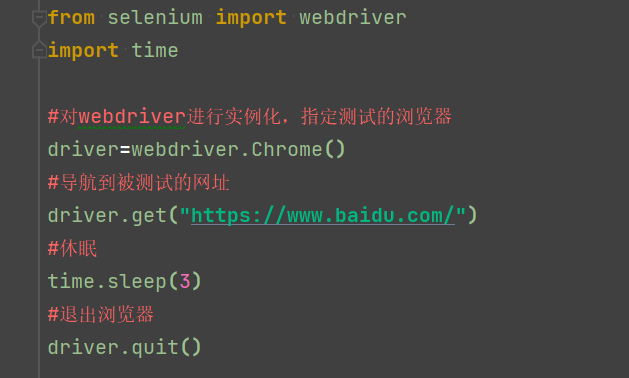
1.3 id元素属性
find_element_by_id
以id的属性来进行定位和具体的操作,从源代码我们就可以得到它的ID是"kw"

1.4 name元素属性
以name的属性来进行定位和具体的操作
find_element_by_name
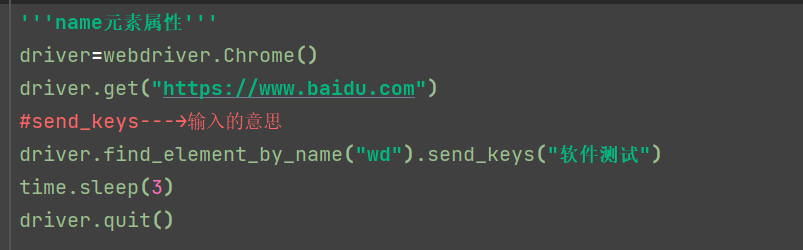
find_element_by_class_name
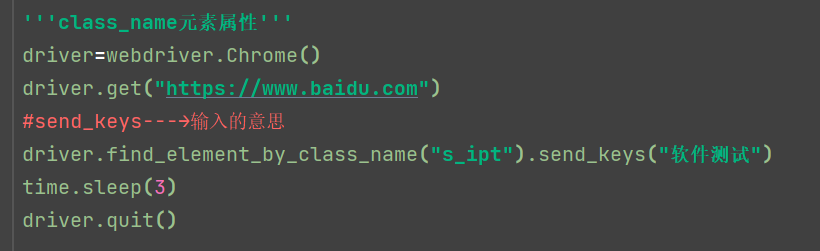
1.6 xpath和css
当你使用id、name、class_name都定位不到的时候,这个时候考虑使用css或xpath
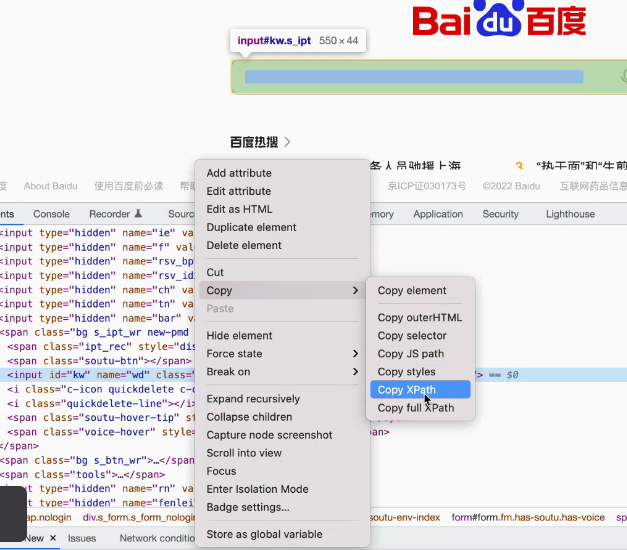
xpath:在输入框的这行代码上右键copy,点Copy XPath,在pycharm中粘贴(必须单引号)
find_element_by_xpath
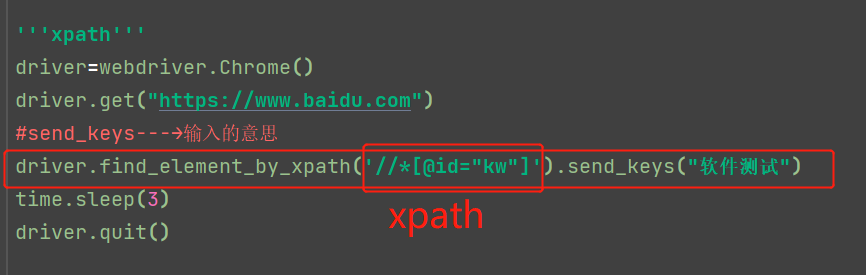
full xpath:

xpath和full xpath的区别:
一般来说,两个都可以,具体的:copy后粘贴出来,如果xpath获取到的是动态属性(如id),就需要用full xpath。而且xpath必须要单引号,full xpath 是双引号。多用full xpath。
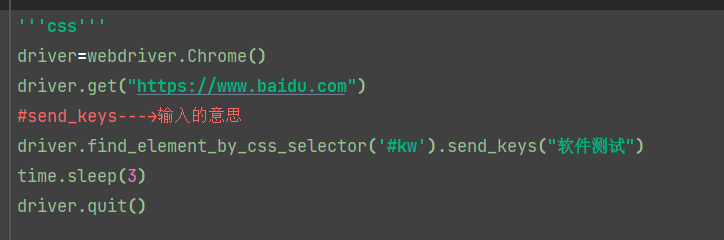
css:
find_element_by_css_selector
√css和xpath的区别:
css 选择是依据页面的数据样式定位的, 有标签选择, 类选择, id选择, 或者他们的交并集, 除此之外没有其他的辅助元素了
xpath 是路径表达式,所有元素和内容都可以成为路径的一部分. 两种定位方式功能基本一致, 但是xpath明显更强大, 只是xpath写起来较复杂,css写起来容易些,有的时候css会比xpath更快一些。
【我是这样理解的, css选择如同你尽可能具体的描述一个元素的形态, 包括他的: 标签, 类, id 以及这些的组合, 目标是尽可能确定元素的唯一坐标 , 以方便选择. 而xpath是根据元素的路径去确定坐标的.
举个例子, 形容上海, 用css可能会是 它是一座直辖市(类),在长江下游(标签),是中国最大的城市(id),人口众多,经济发达(其他标签)
用xpath则是: 它是东经 121°.4′ ;北纬 31°.2′ 的城市(绝对路径) 或者 江苏以南,浙江以北,苏州市东侧,长江入海口(相对路径)】
1.7超链接
a标签里都是超链接。
LINK_TEXT:超链接
PARTIAL_LINK_TEXT:也是处理超链接,但是是模糊搜索
 (百度主页里的新闻超链接)
(百度主页里的新闻超链接)
运用条件:
二、元素定位的分类
1、单个元素定位
2、多个元素定位,多个元素定位指的是元素的属性都一致,那么多个元素定位时返回的是列表类型,需要根据列表的索引来具体定位某个元素属性
3、不管是单个元素定位还是多个元素定位,它的方法都是8种
多个元素定位√:
(在使用单个元素定位不到的情况下,我们可以使用多个元素定位。多个元素定位方法也是那八种,只是元素的属性都是一致的 获取到的就是列表类型,还需要再用索引来定位一下元素属性。)
以tag_name元素定位方法为例:
(tag_name可以理解为定义标签,百度搜索输入框它的tag_name是input。)
如下图,input标签有很多个,针对这种不是唯一的,我们可以使用多个元素定位的方式来解决,其实多个元素定位的核心思想是获取到的元素属性是一个列表,我们可以使用列表的索引来进行定位。
比如标签的方法就是find_elements_by_tag_name(),其他的方法也是相应的,这里我们先获取到它的属性(它的数据是列表),再根据索引定位:
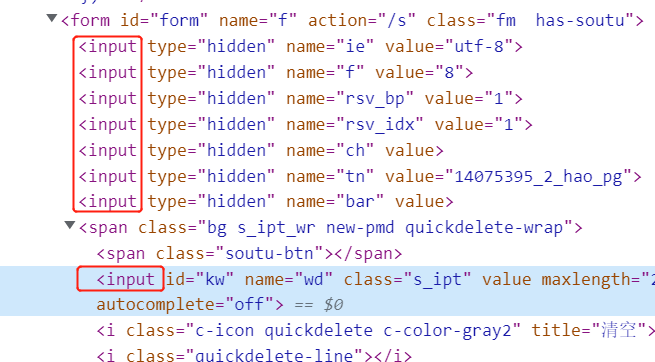
多元素定位的
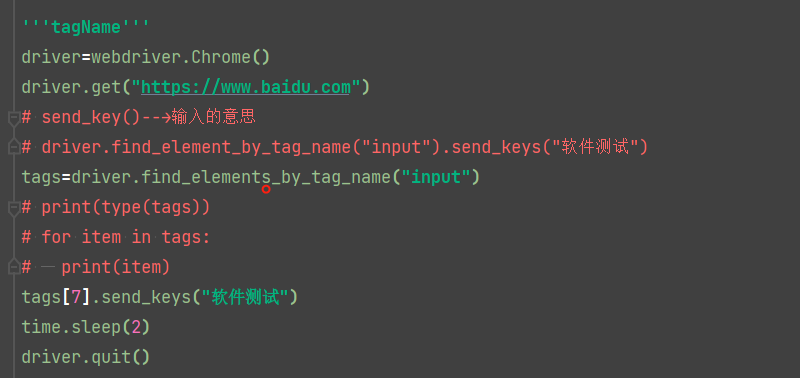
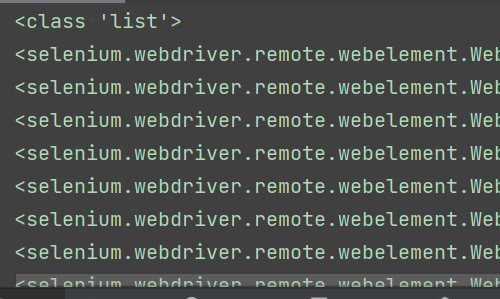
三、WebDriver浏览器属性详解
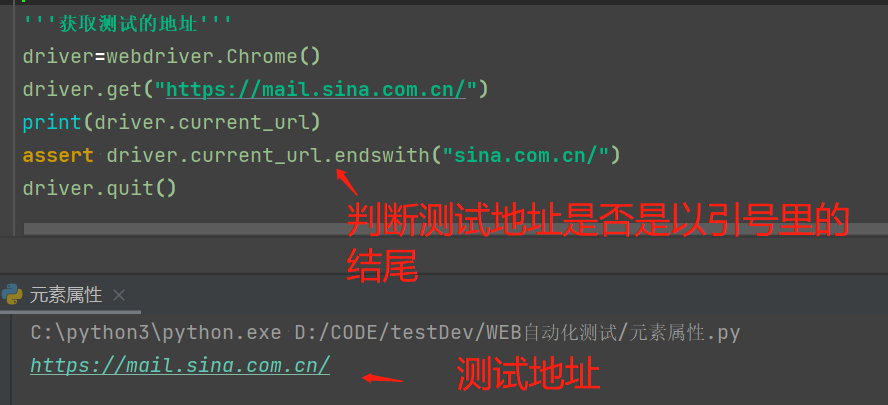
3.1获取测试的地址
current_url (加print)
assert是Python原生的断言方法
a=1
b=1
assert a==b(判断a等于b)
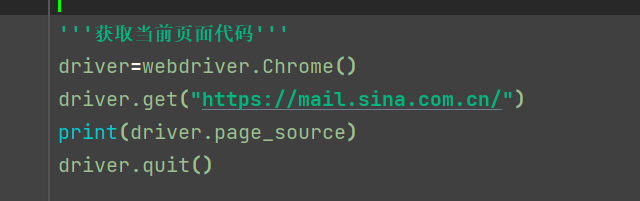
3.2获取当前页面代码
做网络爬虫方面
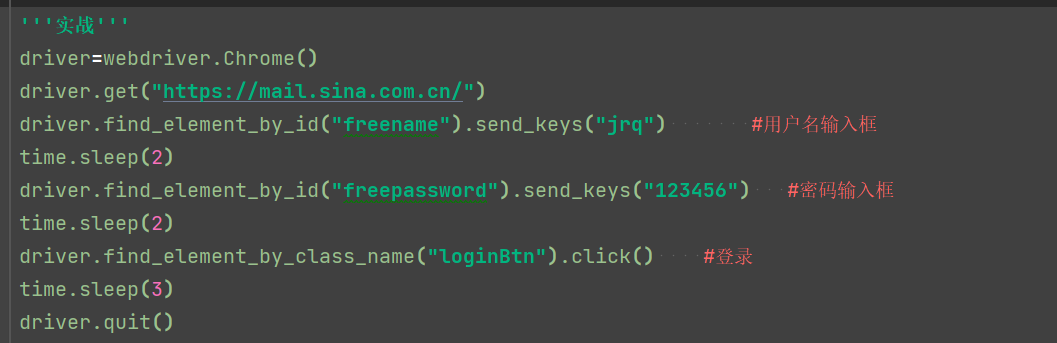
page_source (加print)
该方法为特性方法,属于只读属性
.title (加print)

3.4页面的前进与后退
.forward() 是前进
.back() 是后退

需要实现从当前页面切换到另外一个新的页面,那么这个时候就需要使用到多窗口的操作和实战。解决步骤:
1、先打开当前页面
2、然后获取当前页面放在一个变量中 current_window_handle
3、打开新的页面
4、获取所有页面并且放在一个变量中 window_handles
5、循环所有页面,判断如果不是当前页面,那么就切换到新的页面 switch_to.window(xxx)
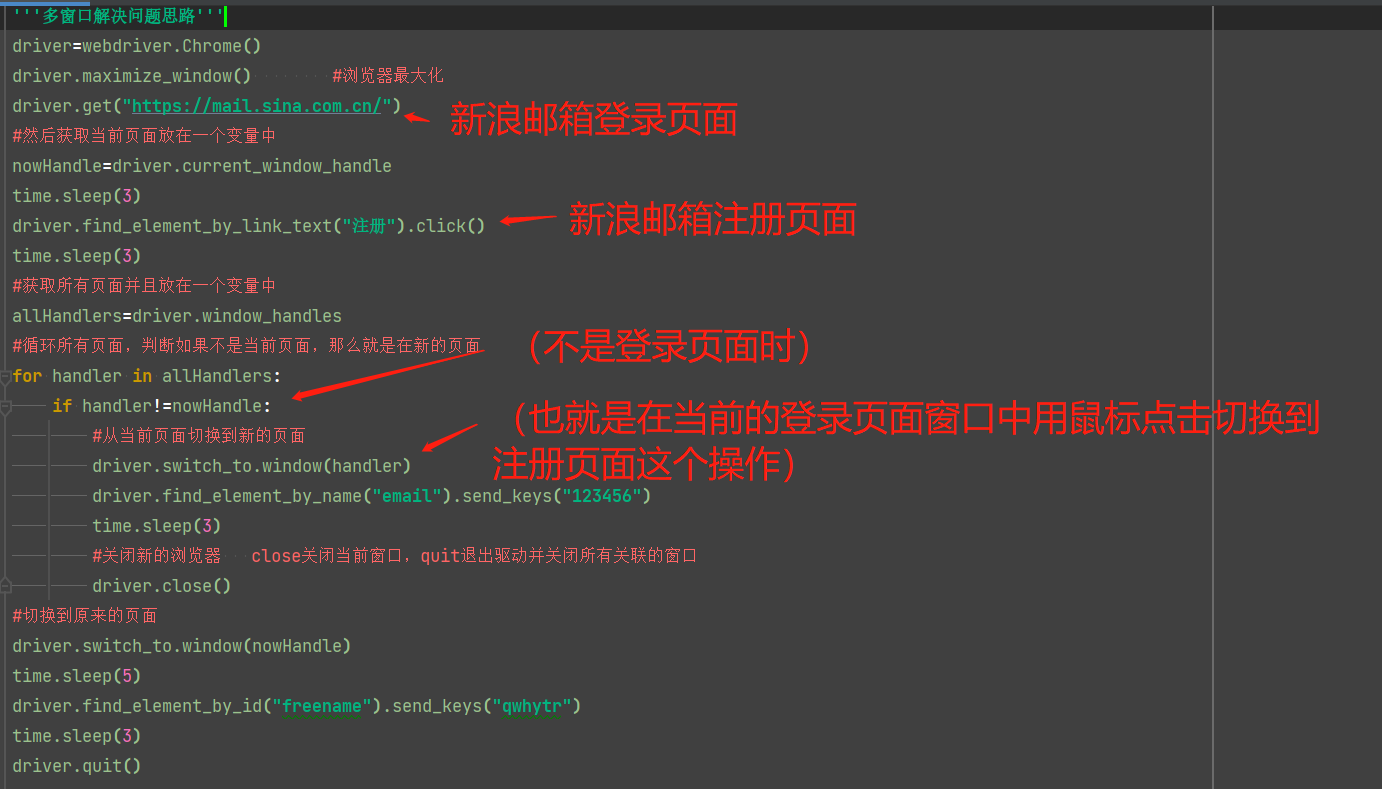
获取当前页面: nowHandle=driver.current_window_handle (等号前的变量名自己起)
获取所有页面: allHandles=driver.window_handles (等号前的变量名自己起)
循环所有页面: for handle in allHandles:
if handle !=nowHandle:
切换页面: driver.switch_to.window(handle)
关闭当前窗口: driver.close()
3.6 clear():清空

把定位到的元素放到一个变量中,比如输入框,然后执行send_keys 或 clear等操作
如so=driver.find_element_by_id("kw")
so.send_keys("百度")
so.clear()
其实就相当于 driver.find_element_by_id("kw").send_keys("百度")和 driver.find_element_by_id("kw").clear()
3.7获取元素属性的值
get_attribute()
(input输入框输入的值都放在value中了,如下图获取value的值:)


3.8判断是否勾选
is_selected()
先定位到元素,定义为一个变量,再判断
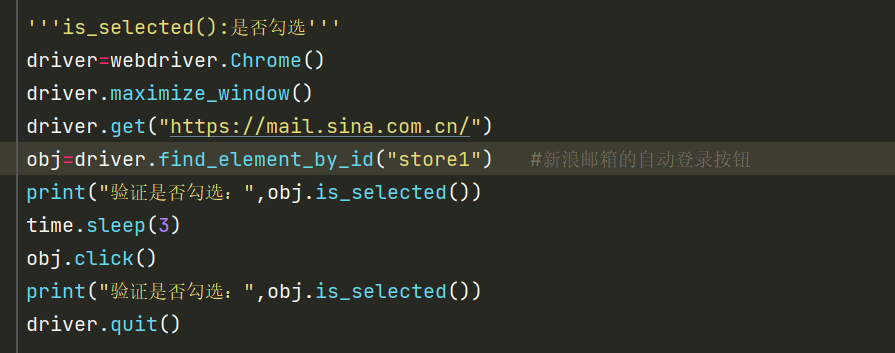
3.9判断是否可编辑
is_enabled()

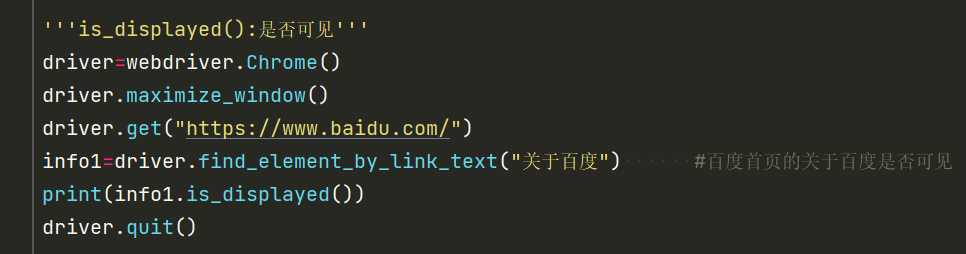
3.10判断是否可见
is_displayed()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号