


分布式锁
大促活动有一个共同特点就是访问量激增,在高并发下会出现成千上万人抢购一个商品的场景。虽然在系统设计时会通过限流、异步、排队等方式优化,但整体的并发还是平时的数倍以上,参加活动的商品一般都是限量库存,如何防止库存超卖,避免并发问题呢?分布式锁就是一个解决方案。
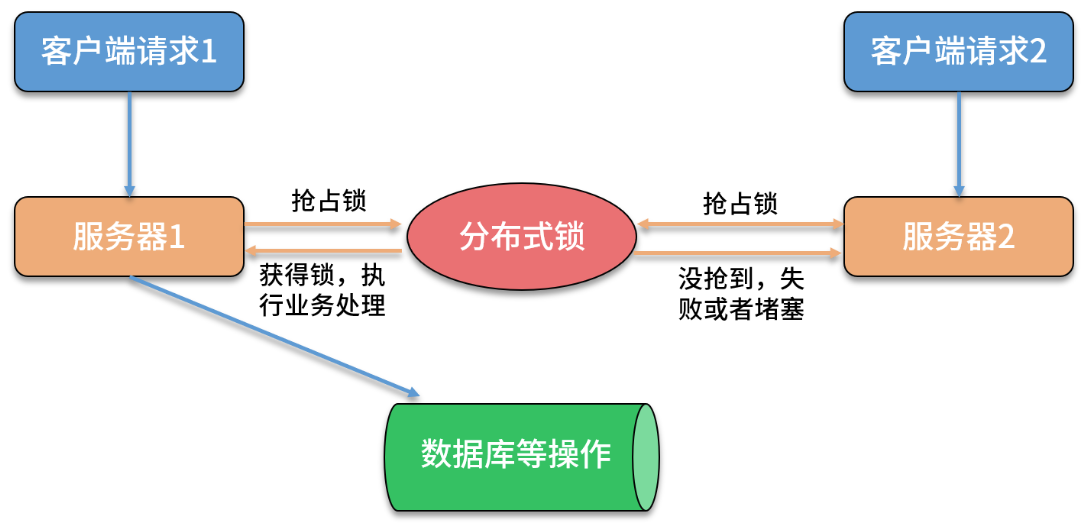
分布式锁的常用实现
基于数据库、Redis、ZooKeeper 的方案。
基于关系型数据库实现分布式锁,是依赖数据库的唯一性来实现资源锁定,比如主键和唯一索引等。
以唯一索引为例,创建一张锁表,定义方法或者资源名、失效时间等字段,同时针对加锁的信息添加唯一索引,比如方法名,当要锁住某个方法或资源时,就在该表中插入对应方法的一条记录,插入成功表示获取了锁,想要释放锁的时候就删除这条记录。
应用 Redis 缓存
缓存的性能更好,并且各种缓存组件也提供了多种集群方案,可以解决单点问题。
最直接的想法是利用 setnx 和 expire 命令实现加锁。在 Redis 2.8 版本中,添加了 SETEX 命令,SETEX 支持 setnx 和 expire 指令组合的原子操作,解决了加锁过程中失败的问题。
基于 ZooKeeper 实现
ZooKeeper 有四种节点类型,包括持久节点、持久顺序节点、临时节点和临时顺序节点,利用 ZooKeeper 支持临时顺序节点的特性,可以实现分布式锁。
当客户端对某个方法加锁时,在 ZooKeeper 中该方法对应的指定节点目录下,生成一个唯一的临时有序节点。判断是否获取锁,只需要判断持有的节点是否是有序节点中序号最小的一个,当释放锁的时候,将这个临时节点删除即可,这种方式可以避免服务宕机导致的锁无法释放而产生的死锁问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号