


MQ
在使用 MQ 的时候,怎么确保消息 100% 不丢失?
引入 MQ 消息中间件最直接的目的是:做系统解耦合流量控制,追其根源还是为了解决互联网系统的高可用和高性能问题。
-
系统解耦:用 MQ 消息队列,可以隔离系统上下游环境变化带来的不稳定因素,比如京豆服务的系统需求无论如何变化,交易服务不用做任何改变,即使当京豆服务出现故障,主交易流程也可以将京豆服务降级,实现交易服务和京豆服务的解耦,做到了系统的高可用。
-
流量控制:遇到秒杀等流量突增的场景,通过 MQ 还可以实现流量的“削峰填谷”的作用,可以根据下游的处理能力自动调节流量。
引入 MQ 消息中间件实现系统解耦,会影响系统之间数据传输的一致性
而引入 MQ 消息中间件解决流量控制, 会使消费端处理能力不足从而导致消息积压,这也是你要解决的问题。
在使用 MQ 消息队列时,如何确保消息不丢失”这个问题时,你要怎么回答呢?首先,你要分析其中有几个考点,比如:
-
如何知道有消息丢失?
-
哪些环节可能丢消息?
-
如何确保消息不丢失?
要先让面试官知道你的分析思路,然后再提供解决方案
“架构设计”“架构”体现了架构师的思考过程,而“设计”才是最后的解决方案,两者缺一不可。
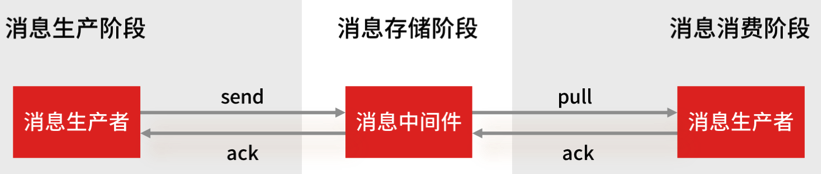
-
消息生产阶段: 从消息被生产出来,然后提交给 MQ 的过程中,只要能正常收到 MQ Broker 的 ack 确认响应,就表示发送成功,所以只要处理好返回值和异常,这个阶段是不会出现消息丢失的。
- 消息存储阶段: 这个阶段一般会直接交给 MQ 消息中间件来保证,但是你要了解它的原理,比如 Broker 会做副本,保证一条消息至少同步两个节点再返回 ack
-
消息消费阶段: 消费端从 Broker 上拉取消息,只要消费端在收到消息后,不立即发送消费确认给 Broker,而是等到执行完业务逻辑后,再发送消费确认,也能保证消息的不丢失。
消息检测? 总体方案解决思路为:在消息生产端,给每个发出的消息都指定一个全局唯一 ID,或者附加一个连续递增的版本号,然后在消费端做对应的版本校验。
具体怎么落地实现呢?你可以利用拦截器机制。 在生产端发送消息之前,通过拦截器将消息版本号注入消息中(版本号可以采用连续递增的 ID 生成,也可以通过分布式全局唯一 ID生成)。然后在消费端收到消息后,再通过拦截器检测版本号的连续性或消费状态,这样实现的好处是消息检测的代码不会侵入到业务代码中,可以通过单独的任务来定位丢失的消息,做进一步的排查。
怎么解决消息被重复消费的问题?
如何解决消费端幂等性问题(幂等性,就是一条命令,任意多次执行所产生的影响均与一次执行的影响相同),只要消费端具备了幂等性,那么重复消费消息的问题也就解决了。
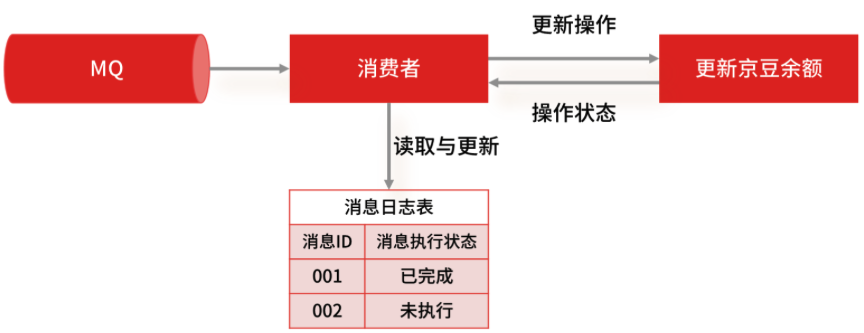
最简单的实现方案,就是在数据库中建一张消息日志表, 这个表有两个字段:消息 ID 和消息执行状态。这样,我们消费消息的逻辑可以变为:在消息日志表中增加一条消息记录,然后再根据消息记录,异步操作更新用户京豆余额。
想要解决“消息丢失”和“消息重复消费”的问题,有一个前提条件就是要实现一个全局唯一 ID 生成的技术方案
“消息积压”。 原因在于消息积压反映的是性能问题,解决消息积压问题,可以说明候选者有能力处理高并发场景下的消费能力问题。
消息发送之后才会出现积压的问题,所以和消息生产端没有关系,又因为绝大部分的消息队列单节点都能达到每秒钟几万的处理能力,相对于业务逻辑来说,性能不会出现在中间件的消息存储上面。毫无疑问,出问题的肯定是消息消费阶段,那么从消费端入手
如果是线上突发问题,要临时扩容,增加消费端的数量,与此同时,降级一些非核心的业务。通过扩容和降级承担流量,这是为了表明你对应急问题的处理能力。
通过监控,日志等手段分析是否消费端的业务逻辑代码出现了问题,优化消费端的业务处理逻辑。
如果是消费端的处理能力不足,可以通过水平扩容来提供消费端的并发处理能力,但这里有一个考点需要特别注意, 那就是在扩容消费者的实例数的同时,必须同步扩容主题 Topic 的分区数量,确保消费者的实例数和分区数相等。如果消费者的实例数超过了分区数,由于分区是单线程消费,所以这样的扩容就没有效果。
比如在 Kafka 中,一个 Topic 可以配置多个 Partition(分区),数据会被写入到多个分区中,但在消费的时候,Kafka 约定一个分区只能被一个消费者消费,Topic 的分区数量决定了消费的能力,所以,可以通过增加分区来提高消费者的处理能力。
思维过程 比 解决方案 更重要

 浙公网安备 33010602011771号
浙公网安备 33010602011771号