


亿级商品存储
如何设计一个支持海量商品存储的高扩展性架构?
在互联网业务场景下,为了解决单台存储设备的局限性,会把数据分布到多台存储节点上,以此实现数据的水平扩展。既然要把数据分布到多个节点,就会存在数据分片的问题。
数据分片即按照一定的规则将数据路由到相应的存储节点中,从而降低单存储节点带来的读写压力。常见的实现方案有 Hash(哈希分片)与 Range(范围分片)。
明确了如何分片后,就需要对数据进行复制,数据复制会产生副本,而副本是分布式存储系统解决高可用的唯一手段,这也是我们熟知的主从模式,又叫 master-slave。在分布式存储系统中,通常会设置数据副本的主从节点,当主节点出现故障时,从节点可以替代主节点提供服务,从而保证业务正常运行。
如何让从节点替代主节点呢?这就涉及数据一致性的问题了
数据一致性,通常要考虑一致性强弱(即强一致性和最终一致性的问题)。而要解决一致性的问题,则要进行一系列的一致性协议:如两阶段提交协议(Two-Phrase Commit,2PC)、Paxos 协议选举、Raft 协议、Gossip 协议。
分布式数据存储的问题可以分成:数据分片、数据复制,以及数据一致性带来的相关问题
假设你是一家电商网站的架构师,现在要将原有单点上百 G 的商品做数据重构,存储到多个节点上,你会如何设计存储策略 ?
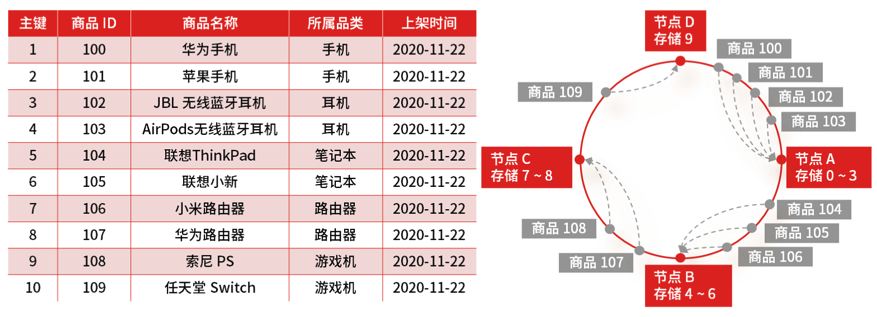
商品存储扩容的设计问题,很容易想到做数据的分库分表,也就是重新设计数据的分片规则,常用的分片策略有两种,即 Hash(哈希)分片和 Range(范围)分片
Hash 分片的优点在于可以保证数据非常均匀地分布到多个分片上,并且实现起来简单,但扩展性很差,因为分片的计算方式就是直接用节点取模,节点数量变动,就需要重新计算 Hash,就会导致大规模数据迁移的工作。
如何解决 Hash 分片的缺点,既保证数据均匀分布,又保证扩展性?
答案就是一致性 Hash :它是指将存储节点和数据都映射到一个首尾相连的哈希环上。存储节点一般可以根据 IP 地址进行 Hash 计算,数据的存储位置是从数据映射在环上的位置开始,依照顺时针方向所找到的第一个存储节点。
ETCD 是如何解决数据共识问题的?为什么要选择这种数据复制方式呢?
分布式系统中,造成系统不可用的场景很多,比如服务器硬件损坏、网络数据丢包等问题,解决这些问题的根本思路是多副本,副本是分布式系统解决高可用的唯一手段,也就是主从模式,那么如何在保证一致性的前提下,提高系统的可用性,Paxos 就被用来解决这样的问题
Paxos 又分为 Basic Paxos 和 Multi Paxos,然而因为它们的实现复杂,工业界很少直接采用 Paxos 算法,所以 ETCD 选择了 Raft 算法
Raft 是 Multi Paxos 的一种实现,是通过一切以领导者为准的方式,实现一系列值的共识,然而不是所有节点都能当选 Leader 领导者,Raft 算法对于 Leader 领导者的选举是有限制的,只有最全的日志节点才可以当选。正因为 ETCD 选择了 Raft,为工业界提供了可靠的工程参考,就有更多的工程实现选择基于 Raft,如 TiDB 就是基于 Raft 算法的优化。
要解决可用性的问题,根据 Base 理论,需要实现最终一致性,那么 Raft 算法就不适用了,因为 Raft 需要保证大多数节点正常运行后才能运行。这个时候,可以选择基于 Gossip 协议的实现方式。
Gossip 的协议原理有一种传播机制叫谣言传播,指的是当一个节点有了新数据后,这个节点就变成了活跃状态,并周期性地向其他节点发送新数据,直到所有的节点都存储了该条数据。这种方式达成的数据一致性是 “最终一致性”,即执行数据更新操作后,经过一定的时间,集群内各个节点所存储的数据最终会达成一致,很适合动态变化的分布式系统。
共识算法的选择和数据副本数量的多少息息相关,如果副本少、参与共识的节点少,推荐采用广播方式,如 Paxos、Raft 等协议。如果副本多、参与共识的节点多,那就更适合采用 Gossip 这种最终一致性协议。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号