


分库分表扩容
现在要设计电商网站的订单数据库模块,经过对业务增长的估算,预估三年后,数据规模可能达到 6000 万,每日订单数会超过 10 万。
存储实现,订单作为电商业务的核心数据,应该尽量避免数据丢失,并且对数据一致性有强要求,肯定是选择支持事务的关系型数据库,比如使用 MySQL 及 InnoDB 存储引擎。
数据库的高可用,订单数据是典型读多写少的数据,不仅要面向消费者端的读请求,内部也有很多上下游关联的业务模块在调用,针对订单进行数据查询的调用量会非常大。基于这一点,我们在业务中配置基于主从复制的读写分离,并且设置多个从库,提高数据安全。
路由规则与扩容方案
现在我们考虑 3 种路由规则:对主键进行哈希取模、基于数据范围进行路由、结合哈希和数据范围的分库分表规则。
1. 哈希取模的方式
6000 万的数据规模,我们按照单表承载百万数量级来拆分,拆分成 64 张表,进一步可以把 64 张表拆分到两个数据库中,每个库中配置 32 张表。当新订单创建时,首先生成订单 ID,对数据库个数取模,计算对应访问的数据库;
接下来对数据表取模,计算路由到的数据表,当处理查询操作时,也通过同样的规则处理,这样就实现了通过订单 ID 定位到具体数据表。
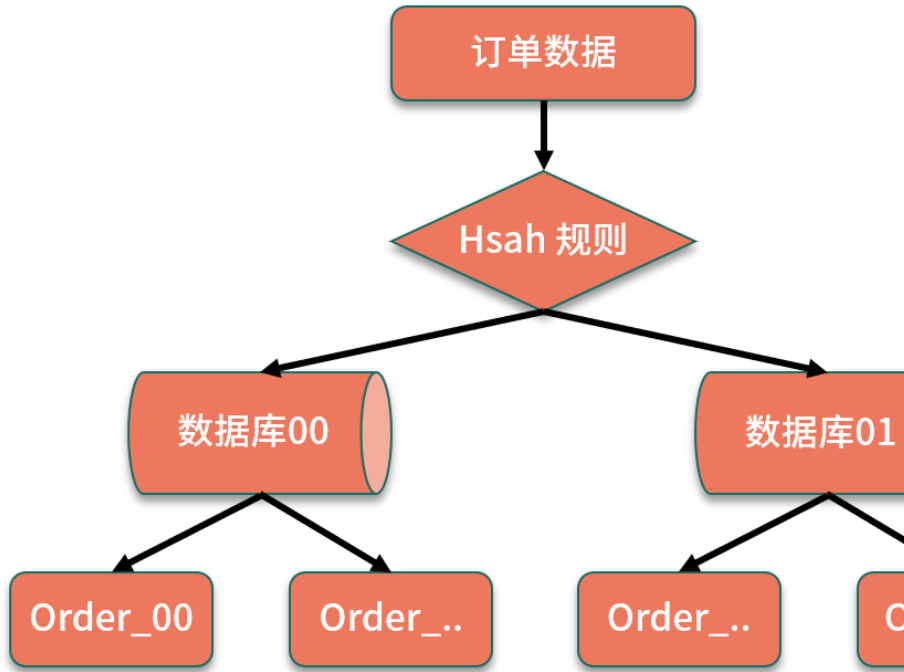
2. 基于数据范围进行拆分
3. 结合数据范围和哈希取模
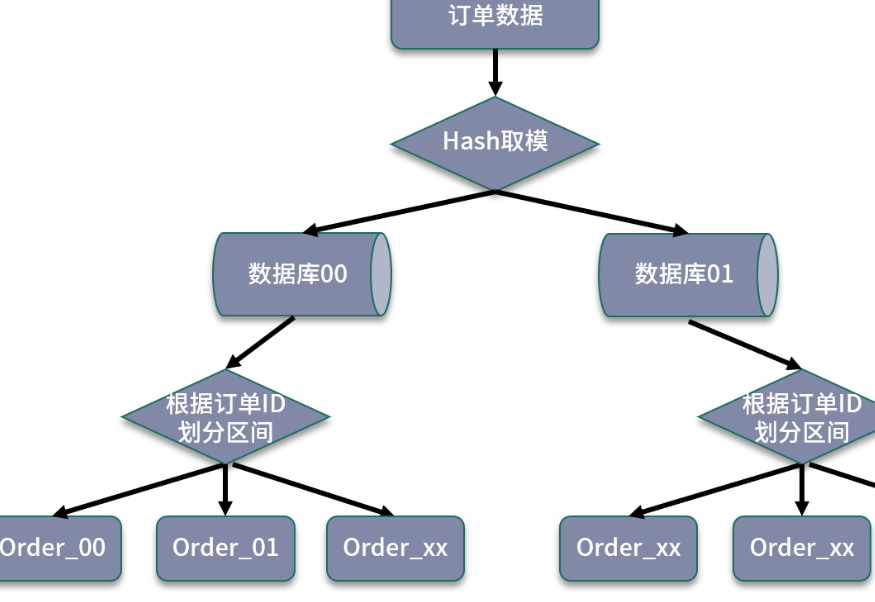
这种方式避免了单纯基于数据范围可能出现的热点存储,并且在后期扩展时,可以直接增加对应的扩展表,避免了复杂的数据迁移工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号