Blender文档翻译:RNA
官方文档:https://wiki.blender.org/wiki/Source/Architecture/RNA
这是关于数据API实现的文档。
--Brecht 22:35, 31 October 2008 (UTC)
实现
实现位于makesrna模块。了解系统的重要文件包括:
RNA_types.h: 重要的RNA数据结构定义在这里。 RNA_access.h: 运行时访问结构和属性的API。
RNA_define.h: 定义结构和属性的API。

定义结构和属性
结构及其属性在RNA_*.C文件中定义,于makesrna模块中,定义生成为构建系统的一部分。错误将在生成过程中打印出来,并将有助于调试。
结构
- 如果没有添加它到一个已存在的文件:
- 复制一个已有文件,改名并清理。
- 在makesrna.c中,添加它到PROCESS_ITMES列表中。
- 在rna_access.h中,添加extern StructRNA声名
- 对于数据块,在rna_ID.c文件中添加恰当的ID_case到rna_ID_refine()函数中
接着在RNA_def_*函数中必须定义结构。RNA_def_struct 定义结构本身。我们必须定义identifier,它是一个唯一的名称,用于代码中识别结构,以及name一个人类可读的名称。
系统将自动尝试找到具有与标识符相同的名称的相应DNA结构。如果存在相应的DNA结构,但它具有不同的名称,则可以使用RNA_Def_CT_SDNA来传递正确的名称,这对于稍后更自动地定义属性是重要的。
每一个结构,它也可以设置一个字符串的属性为结构的名称,将用于在UI和在集合中的字符串查找。
对于ID结构,还必须:
- 在rna_main.c中,更改一个 “lists”数组中已有的项为正确的类型代替“ID”,或者添加一个新的项。
- 添加结构到rna_ID_refine在rna_ID.c中
属性
对于每个属性,我们首先使用RNA_def_property。必须定义identifier ,它与结构中定义类似。接下来,我们必须定义type和subtype。type定义数据类型,subtype给出对数据的某些解释,例如,浮点数组属性可以是颜色、矢量或矩阵。
同样,系统将尝试找到与DNA结构中的identifier 同名的属性,如果它有不同的名称,那么下一步要做的就是使用rna_def_*_sDNA函数来指定它。这些DNA信息用于派生各种东西,例如GET/SET函数或集合的迭代器、数组长度、限制等,映射如何工作的规则在下一节解释。
如果自动值不正确,则可以在事后重写这些值。文件rna_definition.h概述了可以为不同类型提供的信息。要定义的重要内容是数组长度、数字范围和枚举项。
接下来,我们必须定义一个默认值。如果没有显式定义,则假定数字为0,字符串为“”,指针为空,集合为空。
为自动构建UI,定义了可读的名称和工具提示描述。可定义数字软范围,拖动步长,精度。这些将是从RNA属性制作按钮时的默认值。
在许多情况下,自动DNA匹配将负责这一点,但在其他情况下,我们必须为GET / Set函数定义回调函数。他们的名字为rna_def_property_ * _funcs函数,关于它可查看rna_types.H。集合是最困难的,虽然listbase和典型的数组能自动支持。注意,一些函数调用是可选的,只对优化起作用,例如列表的查找函数。
DNA匹配
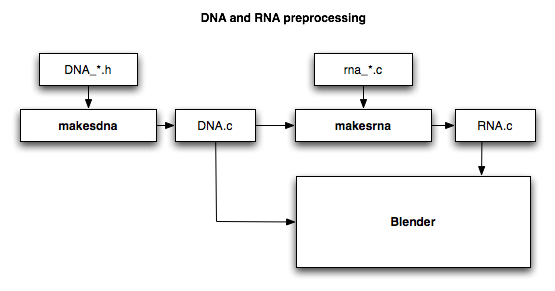
- booleans/ints/Floats:数组长度基于float member[x]中x的值;例如,只支持一维数组。如果变量本身不是数组,它将假设连续变量是数组的一部分。例如,指定r于float r,g,b;;它将假定数组的地址为&r。
- 布尔值可以指定在rna_def_property_boolean_sdna中的一个“bit”。定义了数组长度但没有SDNA数组成员则假定数组是由bitflags定义的开始于指定“位”。
- 整数:数据范围默认为int_min / int_max,除非发现是一个char或short,在这种情况下,使用范围。目前不能自动检测unsigned类型(SDNA没有提供它们),用PROP_UNSIGNED 子类型或手动范围应该用于它们。
- Enums: RNA_def_property_enum_sdna有一个参数bitflags来设定enum值,它应是与其它flags混合在一起的。
- Strings: CHAR数组是可识别的,最大长度是根据数组大小确定的。
- Pointers:如果还没有设置指针类型,则根据结构与DNA对应关系自动定义指针类型。对于定义为指针数组的集合,也使用指针。
- Collections: 一个listbase是可识别的且begin/next/get函数基于它自动生成。
- Collections: 当将包含集合长度的变量的名称传递给sdna函数时,假定使用数组,数组的begin/next/end函数将自动生成。如果成员的指针是单个指针,如MVert *mvert;,它将返回&mvert[i],如果是双指针象Material **mat则返回mat[i
- 嵌套结构中成员可以被识别,如给rna_def_property_ * _sdna一个值像r.cfra或toolsettings-> Unwrapper。
名称转换
结构
- 标识符:使用CamelCase,例如“Matter”、“noderee”。在python代码中使用时标识符应该是有效名称。
- 名称:使用大写字母加空格,例如“Material”、“Node Tree”。
属性
- 不要不必要地缩短名字。这通常是在按钮中以节省空间,并且因为可以从上下文中获得意义,但是这取决于按钮的布局,因此不一定要用RNA来完成。
- 避免使用“No Vertex Normal Flip”这样的负面名称,在这种情况下,将布尔值更改为“Vertex Normal Flip”。
- 标识符:使用小定字母和下划线,例如“alpha”、“diffuse Color”。标识符应该是可用于python代码的有效名称,即没有空格,不要以数字开头...
- 名称:用大写字母加上空格,例如“Alpha”,“Diffuse Color”。描述:只有当它不明显时,如果它只是重复名称或类似于“顶点的位置”,它无论如何都是无用的。用典型的句子写成句子
- 描述:只有当它不明显时,如果它只是重复名称或类似于“Location of the Vertex”,反正它无大用的。用典型的大写形式写成句子。
属性缩写
下面属性可用的缩写表:
- minimum/maximum -> min/max
- coordinates -> co
属性前缀/后缀
- 属性单词顺序应该从最重要到最不重要。例如min_x,offset_x,lock_y而不是...xmin,x_min,y_offset
- Booleans应有前缀
- use_ 常用前缀表示是否使用了一个选项。
- use_only_ 和use一样,但表示排他性。
- show_ 用于绘图选项或界面显示切换
- show_only_ 与show_一样但表示独占性。
- is_ 用于只读检查 is_saved, is_valid。
- lock_ 用于锁定功能的选项。lock_x
- invert_用于反相功能的选项。
应有前缀的名字的例子。 use_texture, use_border, use_mipmaps
boolean前缀例外
- select 常用的,显然它描述了一个选择布尔值。
- hide 类似于选择,用于隐藏的数据。
- layer boolean数组用于物体和骨骼层。
- state boolean数组用于游戏引擎。
- float值从0.0到1.0后缀用_factor。这对于下列情况更好。reflection->reflect_factor, glossiness->gloss_factor
文件和路径名
处理文件路径的字符串具有以下约定
- filepath: 文件全路径。
- filename: 文件名不包括路径
- path: 目录路径或任意文件系统位置。
Enum项
- identifier: 全大写和下划线.
- name: 使用大写字母和空格,如 "Conformal", "Angle Based"。
内部
RNA定义生成类似DNA预处理,作为构建系统的一部分。这样的预处理步骤避免了手工编写大量API代码,利用了DNA系统的可用信息。此外,它避免启动开销,因为定义的结果将被烘烤到源代码中。然而,对于Python /plugin ID属性,这仍然需要在运行时完成,尽管当前的代码不支持。
这个定义与DNA文件是分开的,而不是嵌入在注释中,正如早期的其他建议一样。结构/属性不一定与DNA结构/成员的一对一映射所以这是必要的。多个属性可能是一个DNA结构成员的一部分,例如布尔值存储为bitflags这种情况。一个属性可能基于多种DNA结构成员,例如网格顶点集由mvert和totvert构成。
目前自动生成代码纳入单个RNA.c文件。可以将其写入现有文件,例如blenkernel中,但如果这些文件同时在IDE中编辑,那么这样做似乎有点危险,也不方便。
运行时访问
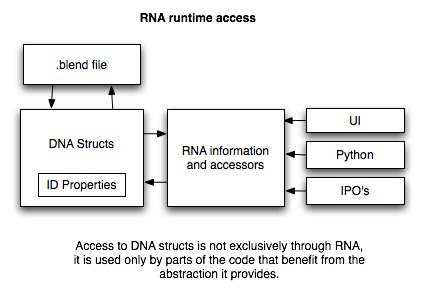
运行时对属性值的访问是通过rna_access.h中定义的函数完成的。主要提供了GET/SET函数和集合迭代器。
还有一些函数可以检查属性是可编辑的还是可运算的。如果该属性是可编辑的,这意味着它可以由用户编辑。如果是可运算的,这意味着它可以设置为某些函数作为运算部分,例如修改器、约束或动画系统的其他部分。例如,若属性有一个IPO,这可改变依赖。
指针

一个指向RNA结构的指针总是包裹于PointerRNA 结构。它包含实际的数据指针和结构类型。它也包含数据指针和数据所属ID数据块的类型。在某些情况下这是必要的,例如一个顶点本身不能提供足够的信息来更新依赖图,我们需要知道这个顶点来自哪个网格。
在运行时创建的指针,使用RNA_main_pointer_create,RNA_id_pointer_create和RNA_pointer_create函数。
属性函数回调得到这样的PointerRNA而不是直接指向数据的指针,以便如果需要使用ID数据。指针和集合get/set函数回调返回数据指针,类型和ID将会在回调外被自动填充。
ID属性
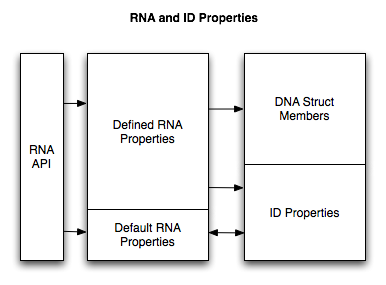
RNA支持ID属性有二种方式:
- 如果在运行时定义了一个RNA属性,或者使用PROPORT_IDPROPERTY 标志,则将在该属性第一次通过RNA API设置该属性时创建ID属性。RNA API将返回初始默认值,直到创建ID属性,然后返回id属性值。请注意,如果有一个属性具有相同的名称,但与用RNA定义的类型不同,则将删除并重写以匹配RNA类型。
- 如果一个ID属性存在,但没有相应的RNA的属性,它将仍然可以迭代结构属性时通过RNA暴露。RNA信息将得到默认值:比如用户界面的名字将从ID属性名获得,数字范围将是该类型的默认值。
操作
操作的输入是在运行时用RNA定义的,相应的ID属性将自动创建。通过名称轻松访问这些属性的API定义在rna_access.h,象这些函数RNA_float_set(op->ptr, "value", 3.1415f); and RNA_float_get(op->ptr, "value");
注册操作时,RNA结构将自动创建,只有由结构OT->SRNA指向的属性必须创建。
更新
设置RNA属性时,Blender可能需要更新,以确保正确的依赖关系或重画编辑器。每个属性都可以具有一个在set()之后运行的关联UPDATE()函数和一个事件通知。

试验性东西
RNA路径
当前代码包含字符串引用结构和属性的试验性功能,语法象这样:scenes[0].objects["Cube"].data.verts[7].co。
当断开一个具体的指针的连接时,它提供了一种引用RNA数据的方式,这在一些应用中是有用的,象UI代码或动作,虽然效率是一个问题,而且不确定是否最终会有用。
依赖关系
有一些属性标志来指示依赖关系。如何及是否将使用该属性尚不清楚,但这可能是一个有趣的系统,可以更自动地生成依赖关系图。但是这也有一些问题,例如,系统可能不知道修改器是否被禁用,因此它可能会计算不必要的依赖关系,除非该依赖关系运行时可以通过回调来检查。
另外,依赖关系图比全部对象更精细,并且类似于组和代理的功能可能难以支持,并且依赖关系图可能不值得/不可行,2.5版尝试更多地改进。
副页
原文:https://wiki.blender.org/index.php/Dev:2.5/Source/Architecture/RNA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号