


分布式锁
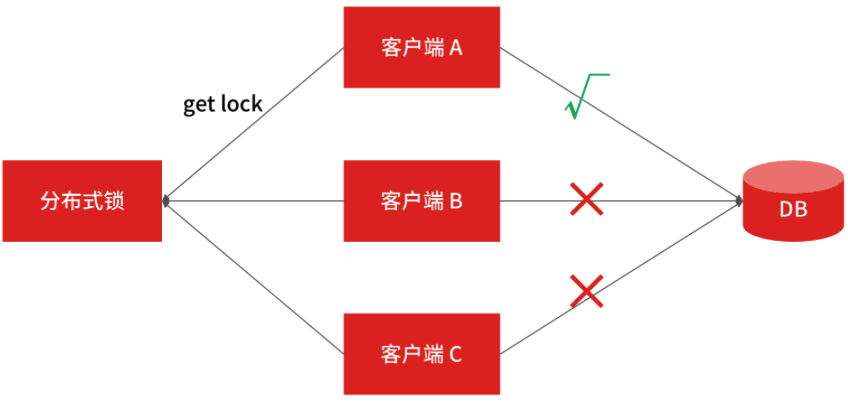
基于关系型数据库实现分布式锁
select id from order where order_id = xxx for update
基于 MySQL 行锁的方式会出现交叉死锁
数据库的事务隔离级别
- 读未提交(READ UNCOMMITTED);
- 读已提交(READ COMMITTED);
- 可重复读(REPEATABLE READ);
- 可串行化(SERIALIZABLE)
数据库隔离级别越高,系统的并发性能就越差
基于乐观锁的方式实现分布式锁
基于版本号的方式,首先在数据库增加一个 int 型字段 ver,然后在 SELECT 同时获取 ver 值,最后在 UPDATE 的时候检查 ver 值是否为与第 2 步或得到的版本值相同。
## SELECT 同时获取 ver 值
select amount, old_ver from order where order_id = xxx
## UPDATE 的时候检查 ver 值是否与第 2 步获取到的值相同
update order set ver = old_ver + 1, amount = yyy where order_id = xxx and ver = old_ver
基于分布式缓存实现分布式锁
618 和双 11 大促”等请求量剧增的场景,你要引入基于缓存的分布式锁,这个方案可以避免大量请求直接访问数据库,提高系统的响应能力。
基于缓存实现的分布式锁,就是将数据仅存放在系统的内存中,不写入磁盘,从而减少 I/O 读写
在加锁的过程中,实际上就是在给 Key 键设置一个值,为避免死锁,还要给 Key 键设置一个过期时间。
选用 Lua 脚本是为了保证解锁操作的原子性。因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
-
基于 Redis 实现分布式锁的优缺点
性能高效
实现方便
避免单点故障
由于 Redis 集群数据同步到各个节点时是异步的,如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 实例依次请求申请加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。
那 Redlock 算法是如何做到的呢?
当客户端完成了和所有 Redis 实例的加锁操作之后,如果有超过半数的 Redis 实例成功的获取到了锁,并且总耗时没有超过锁的有效时间,那么就是加锁成功。
对于分布式锁,你要从“解决可用性、死锁、脑裂”等问题为出发点来展开回答各分布式锁的实现方案的优缺点和适用场景。 另外,在设计分布式锁的时候,为了解决可用性、死锁、脑裂等问题,一般还会再考虑一下锁的四种设计原则。
-
互斥性:即在分布式系统环境下,对于某一共享资源,需要保证在同一时间只能一个线程或进程对该资源进行操作。
-
高可用:也就是可靠性,锁服务不能有单点风险,要保证分布式锁系统是集群的,并且某一台机器锁不能提供服务了,其他机器仍然可以提供锁服务。
-
锁释放:具备锁失效机制,防止死锁。即使出现进程在持有锁的期间崩溃或者解锁失败的情况,也能被动解锁,保证后续其他进程可以获得锁。
-
可重入:一个节点获取了锁之后,还可以再次获取整个锁资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号