


分布式事务
分布式事务就是一个业务操作,是由多个细分操作完成的,而这些细分操作又分布在不同的服务器上;事务,就是这些操作要么全部成功执行,要么全部不执行。
数据库事务
原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durabilily),简称 ACID。
脏读,是指一个事务中访问到了另外一个事务未提交的数据。
不可重复读,是指一个事务读取同一条记录 2 次,得到的结果不一致。例如事务 T1 第一次读取数据,接下来 T2 对其中的数据进行了更新或者删除,并且 Commit 成功。
幻读,是指一个事务读取 2 次,得到的记录条数不一致。例如事务 T1 查询获得一个结果集,T2 插入新的数据,T2 Commit 成功后,T1 再次执行同样的查询,此时得到的结果集记录数不同。
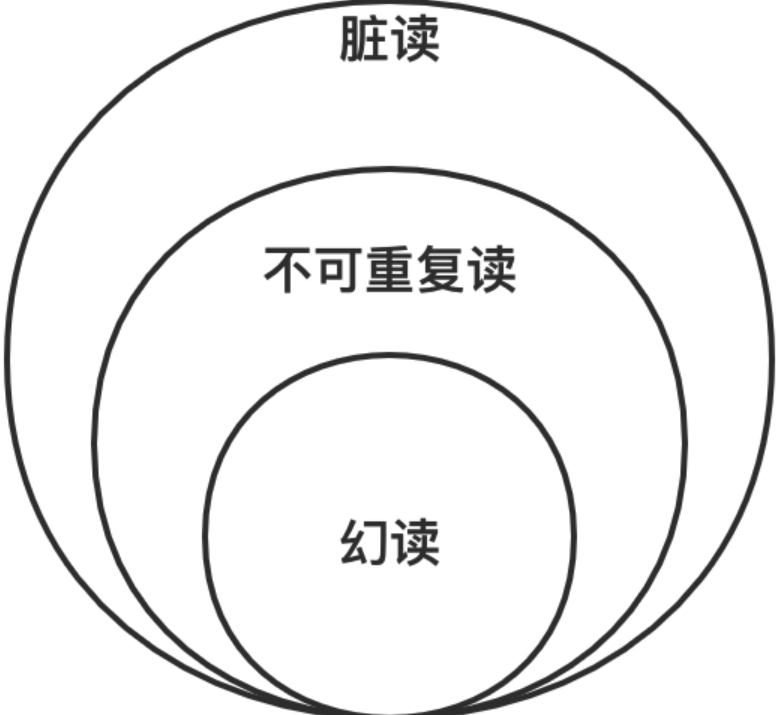
不同隔离级别
分布式事务产生的原因
分布式事务产生的原因主要来源于存储和服务的拆分。
存储层拆分
最典型的就是数据库分库分表,一般来说,当单表容量达到千万级,就要考虑数据库拆分,从单一数据库变成多个分库和多个分表。在业务中如果需要进行跨库或者跨表更新,同时要保证数据的一致性,就产生了分布式事务问题。
服务层拆分
服务层拆分也就是业务的服务化,系统架构的演进是从集中式到分布式,业务功能之间越来越解耦合。
分布式事务解决方案
2PC 两阶段提交
两阶段提交(2PC,Two-phase Commit Protocol)是非常经典的强一致性、中心化的原子提交协议,在各种事务和一致性的解决方案中,都能看到两阶段提交的应用。
3PC 三阶段提交
三阶段提交协议(3PC,Three-phase_commit_protocol)是在 2PC 之上扩展的提交协议,主要是为了解决两阶段提交协议的阻塞问题,从原来的两个阶段扩展为三个阶段,增加了超时机制。
TCC 分段提交
TCC 是一个分布式事务的处理模型,将事务过程拆分为 Try、Confirm、Cancel 三个步骤,在保证强一致性的同时,最大限度提高系统的可伸缩性与可用性。
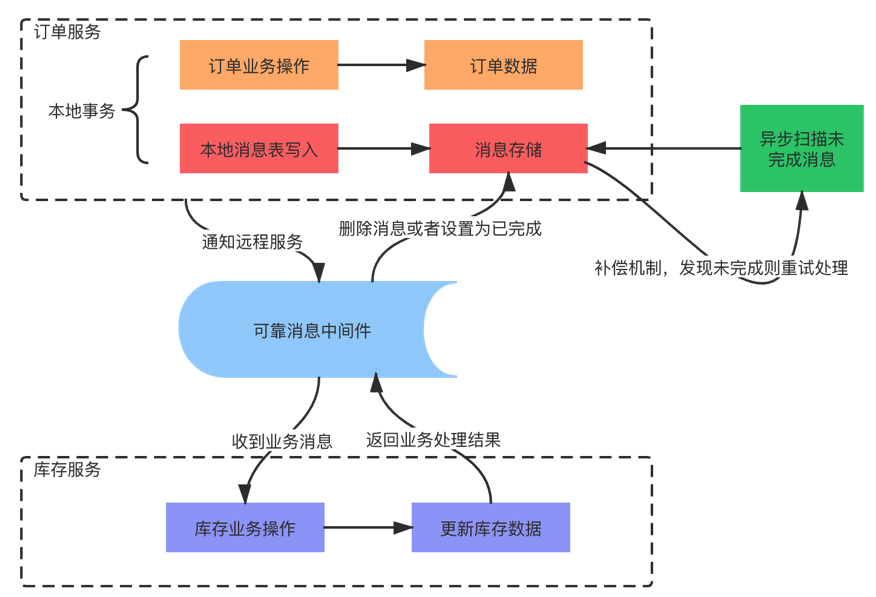
基于消息补偿的最终一致性
基于消息补偿的一致性主要有本地消息表和第三方可靠消息队列等。
本地消息表是一种业务耦合的设计,消息生产方需要额外建一个事务消息表,并记录消息发送状态,消息消费方需要处理这个消息,并完成自己的业务逻辑,另外会有一个异步机制来定期扫描未完成的消息,确保最终一致性。
分布式事务有哪些开源组件
分布式事务开源组件应用比较广泛的是蚂蚁金服开源的 Seata
在 Seata 中,全局事务对分支事务的协调基于两阶段提交协议,类似数据库中的 XA 规范

 浙公网安备 33010602011771号
浙公网安备 33010602011771号